
Should I require all my developers to start using AI? I often get that question. The answer is not a strict yes or no, but more “it depends”. If you are using a code base built on Go, Typescript, Rust or Python then the answer is always YES, go ahead, give Claude Code with Claude Max subscriptions to all your developers and you will see a productivity boost you didn’t think was possible. If you instead use .NET or JAVA, then the answer is more “it depends”, because you will be heavily dependent on the model. If you only use GitHub Copilot with GPT-4o then the answer is probably no, but if you can use Gemini 2.5 Pro the answer is yes. Having a 1 million context window really helps when using custom frameworks, and Gemini 2.5 Pro is the GOAT for .NET and JAVA. If you use C or C++ the answer is also most often no, the models are not that good at embedded software yet.
One company that do require all their developers to use AI is Canva. They just changed their job interview process, and now require developer candidates to use AI coding assistants during technical interviews for frontend, backend, and machine learning roles. I have used AI for code generation for a year now, and I still get better with it every month. It takes time to figure out a process that works for you, and preferably you have time do figure that out when you are not knee-deep in migration projects. Developers familiar with AI tools and know how to use them will be a key competitive advantage in the years to come.
Speaking of Anthropic, if you are curious in how they use Claude Code in their organization, don’t miss their paper “How Anthropic teams use Claude Code”. It’s mandatory reading if you are interested in increasing productivity with AI in your company.
Listen to Tech Insights on Spotify: Tech Insights 2025 Week 25 on Spotify
Thank you for being a Tech Insights subscriber!
THIS WEEK’S NEWS:
- OpenAI Launches o3-pro, Its Most Advanced Reasoning Model
- Mistral AI Launches Magistral Reasoning Models with Multilingual Capabilities
- Meta Releases V-JEPA 2 World Model for Robot Physical Reasoning
- ByteDance Releases Seedance 1.0 Video Generation Model, Tops Benchmarks Against Google and OpenAI
- ByteDance Researchers Release Seaweed APT2 for Real-Time Interactive Video Generation
- Canva Mandates AI Tool Usage in Developer Job Interviews
- Anthropic Shares How They Use Claude Code Internally
- Cursor Reveals Technical Architecture Behind 1M+ Queries Per Second
- Researcher Challenges Apple’s AI Study, Claims Experimental Flaws Behind “Reasoning Collapse”
- ChatGPT Voice Gets Major Speech and Translation Upgrades
- OpenAI Reaches $10 Billion Annual Revenue Milestone, Doubles Growth in Six Months
- Mattel and OpenAI Partner to Develop AI-Powered Toys and Games
- Google DeepMind Launches AI Weather Platform for Cyclone Prediction
- Google Releases Open-Source AI Research Agent Template Using Gemini 2.5 and LangGraph
- Microsoft Launches Copilot Vision with Screen-Reading Capabilities for Windows Users
- Disney and Universal Sue Midjourney for Copyright Infringement
OpenAI Launches o3-pro, Its Most Advanced Reasoning Model
https://help.openai.com/en/articles/9624314-model-release-notes
The News:
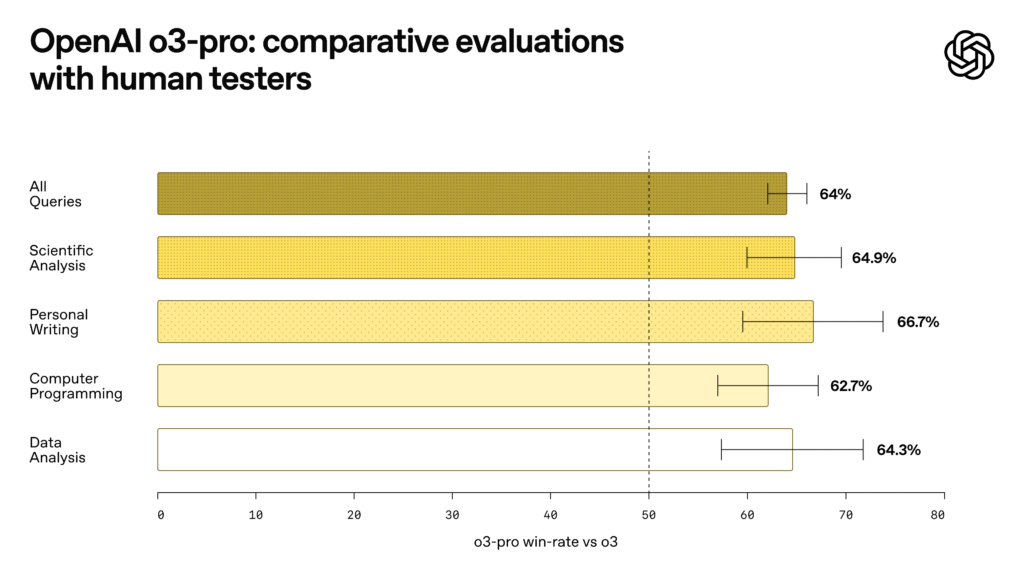
- OpenAI released o3-pro, replacing o1-pro as its most capable reasoning model designed to tackle complex problems in math, science, and coding by thinking longer before responding.
