
- Tech Insights 2025 Week 42

Things were so much easier just six months ago! In April 2025 the comparison between Microsoft 365 Copilot and ChatGPT was easy. Two fairly simple chatbots that both used the GPT-4o model as their foundation. Many companies picked Copilot, reading through the specifications the differences were few, and you also got additional benefits such as Teams meeting transcriptions.
Fast forward six months and OpenAI ChatGPT has now evolved from a simple chat service into a complete productivity platform. In May OpenAI launched Codex, which has grown into today’s best software development tool for agentic development even surpassing Claude Code. In August OpenAI introduced GPT5 with a special model “GPT5 Pro” only available to ChatGPT Pro subscribers, and now last week they introduced their Apps SDK and AgentKit with Agent Builder, allowing companies to launch apps directly to their ChatGPT users and allow users to define complex agentic workflows with a point-and-click interface.
Today the choice is much more difficult. The future of AI is not a chatbot you ask for help when you get stuck, the future are AI agents doing the bulk of your job so you can focus on the important things. The main challenge with this future for Microsoft is that they do not own the engines that drive this future: the AI models. As long as Microsoft do not use their own LLMs in Copilot the services they provide will always be lower quality than the offerings from OpenAI, Anthropic or Google who will reserve the best models and tools for their own products.
All together this makes the decision to choose an AI tool today much more difficult than just six months ago. You are not just picking a chatbot, you are investing in a platform your employees will use every hour every day.
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2025 Week 42 on Spotify
THIS WEEK’S NEWS:
- OpenAI DevDay 2025
- Samsung’s Tiny Recursion Model Outperforms Larger Models on Complex Reasoning
- Google Announces Gemini Enterprise Platform
- Google Launches Gemini 2.5 Computer Use Model
- Google Introduces CodeMender AI Agent for Automated Security Patching
- Google Research Launches Speech-to-Retrieval Voice Search
- Anthropic Introduces Plugin Support for Claude Code
- MIT, IBM, and University of Washington Release Open Dataset for Training AI Agents
OpenAI DevDay 2025
The News:
- OpenAI announced major platform updates at DevDay 2025 on October 6 in San Francisco, positioning ChatGPT as a comprehensive development platform with 800 million weekly active users, up 60% since March.
- GPT-5 Pro launched in the API at $15 per million input tokens and $120 per million output tokens, designed for tasks requiring high accuracy and deep reasoning in finance, legal, and healthcare applications.
