
Mico. This is one of the best names I have heard in a long time coming from Microsoft. After a series of mediocre names like Zune, Bing and Cortana, Mico, the name of the new Copilot avatar, is just brilliant. It’s cute, it has a connection with both “Mi”crosoft and “Co”pilot and the visual avatar looks friendly, playful and I think people will love it. Mico is just one of 12 AI updates from Microsoft the past week – they are really going all-in on AI and they are integrating AI everywhere in their ecosystem. And as the foundation models continue to increase in performance in the coming year, so will the AI services that use them continue to grow in value. Satya Nadella is also all-in on AI, and in an Instagram video posted this Friday he explains that the top new feature of Copilot that’s a daily habit for him is being able to say “Hey Copilot” to his Windows laptop. “It’s probably the most exciting new modality since touch that’s been introduced”.
On the Mac side, OpenAI just bought the company behind the MacOS app Sky, which can be described as the “Mac equivalent” of “Hey Copilot”. I think this is another missed opportunity for Apple, but maybe they didn’t want to buy a company twice from the same people (the founders of Sky are the same people who created the Workflows app that was acquired by Apple in 2017 and later renamed into Shortcuts). Things are progressing at such an incredible pace right now, that having to wait until June 2026 for Apple to announce their next AI innovations at WWDC 26 feels almost like an eternity.
That said. I am not sure myself which approach I think will be the best long-term. Integrating AI assistants into every single computer experience like Microsoft does, or having it subtly integrated and leaving the assistant interaction to third party companies like Apple does. I know that I like having control over which AI I use on my computer, so the Microsoft way of including Copilot assistants all over the operating system is probably not for me. Which way do you prefer? Do you like the idea of having Copilot assistants everywhere watching everything you do, or would you like the freedom to install any third party app you want without being locked into one integrated AI assistant?
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2025 Week 44 on Spotify
THIS WEEK’S NEWS:
- Microsoft Copilot Fall Release
- OpenAI Launches Atlas Browser and Company Knowledge
- OpenAI Acquires Software Applications Incorporated, Maker of Sky
- Google AI Studio Introduces Updated Build Mode for Vibe Coding
- Google Launches Skills Platform With 3,000 AI and Cloud Courses
- Google Adds Maps Grounding and Earth AI to Gemini API
- Lovable Launches Shopify Integration
- Anthropic Launches Claude Code on the Web
- Lightricks Launches LTX-2 Open-Source AI Video Model
- DeepSeek AI launches DeepSeek-OCR
- Tencent Releases WorldMirror, Open-Source 3D Reconstruction Model
- Runway Launches Three New Features for Custom AI Workflows
Microsoft Copilot Fall Release
https://www.microsoft.com/en-us/microsoft-copilot/blog/2025/10/23/human-centered-ai/
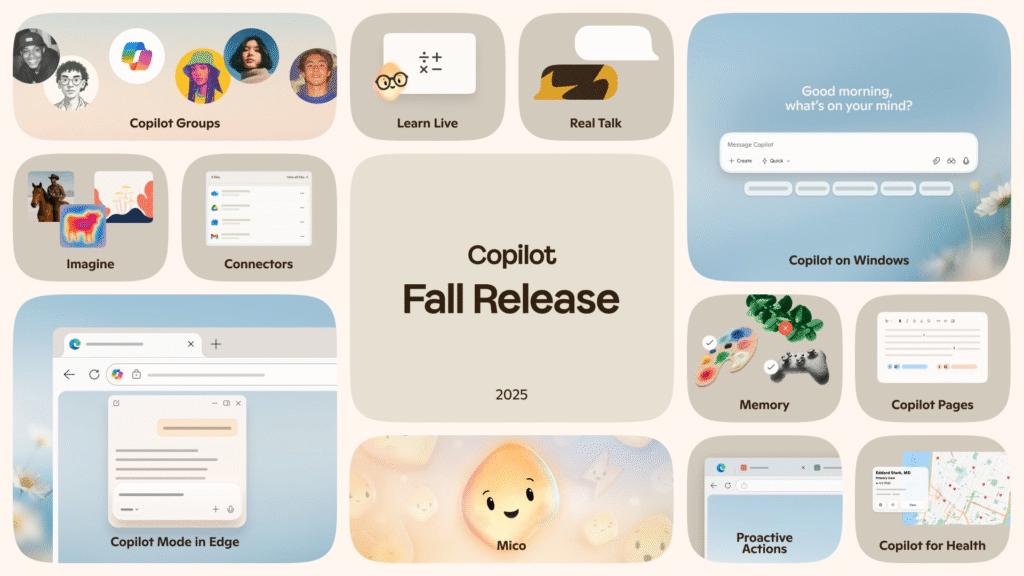
The News:
- Microsoft released 12 updates to Copilot last week, adding collaboration features, long-term memory, and health tools.