- The model achieved strong benchmark scores including 96.7% on AIME 2024 math competition and 87.7% on ARC-AGI reasoning benchmark, outperforming many human experts.
- o3-pro supports comprehensive tool integration including web search, file analysis, Python code execution, visual input processing, and memory-based personalization.
- ChatGPT Pro and Team users gained immediate access through the model picker, while Enterprise and Education users receive access the following week.
- API pricing is set at $20 per million input tokens and $80 per million output tokens, with responses typically taking several minutes to complete due to extended reasoning processes.
- Current limitations include disabled temporary chats due to technical issues, no image generation capability, and lack of Canvas workspace support.
My take: OpenAI o3-pro outperforms Gemini 2.5 on some tests like AIME 2024 (math skills), and Claude 4 Opus on GPQA Diamond (PhD-level science knowledge), and in expert evaluations reviewers consistently preferred the output from o3-pro over the base o3 model across all tested categories. But this is clearly a halo product, used to demonstrate to the world that OpenAI is still able to produce amazing products and that “we are so far away from when we start to level off”. It’s super expensive, and user reports on forums say it can take up to 6 minutes just to respond to a “Hi”. Myself I have been burning through over a billion tokens the past week with Claude 4 Opus with my Max subscription (I constantly hit the rate limit even with 20x rate limit). With the current O3 pro pricing that would have costed me a neat $80,000 if I had used o3-pro instead of Claude through the API for the same tasks. Add in that it seems to overcomplicate even simpler tasks when given insufficient context, and you have a model that’s pretty hard to use for anything practical. I’ll give this one a pass and go back to my near unlimited usage with Claude 4 Opus.
Read more:
- o3-Pro takes 6 minutes to answer “Hi” : r/OpenAI
- God is hungry for Context: First thoughts on o3 pro
Mistral AI Launches Magistral Reasoning Models with Multilingual Capabilities
https://mistral.ai/news/magistral
The News:
- Mistral AI released Magistral, its first reasoning models designed for transparent, step-by-step problem solving across multiple languages and industries.
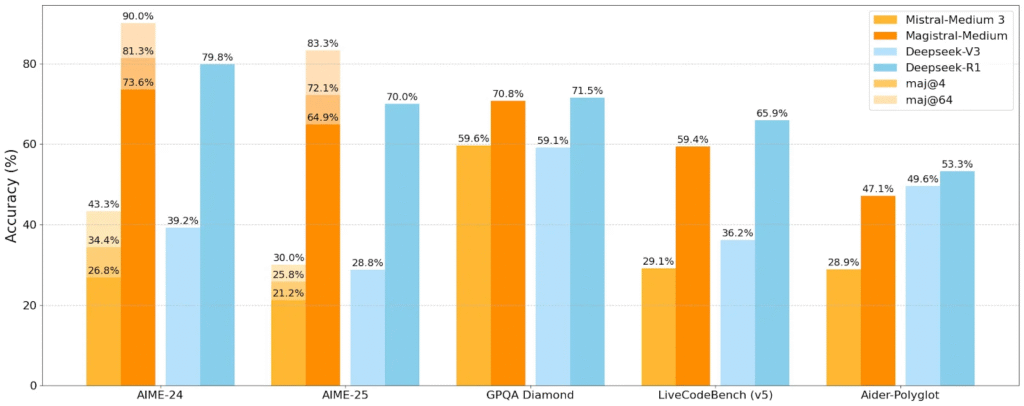
- The company offers two versions: Magistral Small (24 billion parameters, open-source) and Magistral Medium (enterprise version) with Apache 2.0 licensing for the smaller model.