- The company processes 8 billion tokens per minute through the API, with 4 million developers using the platform to code and build applications.
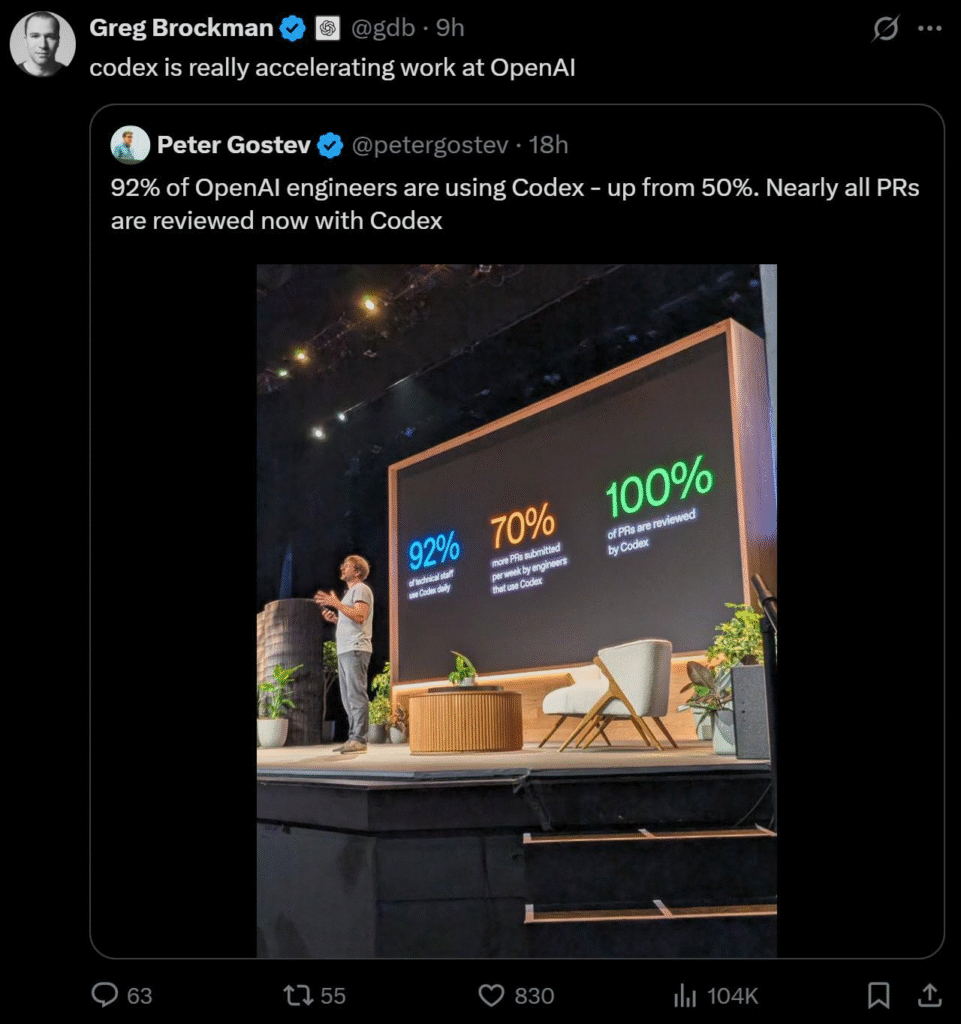
- Codex reached general availability after growing daily usage 10x since August. Nearly all OpenAI engineers use Codex internally, merging 70% more pull requests weekly, with the tool automatically reviewing almost every PR.
- New voice model gpt-realtime-mini launched at 70% lower cost than the previous advanced voice model while maintaining the same voice quality and expressiveness.
- AgentKit debuted as a complete toolkit including Agent Builder (visual canvas for multi-agent workflows), ChatKit (embeddable chat UI), and Connector Registry for managing data sources across ChatGPT and API.
- Apps SDK enables developers to build full-stack applications directly inside ChatGPT, with partners including Spotify, Zillow, Canva, and Figma.
- Sora 2 API became available in preview, allowing developers to integrate video generation into applications.
- OpenAI partnered with AMD for 6 gigawatts of Instinct GPU deployment starting with 1 gigawatt in 2026, with OpenAI receiving the option to purchase up to 10% of AMD stock.
My take: 800 million weekly users is a crazy figure, considering we have around 5.5 billion Internet users in total. OpenAI is on track to have over a billion active users at the end of 2025, which means 25% of the entire connected population on the planet use ChatGPT at least once a week. In comparison, neither Anthropic nor Microsoft publish any figures of how many users they have. Several reports indicate that the figures are way less than these figures, with figures as low as 8 million M365 Copilot users and 19 million weekly Claude users.
My main takeaway from this event is that it will be much more difficult for companies to lock themselves into just one provider, like M365 Copilot. ChatGPT is evolving from a simple chat tool to a tool that can run internal company apps (Apps SDK) and where users can define their own agentic workflows using drag-and-drop (AgentKit). It’s not just enough to say “Copilot is using the same GPT5-model” because soon that will just be a tiny bit of the entire offering. OpenAI Codex is another great example, Microsoft has nothing that even comes close to this for software development, and this is something every ChatGPT user gets for free. I am not saying every company should consider switching to ChatGPT, I am just saying that you are not just picking a chat tool, you are picking a productivity platform. And as is typical with productivity tools, one model does not fit everyone in your company.