- Groups supports real-time collaboration with up to 32 participants for brainstorming, co-authoring, and planning, with Copilot maintaining context and tracking actions.
- Imagine provides a creative hub for generating and remixing AI-driven content, including visuals, marketing drafts, and training materials.
- Mico serves as an animated avatar that provides expressive feedback during voice interactions and changes colors based on emotional responses.
- Real Talk mode adapts to users’ communication styles and provides constructive pushback, functioning as a Socratic problem-solving tool.
- Memory & Personalization allows Copilot to remember information like training plans, important dates, and goals at the user’s request.
- Connectors integrate OneDrive, Gmail, and Google Calendar for natural-language searches across accounts, with explicit consent required for all connections.
- Proactive Actions provides contextual prompts and suggestions for next steps based on recent activities.
- Copilot for Health provides medical information from sources like Harvard Health and includes tools to find and compare doctors.
- Learn Live offers voice-enabled Socratic tutoring that uses questions, visual cues, and interactive whiteboards.
- Copilot Mode in Edge transforms Microsoft Edge into an AI browser where Copilot can see and reason over open tabs, summarize and compare information, and take Actions like booking hotels or filling out forms.
- Copilot on Windows integrates with Windows 11 PCs, featuring “Hey Copilot” activation and rapid access to files and applications.
- Copilot Pages and Copilot Search merges a collaborative file canvas with a unified search experience that combines AI-generated, cited responses with standard web results.
My take: So, Clippy is back! “We here from our users that sometimes, text just isn’t enough. Copilot is where people come to offload stress, to process their day, maybe practice for an upcoming interview, and we heard that, you know, Copilot is able to show up with a friendly face and just to be able to respond and listen, it makes them feel much more supported and heard”, from Microsoft Copilot Sessions: Fall Update at YouTube.
But wow what a list of AI updates from Microsoft, they are really going all-in on AI services here. Lots of features in here that have been missing from Copilot for a while. Memory is something we have had in ChatGPT for quite some time. And “Groups” is Microsoft’s version of Claude and ChatGPT “Projects”. Windows 11 had a version of Copilot previously, but then it was primarily used for settings and finding things in menus. Now it’s the full Copilot chat built-into Windows 11, including the wake up “Hey Copilot” command. The way Microsoft is integrating AI into every single product they own, it’s no longer a question on if rather than when they will replace OpenAI and Claude with their own in-house LLMs. My guess is that they will do this as quickly as possible, even if their models are slightly behind in performance. Right now MAI-1 is very much behind the competition, but let’s say they catch up somewhat in spring 2026. Then I wouldn’t be surprised to see a shift from GPT5.x and Claude 4.x into MAI-X in late 2026 powering all Microsoft’s AI services.
Read more:
OpenAI Launches Atlas Browser and Company Knowledge
https://openai.com/index/introducing-chatgpt-atlas/
https://openai.com/index/introducing-company-knowledge/

The News:
- ChatGPT Atlas is a Chromium-based web browser with ChatGPT integration, released October 21, 2025 for macOS users, including Free tier subscribers. Windows, iOS, and Android versions are planned.
- The browser includes an “Ask ChatGPT” sidebar that provides page summaries, product comparisons, and content analysis without requiring users to switch tabs or copy content. Users can ask questions like “Re-open the shoes I looked at yesterday”.
- Browser memories track visited websites and store key details to personalize responses, such as creating to-do lists from recent activity or suggesting holiday gifts based on browsing history. This feature is optional and can be disabled.