- Magistral Medium achieved 73.6% on AIME2024 math benchmarks, rising to 90% with majority voting across 64 attempts, while Small scored 70.7% and 83.3% respectively.
- The models reason natively in eight languages including English, French, Spanish, German, Italian, Arabic, Russian, and Simplified Chinese without translating from English first.
- Mistral claims Flash Answers mode delivers responses up to 10 times faster than competitors through improved token throughput.
- Target applications include legal research, financial forecasting, software development, and regulated industries requiring traceable reasoning for compliance.
My take: When Google launched Gemma 3 27B it got lots of critique for being too large even for a 32GB 4090 graphics card (even running it 8-bit quantized still wouldn’t fit). Magistral Small 24B however runs perfectly on a 32GB graphics card when quantized to 8-bit, so I definitely see a market for this model. The performance of Magistral Medium is decent, still behind Deepseek-R1 on most benchmarks, but it clearly shows that Mistral has the capacity to deliver top-notch reasoning models, and it will be exciting to follow this European development going forward!

Read more:
Meta Releases V-JEPA 2 World Model for Robot Physical Reasoning
https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks

The News:
- Meta released V-JEPA 2, a 1.2 billion-parameter AI model that helps robots understand and predict physical interactions by learning from video data, enabling them to perform tasks in unfamiliar environments without extensive robot-specific training.
- The model trains on over 1 million hours of internet video and 1 million images in the first phase, then fine-tunes on just 62 hours of robot data to learn action-conditioned predictions.
- V-JEPA 2 achieves 65-80% success rates for pick-and-place tasks with novel objects in new environments, using model-predictive control to plan actions by simulating consequences in embedding space.
- The system works by encoding current and goal states from images, then using a predictor to evaluate candidate actions based on how close they get to desired outcomes, replanning at each step.
- Meta also released three new benchmarks for researchers to evaluate how well AI models understand physical dynamics from video, with humans scoring 85-95% accuracy compared to notable gaps in current AI performance.
My take: V-JEPA (Video Joint-Embedding Predictive Architecture) is built upon the JEPA architecture by Meta, which learns by making predictions in a learned representation space. In contrast to approaches that focus on learning entirely from interaction data, self-supervised learning enables V-JEPA to make use of Internet-scale video, depicting sequences of states without direct observations of the actions. The direct competitor for V-JEPA 2 is NVIDIA Cosmos, and where V-JEPA 2 only requires 16 seconds per action planning step, NVIDIA Cosmos takes up to 4 minutes. For grasping tasks, V-JEPA 2 achieved 60% success with cups compared to 0% for Cosmos, and 80% success for pick-and-place with cups versus 0% for Cosmos.
In their paper, the authors mention a few significant limitations before we get robots that can act autonomously. In the current implementation all cameras positioning must be manually adjusted, it’s limited to short actions due to lack of long-horizon planning, and current systems require visual goal images rather than natural language instructions. All these together makes this what the authors call “the feasibility of latent planning for robot manipulation” while clearly positioning it as early-stage progress rather than a breakthrough toward human-level capability. So don’t expect robots to replace humans within the next 12 months, but do expect them do be able to do it within a few years.
Read more:
- V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
- Literature Review – V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
ByteDance Releases Seedance 1.0 Video Generation Model, Tops Benchmarks Against Google and OpenAI
https://seed.bytedance.com/en/seedance

The News:
- ByteDance launched Seedance 1.0, an AI video generation model that creates 5-second videos at 1080p resolution from text prompts or images, ranking first on Artificial Analysis Video Arena for both text-to-video and image-to-video tasks.
- The model generates videos in 41.4 seconds on NVIDIA L20 hardware and costs approximately $0.50 per 5-second 1080p video through ByteDance’s Volcano Engine API.
- Seedance 1.0 supports multi-shot generation with consistent characters and themes across different camera angles, maintaining visual continuity between scenes.
- The system uses a Time Causal Variational Autoencoder and Decoupled Spatio-Temporal Diffusion Transformer architecture, achieving 10x faster inference through multi-stage distillation techniques.