Samsung’s Tiny Recursion Model Outperforms Larger Models on Complex Reasoning
https://arxiv.org/abs/2510.04871
The News:
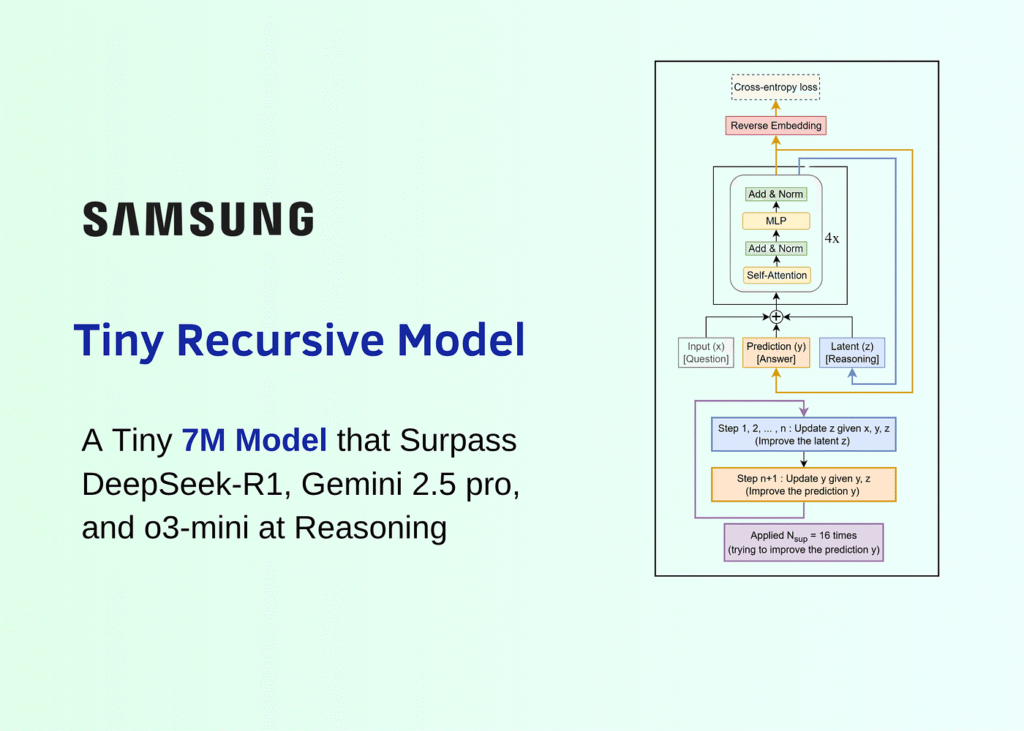
- Samsung researcher Alexia Jolicoeur-Martineau introduced the Tiny Recursion Model (TRM), a 7 million parameter AI that achieves higher scores than models 10,000 times larger on complex reasoning benchmarks.
- TRM scored 45% on ARC-AGI-1 and 8% on ARC-AGI-2, surpassing DeepSeek R1 (1.3%), Gemini 2.5 Pro (4.9%), o3-mini-high (3.0%), and Claude 3.7 (0.7%) on the ARC-AGI-2 benchmark.
- The model uses a recursive refinement process with up to 16 cycles, alternating between updating a latent reasoning state and revising the answer draft, rather than generating answers token by token.
- Each refinement cycle includes six internal updates to a separate scratchpad where the model critiques and improves its logic before updating the answer.
- TRM achieved 87.4% accuracy on Sudoku-Extreme puzzles (versus 55% for the previous HRM model) and 85.3% on Maze-Hard tasks (versus 74.5% for HRM).
- The code is available on GitHub under an MIT License.
My take: When something sounds too good to be true, it usually is. So, where do I begin. First, this Tiny Recursion Model (TRM) is specifically designed and trained for grid-based reasoning puzzles, not software engineering tasks. The paper only evaluates TRM on four types of benchmarks: ARC-AGI-1, ARC-AGI-2, Sudoku-Extreme, and Maze-Hard. And the TRM is also specifically fine-tuned for each benchmark. This is not a general-purpose model, it’s a model that’s fine tuned many times for each specific benchmark puzzle. I think this is an interesting approach, and maybe it will find use cases. But it could equally be that this approach will be completely forgotten in 1-2 years.
Google Announces Gemini Enterprise Platform
https://blog.google/products/google-cloud/gemini-at-work-2025

The News:
- Google launched Gemini Enterprise on October 8, 2025, a unified AI platform that combines Gemini models, agent orchestration, data integration, and governance into a single interface for workplace automation.
- The platform includes six core components: Gemini models, a no-code workbench for building multi-agent workflows, prebuilt agents for tasks like research and data analysis, secure connections to enterprise data across Google Workspace and Microsoft 365, central governance for auditing agents, and an ecosystem of 100,000+ partners.
- Gemini Enterprise integrates with business applications including Salesforce, SAP, Microsoft 365, and SharePoint, with new agents announced including a Data Science Agent for automating data wrangling and a Customer Engagement Suite powered by Gemini models supporting over 40 languages.
- The platform uses open standards including Model Context Protocol (MCP), Agent2Agent Protocol (A2A), and the newly announced Agent Payments Protocol (AP2) developed with American Express, Mastercard, PayPal, and Salesforce to enable secure agent transactions.
- Pricing starts at $21 per user per month for Business tier (up to 300 seats with basic agents), $30 per user per month for Enterprise Standard/Plus (unlimited seats with security and governance), plus a Frontline edition for lightweight access.