- Agent mode allows ChatGPT to complete web-based tasks like adding recipe ingredients to grocery carts, filling out forms, and compiling research from multiple documents. The feature is available in preview for Plus, Pro, and Business users.
- Company knowledge connects ChatGPT to enterprise tools including Slack, SharePoint, Google Drive, and GitHub, providing answers with citations. Powered by a version of GPT-5, it searches multiple sources and resolves conflicting information.
- Company knowledge respects existing user permissions, ensuring ChatGPT only accesses data each user is authorized to view. Available for Business, Enterprise, and Edu plans.
- OpenAI does not train models on browsed content by default, though users can opt in to training via data control settings. Browser memories and chat content from Atlas follow the same training opt-in rules.
My take: As a web browser, Atlas is a quite a rough experience. It is built upon Google Chromium, but lacks most of the sophistication that Google Chrome has that makes it a great web browser. Design-wise it feels like a weird mixture between Safari and Chrome, where some UX elements behaves more like Safari (like favorite menus) and some more like Chrome (like tabs). Some design decisions I don’t understand at all, like hiding the URL field so it does not look like a field at all, both Safari and Chrome are very clear where the main input field is.
Most of us still browse the web a lot on a daily basis, and having ChatGPT always available ready to review text, reorder items and give advice is probably something many people will appreciate. I’m not sure Atlas will make people change web browsers though, and I think Google has lots of things cooking in preparation for the Gemini 3.0 launch later this year. If OpenAI made it feel exactly like Chrome or Safari then most users would have a much easier time switching, now it looks and feels like something completely different.
OpenAI Acquires Software Applications Incorporated, Maker of Sky
https://openai.com/index/openai-acquires-software-applications-incorporated

The News:
- OpenAI acquired Software Applications Incorporated, the maker of Sky, a natural language interface for macOS that understands screen content and executes actions across applications.
- The 12-person team, including co-founders Ari Weinstein, Conrad Kramer, and Kim Beverett, will join OpenAI to integrate Sky’s macOS capabilities into ChatGPT.
- Weinstein and Kramer previously founded Workflow, which Apple acquired in 2017 and transformed into the Shortcuts app.
- Sky operates as a floating overlay using macOS accessibility APIs to recognize on-screen elements, summarize text, automate workflows, and control applications through natural language commands.
- The acquisition was led by Nick Turley and Fidji Simo and approved by OpenAI’s independent Transaction and Audit Committees, with Sam Altman’s investment fund holding a passive stake in Software Applications Incorporated.
My take: I think this is a missed opportunity for Apple, but hey congratulations to OpenAI on the purchase. Two weeks ago Microsoft launched Copilot Vision for Windows with features like full desktop and app sharing and highlights. Microsoft does not have something similar for MacOS, so you can see where this is heading. Microsoft is pushing Copilot as the premier choice for Windows 11 users, and OpenAI is pushing ChatGPT as the premier choice for MacOS users. As these AI platforms continue to grow in 2026, if you are the one deciding which tools your company is providing to your employees you really need to keep an eye on how these evolve in the coming months. Having an AI always available with whatever you are doing at your computer will be a game changer if it’s done right – both Microsoft and OpenAI knows this.
Read more:
Google AI Studio Introduces Updated Build Mode for Vibe Coding
https://aistudio.google.com/apps
The News:
- Google AI Studio launched an updated Build Mode that converts natural language prompts into working web applications with automatic Gemini API integration. The tool runs on Gemini 2.5 Pro and remains free without requiring payment details for basic use, though advanced features like Cloud Run deployment require a paid API key.
- Build Mode automatically selects and wires together AI capabilities including image generation (Imagine), video processing (Veo 3.1), lightweight AI models, and Google Search based on project requirements.
- The platform added GitHub integration that creates dedicated repositories for each project, generates automatic commit messages, and syncs code directly from the interface without requiring users to leave AI Studio.
- Framework support expanded to include both React and Angular (TypeScript), with Angular integration reflecting Google’s internal use of the platform.
- The interface redesign introduced a split-tab layout with full-screen code editor and preview sections, pre-built templates, and context-sensitive feature recommendations powered by Gemini’s analysis of current applications.