- ByteDance trained the model on curated bilingual datasets with automated video captioning and employed reinforcement learning from human feedback using three reward models for foundational quality, motion, and aesthetics.
My take: Seedance 1.0 video generation model currently outperforms Google’s Veo 3, Kuaishou’s Kling 2.1, and OpenAI’s Sora on all public benchmarks, but it lacks the audio generation capabilities in Google Veo 3. The main strengths of this model are extremely good prompt adherence and motion quality compared to the competition, especially with complex camera movements and multi-subject scenarios. User feedback has so far been quite mixed, it seems that with the right prompt asking it to do things it has been well trained on it performs amazingly well. But ask it for something not well-represented in it’s training set and it shows lots of logical issues. It seems that it will be quite a while before we have just one video-generation model that can handle most use cases very well.
ByteDance Researchers Release Seaweed APT2 for Real-Time Interactive Video Generation

The News:
- ByteDance researchers introduced Seaweed APT2, an 8-billion-parameter model that generates streaming video content in real-time at 24fps, enabling interactive applications that previously required lengthy processing times.
- The model generates videos at 736×416 resolution on a single H100 GPU or 1280×720 resolution on 8 H100 GPUs, producing up to 1-minute videos (1440 frames) continuously.
- Each video frame requires only a single neural network forward evaluation (1NFE), significantly reducing computational overhead compared to traditional diffusion models that need multiple iterations.
- The system supports interactive controls including real-time pose manipulation for virtual humans and camera-controlled world exploration where users can navigate virtual environments.
- The model can generate videos up to 5 minutes long (7200 frames) in zero-shot fashion, though researchers note limitations in maintaining subject consistency and structural integrity over extended durations.
My take: It took me a while to understand the value of this. What is the purpose of a real-time AI video engine with very poor temporal memory, meaning if a person or object moves out of frame and then back in it will look different? The purpose is virtual humans. If you have time, go to their web page and scroll down to “Interactive Virtual Human Generation”. Only given an image, a prompt and the movement of another person as input, Seaweed APT2 is able to generate a complete interactive video of another person, performing the same movement, in real-time. Seaweed APT2 is an engine for live-streaming deep-fakes. You have already seen all the deep filters in Snapchat that replace your face with another with more makeup, well this will replace you completely, in real-time, in any environment.
Canva Mandates AI Tool Usage in Developer Job Interviews
https://www.canva.dev/blog/engineering/yes-you-can-use-ai-in-our-interviews

The News:
- Canva, the Australian graphic design platform serving 220 million monthly users, now requires developer candidates to use AI coding assistants during technical interviews for frontend, backend, and machine learning roles.
- The company replaced its traditional computer science fundamentals interviews, which previously banned AI assistance, with AI-integrated assessments using tools like Copilot, Cursor, and Claude.
- Nearly half of Canva’s engineers already use AI coding tools daily for prototyping, understanding codebases, and generating code, making the old interview format misaligned with actual job requirements.
- Candidates must solve complex engineering problems that “require genuine engineering judgment even with AI assistance” and cannot be solved with single prompts, testing their ability to guide AI effectively and refine generated code.
- The pilot program revealed that successful candidates used AI strategically for specific subtasks while maintaining overall solution control, rather than blindly accepting AI-generated outputs.
My take: This is something I expect most companies to adopt before the end of the year. Same with administrative jobs. If you are a professional developer and are not spending millions of tokens every week in Cursor, GitHub Copilot or Claude Code, then you are doing it wrong, and it’s time to change the way you are working. Used right AI will boost your productivity by huge amounts, doing routine work, tests, documentation, translations, and much more. It will be able to help you track down difficult issues by searching through framework dependencies, and find potential memory leaks analyzing your code in details. It’s not about using AI to mass produce code, it’s about becoming super productive and having the best time in your programming career.
Read more:
Anthropic Shares How They Use Claude Code Internally
https://www-cdn.anthropic.com/58284b19e702b49db9302d5b6f135ad8871e7658.pdf

The News:
- Anthropic published case studies showing how 10 internal teams use Claude Code, revealing that the AI coding assistant succeeds on first attempts only one-third of the time.