- Early customers include Banco BV, Harvey (legal AI), Commerzbank (handling 70% of inquiries via AI), Mercari (projecting 500% ROI), Figma, Klarna, Gordon Foods, Macquarie Bank, and Virgin Voyages with 50+ deployed agents.
My take: This is a direct competitor to OpenAI Agent Builder launched last week. Sam Altman described OpenAI Agent Builder “like Canva for building agents”, and now the new no-code workbench from Google allows “any user, from marketing to finance, to analyze information and orchestrate agents to automate processes”. The main difference is that Agent Builder is positioned more as a developer tool with API access, SDK integration, and code export, and Gemini Enterprise Workbench is explicitly marketed as no-code for “any user – from marketing to finance”. AI agents are the future, and platforms like this are excellent end-user complements to “real” agentic platforms like the Microsoft Agent Framework.
Google Launches Gemini 2.5 Computer Use Model
https://blog.google/technology/google-deepmind/gemini-computer-use-model

The News:
- Google released Gemini 2.5 Computer Use, a specialized model built on Gemini 2.5 Pro that controls web browsers and mobile applications by clicking, typing, and scrolling through graphical user interfaces.
- The model operates through a loop that accepts user requests, screenshots, and action history, then generates function calls representing UI actions such as clicks or typed text.
- The model requires user confirmation before executing high-risk actions including purchases, CAPTCHA solving, or accessing medical devices through a per-step safety service.
- On the Online-Mind2Web benchmark containing 300 tasks across 136 live websites, Gemini 2.5 Computer Use scored 69.0%, compared to Claude Sonnet 4.5’s 61.4% on the OSWorld benchmark.
- The model achieved 88.9% on WebVoyager and 69.7% on AndroidWorld, while maintaining lower latency than competing models according to Browserbase harness measurements.
- Developers access the model through the Gemini API in Google AI Studio and Vertex AI, with integration examples available for Playwright and Browserbase cloud VMs.
- Google teams deployed the model to production for UI testing in software development, and versions power Project Mariner, Firebase Testing Agent, and agentic features in AI Mode in Search.
My take: The response so far for Gemini 2.5 computer use has been quite negative, especially for complex web sites. I think most of these people are missing the point here with these kinds of computer use systems. Many large companies including banks rely on very old IT systems that won’t be replaced for years. You can try to automate as much as possible in the organization, but you are still stuck with people having to click around in hundreds of menu options in complex old systems. This is where I believe we will see the most use of LLM Computer Use in the coming years. Google is still launching tools around their now fairly old model Gemini 2.5 that was launched 7 months ago in March. A lot has happened since then, and I have high beliefs that Gemini 3.0 that is due launch later this year will show a massive leap in performance in most areas. Computer use through an LLM is still not good enough that it can pre-fill invoices and bill of materials in an old business system, but we are not that far away, and that could be a game changer for large companies with hundreds of “human robots” spending most of their time in these old systems.
Read more:
Google Introduces CodeMender AI Agent for Automated Security Patching
https://deepmind.google/discover/blog/introducing-codemender-an-ai-agent-for-code-security
The News:
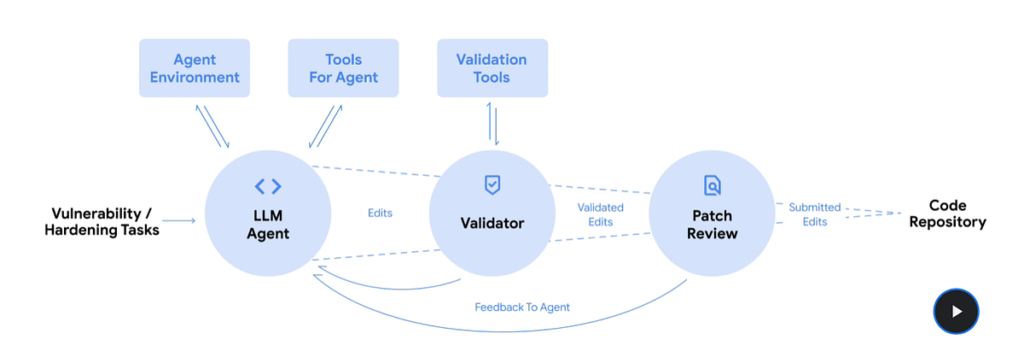
- CodeMender is an AI agent that detects and patches software vulnerabilities autonomously. The system has submitted 72 verified security fixes to open-source projects over six months, including codebases with over 4.5 million lines of code.
- The agent uses Gemini Deep Think models combined with static analysis, dynamic analysis, fuzzing, and symbolic solvers to identify root causes of vulnerabilities.