My take: Google AI Studio is still centered around Gemini 2.5, and as everyone who is working with software development knows that model is not the best choice for agentic development. Still they manage to get it to produce fairly good results. Once Google launches Gemini 3.0 and if it’s as good as most people believe it will be, then Google AI Studio will be a huge threat to services like Lovable. It’s free, it supports both React and Angular (Lovable focuses on React), can integrate with Google Cloud and supports both automatic repository creation and commit message generation. The only thing they don’t have right now is something like Claude 4.5 Sonnet or GPT5-CODEX, but once they have a model that is up to par with that this could be THE Vibe coding platform in 2026.
Read more:
Google Launches Skills Platform With 3,000 AI and Cloud Courses
https://blog.google/outreach-initiatives/education/google-skills
The News:
- Google launched Google Skills, consolidating nearly 3,000 courses, labs, and credentials from Google Cloud, DeepMind, Grow with Google, and Google for Education into one platform. The platform addresses AI expertise demand by centralizing training that previously generated 26 million completions across separate programs in the past year.
- Content spans entry-level Google AI Essentials courses through advanced certifications and Google DeepMind’s AI Research Foundations for large language model training. Time-constrained learners can access 10-minute AI Boost Bites modules.
- Hands-on labs use Gemini Code Assist, allowing direct coding practice with AI assistance. Learners earn skill badges, entry-level certificates, and certifications upon completion.
- The platform includes gamification features with streak tracking and shareable achievements, with 95 percent of learners reporting higher engagement with gamified experiences.
- Google Cloud customers receive full access to the on-demand library at no cost, while developers get 35 free monthly credits. Extensive free options include the Generative AI Leader learning path and hundreds of beginner courses requiring no prior experience.
My take: Looking just at the figures, Google Skills joins a market dominated by LinkedIn Learning, Udemy and Coursera. The main difference here is of course the quality of the content. If you’re a Google Cloud customer you get free access, and all developers get free credits. This could very well be the top AI educational resource in 2026.
Google Adds Maps Grounding and Earth AI to Gemini API
https://blog.google/technology/developers/grounding-google-maps-gemini-api/
https://blog.google/technology/research/new-updates-and-more-access-to-google-earth-ai/

The News:
- Gemini API now supports Grounding with Google Maps, connecting Gemini models with data from over 250 million places to build location-aware applications.
- The tool detects geographical context in queries and retrieves structured data including place names, addresses, business hours, user ratings, photos, and accessibility details from Google Maps.
- Developers receive a context token that renders an interactive Maps widget alongside text responses, providing visual interaction without requiring users to parse location descriptions.
- Grounding with Google Maps can be combined with Grounding with Google Search in the same request. Maps provides structured factual data while Search adds dynamic content like event schedules and recent news.
- Geospatial Reasoning is a new framework that uses Gemini to automatically connect multiple Earth AI models, including weather forecasts, population maps, and satellite imagery, to answer complex questions.
- New Earth AI models in Google Earth let users find objects and discover patterns in satellite imagery through natural language queries, such as identifying dried river beds or locating harmful algae blooms.
- The nonprofit GiveDirectly uses Geospatial Reasoning to combine flood and population density data to identify communities needing direct disaster aid.
My take: You can see Grounding with Google Maps as an AI front-end to Google Maps, where developers can send requests to Gemini and it will automatically and smartly query Google Maps to give you the best results. You could achieve similar results previously of course by using another LLM and then query Google Maps separately and then merge the results. But the main advantage here is that this version of Gemini properly knows when to ask Google Maps so it does not hallucinate. This is a big win for app developers wanting to provide smart maps solutions. The new Geospatial Resoning framework is a major step forward when it comes to disaster aid, since users can now combine weather forecasts, population maps, satellite imagery and much more. This makes risk analysis much easier, having all data within one view and model.
Read more:
Lovable Launches Shopify Integration
https://lovable.dev/blog/shopify-integration
The News:
- Lovable released an integration with Shopify that creates functional e-commerce stores from text prompts. Users describe their store concept and the AI generates product pages, checkout functionality, and navigation within minutes.
- The integration connects Shopify’s checkout, payment processing, subscriptions, and tax handling with Lovable’s AI builder. Users can customize landing pages, onboarding flows, and post-purchase experiences around the core storefront.