- Teams adopted a “slot machine” approach: commit code frequently, let Claude work autonomously, then either accept results or restart completely rather than iterating on failed attempts.
- The most effective teams write detailed Claude.md documentation files that provide context and break complex workflows into specialized sub-agents for better performance.
- Non-technical teams like legal and marketing now build custom tools with Claude Code, with the finance team using plain English requests like “Query this dashboard and generate an Excel report”.
- The data infrastructure team feeds screenshots of Kubernetes dashboards into Claude Code for debugging, allowing it to diagnose issues and suggest resolution commands.
- Product development teams use two modes: “auto-accept mode” for experimental features where Claude developed 70% of a Vim mode feature autonomously, and “synchronous mode” for business-critical development.
My take: This report was very good and gives a unique insight-look into how a company on the absolute forefront of technology are using their own tools to develop not only their own tools but also to drive their entire company. If you are interested in increasing efficiency with AI than this article is a must-read. The 33% first-attempt success rate matches my experience pretty well. I usually let Claude code iterate on its own code a few times, and after 3-4 passthroughs the quality of the generated code goes up significantly, especially when I give it feedback and steer it between each try. Using it right with proper instructions and iterative code reviews I would say the success rate of Claude code is well over 90%, and those remaining 10% are quite difficult tasks.
Cursor Reveals Technical Architecture Behind 1M+ Queries Per Second
https://newsletter.pragmaticengineer.com/p/cursor
The News:
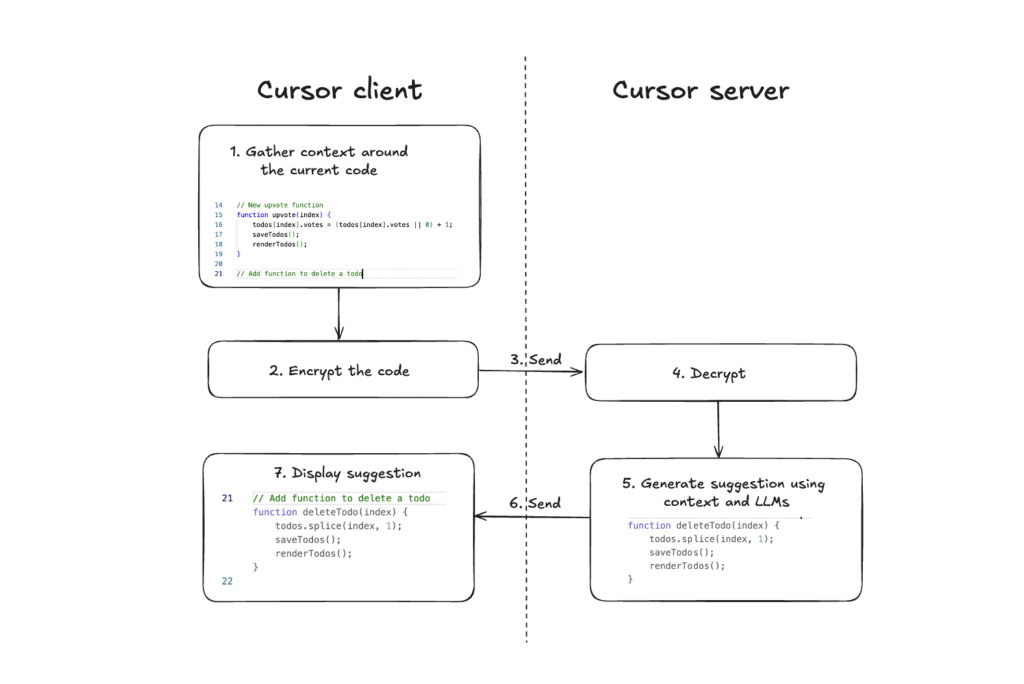
- Cursor, the AI-powered code editor, handles over 1 million queries per second while processing billions of daily code completions without storing user code on servers.
- The startup uses Merkle trees to create cryptographic hashes of codebases, enabling secure indexing by comparing client and server tree states every 3 minutes to identify changed files.
- Their tech stack combines TypeScript and Rust, with Anyrun serving as a Rust-based orchestrator that launches AI agents securely on Amazon EC2 using AWS Firecracker for process isolation.