- CodeMender generates multiple candidate patches and validates them through automated testing before human review. The system checks for regressions and verifies that fixes address the underlying issue without breaking existing functionality.
- The agent operates in reactive and proactive modes. Reactive mode patches newly discovered vulnerabilities, while proactive mode rewrites code to eliminate entire vulnerability classes.
- Specific examples include repairing a heap-buffer overflow caused by XML stack handling errors and resolving object-lifetime bugs through non-trivial code modifications.
- CodeMender added safety annotations to the libwebp image library to prevent buffer overflow attacks, addressing vulnerability types similar to CVE-2023-4863, which enabled zero-click iOS attacks.
- Internal benchmarks report a 95% success rate in patching real-world vulnerabilities during testing.
My take: In my experience OpenAI Codex with the best model (GPT5-CODEX-HIGH) writes source code as good or even better than the best developers I have worked with. So it was just a matter of time before we got AI systems that are as good or better than the best developers in not only reactively fixing security issues but also proactively correcting them. I have worked full-time with agentic AI-based software development for over a year, but I am still quite stunned by the leap in performance today’s coding models have shown in the past few months. Sam Altman posted yesterday that “I am having a hard time imagining what creating software at the end of 2026 is going to look like” and I agree. My best guess right now is that we will have AI systems that write all our code, and we will have AI agents proactively fixing security leaks and doing continuous improvements. This can already be achieved today, but it’s still out of reach for enterprise customers (it requires personal Pro accounts). Once they release this on a large scale for enterprise companies you should see a shift in organizational structures quicker than anyone could have ever anticipated.
Google Research Launches Speech-to-Retrieval Voice Search
https://research.google/blog/speech-to-retrieval-s2r-a-new-approach-to-voice-search
The News:
- Google Research launched Speech-to-Retrieval (S2R), a voice search system that processes spoken queries directly without converting them to text first. S2R reduces errors from transcription mistakes that alter query meaning.
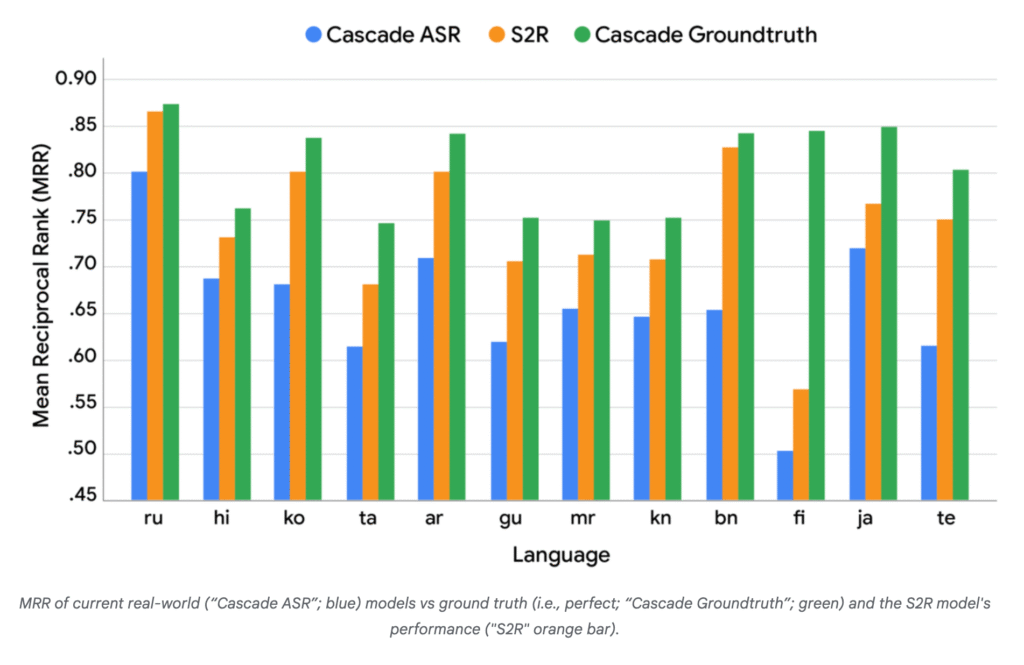
- The system uses dual-encoder architecture with separate neural networks for audio and document processing. Each encoder converts input into vector representations, trained so audio query vectors geometrically align with relevant document vectors in the representation space.