- The workflow requires four steps. Users tell Lovable to build an online store, the AI sets up the shopping cart and product pages, users claim the store on Shopify, and then start selling. The integration currently supports only new Shopify stores.
- Users can add products by describing them in text, generating AI images, uploading their own images, or providing image URLs. Product details include name, description, and price.
- The system generates single-page applications that run on JavaScript, which creates SEO limitations since search engines may struggle to index dynamically loaded content.
My take: If you read the announcement on X and see comments like “pivotal moment” and a “new era is here”, it makes you wonder where all the hype comes from. In practice this launch feels more like a “hack” where Lovable builds single page stores using a predefined format. It cannot work with existing Shopify stores, and it can only create single page applications (SPA). If you know anything about SEO and SPA you already know this is not the preferred way to go for online stores, but there is a reason Lovable did it and it is to keep things simple and controlled for the AI generator.
Being able to create shopping stores without coding is not new either, I mean we have lots of alternatives from companies like Wix, Squarespace, Hostinger, BigCommerce and WooCommerce. The benefit with those services is that you don’t have to support the code base, with Lovable you suddenly becomes your own IT department that need to support your own vibe coded source. I can see the value for experienced developers who want to own their code and improve upon it, but I think that segment of users will avoid SPA and use something like Claude Code or Codex instead. I had such a hard time seeing the true value of this proposition, but after reading on X a few days ago that the feature was built by a 17-year old during his internship at Lovable it kind of makes sense. Ship fast, build structure later. If you want to see how a Lovable store looks like, you go to the official Lovable merch store at merch.lovable.dev.
Read more:
Anthropic Launches Claude Code on the Web
https://www.anthropic.com/news/claude-code-on-the-web
The News:
- Anthropic released Claude Code on the web in beta research preview, bringing browser-based AI coding to Pro and Max subscribers without requiring terminal access.
- The web version runs on Anthropic-managed cloud infrastructure with isolated sandbox environments using Gvisor, executing each coding session separately with filesystem and network restrictions.
- Developers can run multiple coding tasks in parallel across different GitHub repositories from a single browser interface, with real-time progress tracking and the ability to adjust Claude’s work mid-task.
- The system integrates directly with GitHub through OAuth authentication, automatically creating pull requests and generating change summaries after task completion.
- Claude Code is also available on iOS as an early preview, allowing developers to initiate and monitor coding tasks from mobile devices.
- The web version supports parallel execution of 3-10 concurrent tasks, while the CLI version processes sequentially.
- Network access is controlled through custom domain configuration, allowing developers to specify which external services Claude can access, such as npm package registries for running tests.
My take: So when should you use Claude Code on the web vs in the terminal? Technically it’s the same Claude Code, the main difference that one of them runs on your computer, the other one runs in a Ubuntu-based container with Gvisor isolation. The benefits of running Claude Code on the web is simpler setup, team visibility and mobile access. I see these as complements, not replacements. I think most people will use the web version for bug fixes or routine fixes, and use the CLI version for deeper work. Both versions can do things in parallel, it’s just a matter of launching parallel tasks in the web interface or launching multiple terminal windows in parallel.
Lightricks Launches LTX-2 Open-Source AI Video Model
https://ltx.video/blog/introducing-ltx-2

The News:
- Lightricks released LTX-2, an open-source AI model that generates synchronized audio and video in a single process. The model runs on consumer-grade GPUs and produces content at up to 50% lower compute cost than competing models.
- The model generates six-second HD videos in five seconds, creating content faster than playback speed. Output specifications include native 4K resolution at 48-50 fps for clips up to 10 seconds with synchronized audio.
- LTX-2 supports multi-keyframe conditioning, 3D camera logic, and LoRA fine-tuning for frame-level control. Input formats include text, images, video, audio, depth maps, and reference footage.
- The model is available now through API and LTX Studio platform. Full open-source release with model weights and tooling is scheduled for November 2025.
- API pricing starts at $0.04 per second for HD generation, $0.07 per second for Pro version, and $0.12 per second for 4K at 48 fps with full-fidelity audio. Generation costs average $0.06 for LTX models in practice.