- The team survived 100x growth in one year by performing emergency database migrations during outages, moving from Yugabyte to PostgreSQL, then to Turbopuffer within hours.
- Cursor’s autocomplete works through a low-latency sync engine that passes encrypted context to servers for inference, while chat functionality uses embeddings to search source code without server storage.
My take: One of the main differences between Cursor and GitHub Copilot is that Cursor has project-wide codebase understanding rather than file-level context. Even if GitHub Copilot now can work across multiple files, it’s still not as effective as Cursor which is built from the ground up for these kind of tasks. If you are interested in building large-scale near real-time infrastructures I highly recommend this article.
Researcher Challenges Apple’s AI Study, Claims Experimental Flaws Behind “Reasoning Collapse”
https://9to5mac.com/2025/06/13/new-paper-pushes-back-on-apples-llm-reasoning-collapse-study/

The News:
- Alex Lawsen from Open Philanthropy published “The Illusion of the Illusion of Thinking” on June 13, 2025, co-authored with Claude Opus (!), directly challenging Apple’s conclusions about Large Reasoning Model failures.
- Lawsen argues Apple’s study confused practical output constraints with actual reasoning failures, identifying three critical experimental design flaws in the original research.
- The rebuttal demonstrates that models like Claude were hitting token output limits when Apple claimed they “collapsed” on Tower of Hanoi puzzles with 8+ disks, with models explicitly stating “The pattern continues, but I’ll stop here to save tokens”.
- Apple’s River Crossing test included mathematically unsolvable puzzle instances with 6+ actors and insufficient boat capacity, yet penalized models for correctly recognizing these constraints and refusing to attempt solutions.
- Lawsen’s team reformulated tasks to allow compressed, programmatic answers instead of requiring complete move lists, which eliminated the performance collapse and showed models could generate correct solution strategies.
My take: Some of the things Apple did in their paper was actually trying to push LLMs to fail, such as (1) models hit their token output limits and still scored as failures, (2) Apple’s test set includes mathematically impossible River Crossing puzzles for N≥6, penalizing models for correctly recognizing unsolvable problem, (3) when asked to generate code instead of exhaustive move lists, models successfully solve puzzles they previously “failed”, and (4) Apple’s evaluation framework cannot distinguish between reasoning inability and practical output constraints. Lawsen did however not address the main issue with Apple’s broader finding of systematic reasoning limitations across multiple puzzle types and models suggests there are genuine constraints in current LRM capabilities beyond just token limits. Maybe if Apple had focused on just that issue the response from their article would have been better, and also the Apple article was not peer-reviewed, so it’s actually unclear if it would even pass a peer-review with these issues.
Read more:
- The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity – Apple Machine Learning Research
- Arxiv: The Illusion of the Illusion of Thinking A Comment on Shojaee et al. (2025)
ChatGPT Voice Gets Major Speech and Translation Upgrades

The News:
- OpenAI upgraded ChatGPT’s Advanced Voice Mode for paid subscribers, adding more natural speech patterns and real-time language translation capabilities that work continuously during conversations.
- The voice assistant now uses subtler intonation, realistic cadence, and emotional inflection including sarcasm and empathy, addressing previous complaints about robotic-sounding responses.
- Users can now ask ChatGPT to translate between languages on the fly, with automatic continuation until told to stop. For example, speaking English while traveling in Brazil gets translated to Portuguese, with the waiter’s Portuguese response translated back to English.
- The feature is available now to all ChatGPT Plus and Pro users across all platforms by tapping the microphone icon in the message composer.
My take: This exact feature, to be able to translate between languages on the fly, is something I use a lot. I have previously used Google Translate for it, but found it quite slow and the voice quality lacking. The new “interpreter mode” of ChatGPT is exactly what I have been looking for, and the other improvements to voice mode is just icing on the cake. With voice assistants like these, it was quite sad to see the Apple WWDC last week. Yes we got the new liquid glass interface, but I would personally gladly have skipped the glass interface if it meant that Apple could have spent more time improving Siri.
OpenAI Reaches $10 Billion Annual Revenue Milestone, Doubles Growth in Six Months

The News:
- OpenAI achieved $10 billion in annual recurring revenue (ARR) less than three years after launching ChatGPT, representing a near doubling from $5.5 billion at the end of 2024.