- S2R performance approaches the theoretical upper bound established by perfect transcription systems. Testing across multiple languages showed S2R significantly outperforms traditional ASR-based cascade models in mean reciprocal rank (MRR) metrics.
- Google open-sourced the Simple Voice Questions (SVQ) dataset, containing short audio questions in 17 languages and 26 locales as part of the Massive Sound Embedding Benchmark. The dataset enables researchers to evaluate speech-to-retrieval approaches.
- The system is live and serving users in multiple languages. Traditional cascade ASR systems introduce error propagation where early misinterpretation (such as “scream” heard as “screen”) produces irrelevant search results without correction mechanisms.
“Where today’s common voice search technologies are focused on the question, ‘What words were said?’, S2R is designed to answer a more powerful question: ‘What information is being sought?’”
My take: Well if you have ever tried any voice-to-text to trigger text-to-search you know how stupid the voice-to-text systems typically are in that they don’t know context or situation. They just translate word by word. Google Speech-to-retrieval (S2R) instead focuses on what it is you are looking for, and skips the automatic speech recognition (ASR) step. The actual results of using S2R (check the graph above) is very close to a “perfect” cascade model by sending the flawless ground-truth text directly to the same retrieval system. This is a huge step for voice controlled systems that will benefit everyone.
Anthropic Introduces Plugin Support for Claude Code
https://www.anthropic.com/news/claude-code-plugins
The News:
- Claude Code now supports plugins, packaging slash commands, sub-agents, MCP servers, and hooks into single-command installations that allow developers to customize coding workflows.
- Plugins install via the /plugin command in public beta. Developers toggle capabilities on and off to reduce system prompt context when specific features are not needed.
- Plugin marketplaces let anyone host and distribute plugin collections through GitHub repositories, Git repositories, or URLs containing a .claude-plugin/marketplace.json file.
- Sub-agents provide specialized AI assistance, like Lyra for prompt optimization. MCP servers connect to external tools such as Jira, Google Drive, or internal databases. Hooks customize Claude’s behavior at key workflow points, such as running tests after code generation.
- Community marketplaces already feature over 113 plugins across 10+ categories, including DevOps automation, documentation generation, and security audits. One marketplace contains 80+ specialized sub-agents.
My take: Claude Code plugins is a simple way for your company to distribute Claude Code customizations such as slash commands, sub-agents, MCP servers and hooks into a single package that can be downloaded by your employees. To get started you set up a marketplace in a github repo and users then add this repo to their Claude Code setup. This could have been a great launch if it wasn’t for one thing – there is no way to update plugins once installed. The only way to update plugins is for developers to uninstall and reinstall, and there is not even a notification system in place for plugin updates. I understand Anthropic wants to move fast, but sometimes I just wished they slowed down long enough to ask themselves if this new release is “ok” or “great”. I feel like with many of Anthropic’s recent decisions they have settled for “ok” as long as it’s quick.
MIT, IBM, and University of Washington Release Open Dataset for Training AI Agents
https://arxiv.org/abs/2510.01179

The News:
- TOUCAN is a publicly available dataset containing 1.5 million tool interaction trajectories, designed to train large language model agents to use external tools across 495 real Model Context Protocol servers with over 2,000 tools.
- The dataset uses actual tool execution in real environments rather than simulated responses, capturing errors, delays, and context dependencies that occur in production systems.
- Tools span multiple domains including web search, development platforms, finance, weather services, and AI applications, covering both single-tool and parallel multi-tool scenarios.
- The generation pipeline employed five language models to create tasks, applied quality filtering, and used three teacher models to generate trajectories with rule-based and model-based validation.
- Models fine-tuned on TOUCAN achieved state-of-the-art performance on the BFCL V3 benchmark, outperforming larger closed-source models in function calling accuracy across single-turn and multi-turn scenarios.
- On the MCP-Universe benchmark, TOUCAN-tuned models improved Qwen2.5-7B-Instruct by 3.16%, Qwen2.5-14B-Instruct by 7.40%, and Qwen2.5-32B-Instruct by 8.72%.
My take: So what should you use this for? Well if you use AI agents in your company today, you know that the larger a model is the more expensive it is. And at the same time the smaller a model is, the worse it is at function calling and tool use. Making tool calling work reliably is hard. TOUCAN’s value is teaching smaller, cheaper models (7B-32B parameters) to handle tool interactions the right way. This is a synthesized dataset, cheap and scalable. Creating 1.5 million human-labeled examples of tool interactions would have costed millions of dollars and have taken years. TOUCAN is a very welcome addition to any agentic toolchain, especially if you use smaller models.