- The company now serves 500 million weekly active users and has grown its paying business customer base to 3 million, up from 2 million in February 2025.
- Revenue excludes licensing income from Microsoft and large one-time contracts, focusing on subscription-based services for consumers and businesses.
- OpenAI targets $125 billion in revenue by 2029, though the company recorded $5 billion in losses last year due to heavy investments in development and infrastructure.
- The company completed a $40 billion funding round in March 2025, the largest private technology deal in history, valuing OpenAI at approximately 30 times its revenue.
My take: It won’t be long until OpenAI pass 1 billion weekly active users, which means that basically everyone on the planet with Internet connection is using AI on a weekly basis, considering people also use LLMs from Anthropic, Google, Meta, Microsoft and all the others. The world is changing, and even if you think today’s models are not as good as the best writers, the best actors, the best artists, or the best coders, they will be quite soon. And for most of us today’s models are good enough for a huge amount of taks, we just need to learn how to control them and use them.
Mattel and OpenAI Partner to Develop AI-Powered Toys and Games
https://corporate.mattel.com/news/mattel-and-openai-announce-strategic-collaboration

The News:
- Mattel announced a strategic partnership with OpenAI to integrate generative AI into toys like Barbie, Hot Wheels, American Girl, and UNO, aiming to create more interactive play experiences for children.
- The collaboration will use OpenAI’s ChatGPT Enterprise technology to enable toys that can hold conversations, tell stories, and respond to children’s questions in natural language.
- Mattel plans to launch its first AI-powered product later in 2025, with examples potentially including interactive UNO games or Magic 8 Ball toys that use AI for enhanced engagement.
- The company emphasized that all AI features will prioritize child safety, privacy, and age-appropriate content, with Mattel retaining full control over product development.
- Beyond toys, Mattel will integrate OpenAI’s business tools into its operations for product development, creative ideation, and content creation.
My take: Maybe you haven’t been following Barbie the past decades, but between 2012 and 2015 global sales went down rapidly, and Mattel had to figure out what their unique selling proposition could be for Barbie to change the trajectory (without making Barbie unrecognizable). The answer came in the new Fashionistas line, launched in 2016, where they evolved the doll’s physical appearance and began exploring various female role models. Sales exploded, and Barbies of today come in five body types, 22 skin tones, 76 hair styles and 94 hair colors. Recent years sales have been steadily going down again, so it’s time for something new again. And this time something new is an AI powered doll. Now your kids will say hello to Barbie when they come home from school, Barbie will ask they about their day, and Barbie will also remember what happened yesterday. Barbie will ask about your children’s friends, and help out with their homework. This has the potential of a new kind of toy we have not even imagined, and the personal attachment it could have to kids growing up in the coming years would be unbelievably strong.
Read more:
- Mattel & OpenAI: Revolutionizing Smart Toys and Interactive Play – Maziply Toys
- Barbie’s sales are booming. Has the doll shed her controversial past?
Google DeepMind Launches AI Weather Platform for Cyclone Prediction
https://deepmind.google/discover/blog/weather-lab-cyclone-predictions-with-ai

The News:
- Google DeepMind launched Weather Lab, an interactive website that provides AI-powered tropical cyclone predictions to help weather agencies and emergency services forecast storm paths and intensity more accurately.
- The platform generates 50 possible storm scenarios up to 15 days in advance, predicting formation, track, intensity, size, and shape simultaneously.
- Google’s AI model produces 15-day predictions in approximately one minute on a single computer chip, compared to hours required by traditional physics-based models.
- Testing showed the AI model’s 5-day cyclone track predictions averaged 140 kilometers closer to actual storm locations than ENS, the leading European physics-based model, matching the accuracy of traditional 3.5-day forecasts.
- The National Hurricane Center is testing the AI predictions in real-time to enhance official warnings for the 2025 Atlantic hurricane season-
My take: Traditional physics-based models from the European Centre for Medium-Range Weather Forecasts are typically good at either tracking storm paths, or intensity, but not both. Google’s cyclone model does both, and also outperformed NOAA’s Hurricane Analysis and Forecast System (HAFS) on intensity prediction, an area where AI models typically struggle. To achieve this the new cyclone model was trained on over 45 years of cyclone data covering nearly 5,000 storm observations, way more than any other model has been trained on previously. This could be a game changer when we move into hurricane season in the fall.
Google Releases Open-Source AI Research Agent Template Using Gemini 2.5 and LangGraph
https://github.com/google-gemini/gemini-fullstack-langgraph-quickstart

The News:
- Google released the “Gemini Fullstack LangGraph Quickstart”, an open-source template that combines React frontend with LangGraph backend to build AI agents capable of comprehensive web research. The system helps developers create research tools that can iteratively search and verify information before providing answers.
- The agent uses Google’s Gemini 2.5 models to generate search queries and analyze results through the Google Search API. When initial searches reveal knowledge gaps, the system automatically generates follow-up queries and repeats the research process up to five configurable cycles.
- The architecture includes reflection capabilities where the AI evaluates whether gathered information sufficiently answers the user’s question. If gaps exist, it formulates new search terms and continues researching until confident in its response.
- All final answers include direct citations from web sources, and the system uses Redis Pub/Sub to stream results in real-time without blocking the user interface. The template supports hot-reloading for development and includes Docker configurations for production deployment.
My take: If you want to get started quickly with Google Gemini and LangGraph maybe this is something you might want to try out. However with today’s AI code generators like Cursor and Claude 4 Opus, creating something like this for your specific project is probably not more than a few hours of work. I guess the main question is if you want to use Google Search or not for your agent. ChatGPT uses Bing, and Claude uses Brave, and if you are fine with those search engines than this is not what you are looking for. On the other hand if you are fine with using Gemini and want your agent to use Google Search, this might be just what you were looking for to start your next agentic project.
Microsoft Launches Copilot Vision with Screen-Reading Capabilities for Windows Users
The News:
- Microsoft released Copilot Vision on Windows 10 and 11 in the U.S., enabling the AI assistant to analyze what users see on their screens and provide real-time guidance.
- Users can share up to two apps or browser windows simultaneously, allowing Copilot to connect information across applications and offer contextual assistance.
- The new Highlights feature responds to “show me how” requests by visually highlighting specific buttons, menus, or text fields within applications.
- Copilot Vision can suggest photo editing adjustments, explain spreadsheet formulas, review travel itineraries against packing lists, and guide users through unfamiliar Windows settings.
- The feature works with Microsoft Edge for free, while extending functionality to other applications requires a $20 monthly Copilot Pro subscription.
- Microsoft emphasizes privacy protections: only Copilot’s responses are logged, user inputs and screen content are not stored, and data is deleted when sessions end.
My take: We are clearly moving into a future where AI is soon able to control your entire PC. Reading information from the screen is however not the most optimal way to do it, and this is why Microsoft is also integrating MCP into Windows 11 so models like ChatGPT and Claude can get direct access to your programs and data. Today’s state-of-the-art models like o3 and Claude 4 are built from the ground up for agentic workflows, but they are not trained specifically for controlling desktop operating systems. I believe that is what next year’s models will shine at, and making Copilot Vision available now allows Microsoft to get a feeling for use cases and financial models for it this year already.
Disney and Universal Sue Midjourney for Copyright Infringement
The News:
- Disney, Universal, Marvel, and Lucasfilm filed a federal lawsuit against AI image generator Midjourney, marking Hollywood’s first major legal action against AI companies.
- The studios claim Midjourney trained its AI models on “countless” copyrighted images without permission, creating what they call a “bottomless pit of plagiarism”.
- The 110-page complaint includes side-by-side comparisons showing Midjourney-generated images of iconic characters including Darth Vader, Elsa from Frozen, Yoda, Spider-Man, Iron Man, Shrek, and the Minions.
- Midjourney generated $300 million in revenue last year and plans to launch a video generation service, which concerns studios about expanded copyright violations.
- Disney’s chief legal officer stated: “Piracy is piracy, and the fact that an AI company does it does not make it any less infringing”.
My take: Midjourney was among the first text to image models that could produce something that sometimes looked very lifelike. It has been surpassed by other image generators the past year, such as FLUX.1 Kontext and ChatGPT. Midjourney 7 launched in April was met with fairly mixed reactions. While technically better than their previous models, it still struggles with basic things such as rendering hands accurately. With this lawsuit the future of Midjourney looks quite dark.