My take: Compared to Sora 2 or Google Veo 3.1, the videos generated with LTX-2 looks fairly dated. The sound is often wrong or just bad, and the videos have lots of temporal issues such as characters changing clothes during a sequence. But if you want to create unlimited amounts of AI videos on your 24GB NVIDIA PC then this is what you have been waiting for. Given simple enough prompts that match well the data it was trained upon (YouTube videos) you can create some pretty nice animated videos with it. For free. If you are curious on how it compares to Veo 3.1 and Sora 2 you can check the video below.
Read more:
DeepSeek AI launches DeepSeek-OCR
https://github.com/deepseek-ai/DeepSeek-OCR

The News:
- DeepSeek-OCR is a 3B vision-language model that compresses documents by mapping text into images and encoding them as vision tokens. The system consists of DeepEncoder (a vision encoder) and DeepSeek3B-MoE-A570M (a decoder with 570M active parameters).
- The model achieves 97% OCR precision at compression ratios below 10x (where text tokens are within 10 times the vision tokens). At 20x compression, accuracy remains around 60%.
- DeepSeek-OCR supports multiple resolution modes: Tiny (512×512, 64 vision tokens), Small (640×640, 100 vision tokens), Base (1024×1024, 256 tokens), Large (1280×1280, 400 tokens), and Gundam mode (dynamic resolution with ~795 tokens).
- On OmniDocBench, DeepSeek-OCR in Small mode outperforms GOT-OCR2.0 using 100 vision tokens compared to 256 tokens per page. Gundam mode achieves 0.127 edit distance using ~795 tokens, beating MinerU2.0’s 0.133 with ~6790 tokens.
- The system processes 200,000+ pages per day on a single A100-40G GPU, with different document types requiring different token counts: slides need ~64 tokens, books/reports ~100 tokens, and dense newspapers ~800 tokens in Gundam mode.
My take: DeepSeek-OCR is like Mistral OCR a vision-language model. PDFs are first converted into images (screenshots/renderings of each page) and are then fed into a vision encoder. For DeepSeek-OCR, this is the “DeepEncoder” vision model. The vision encoder analyzes the entire page layout, text positioning, tables, charts, and all visual elements simultaneously. The vision encoder then converts these images into vision tokens (compressed numerical representations). A simple slide might use only 64 vision tokens, while a dense newspaper page could use ~800 tokens in Gundam mode. These vision tokens are then passed to a language model decoder, which for DeepSeek-OCR is called DeepSeek3B-MoE-A570M, with 570M active parameters.
This process is very similar to how Mistral OCR works, but with Mistral their vision model is called Pixtral vision encoder, and they use a much larger 123B text decoder. The main problem with vision-language models is that if a word cannot be parsed, the model will make a qualified guess. And when it comes to document translations, in most cases this is not what you want. Let’s say the word “goat”. If we are unlucky the word “g” cannot be parsed properly, maybe due to scaling artifacts when creating the vision tokens. Instead of showing something like “xoat” or “-oat” like a properly setup OCR translator would do, a vision-language model will happily output “boat” if it thinks it matches the context. Vision-language models are here to stay, and if you use them right they are amazing tools – low cost, high quality, and high speed. But be aware of the limitations when you are using them.
Read more:
- Arxiv: DeepSeek-OCR: Contexts Optical Compression
- DeepSeek-OCR – Lives up to the hype : r/LocalLLaMA
- Pulse AI Blog – Putting DeepSeek-OCR to the Test
Tencent Releases WorldMirror, Open-Source 3D Reconstruction Model
https://github.com/Tencent-Hunyuan/HunyuanWorld-Mirror

The News:
- Tencent released HunyuanWorld-Mirror, an open-source feed-forward 3D reconstruction model that generates 3D worlds from videos, multi-view images, text, or single images.
- The model runs on a single GPU and completes reconstruction in 1 second for typical 8-32 view inputs, outputting dense point clouds, multi-view depth maps, camera parameters, surface normals, and 3D Gaussian Splattings simultaneously.
- WorldMirror accepts diverse geometric priors including camera poses, intrinsics, and depth maps through a multi-modal prior prompting mechanism, which translates each prior into structured tokens and fuses them with image tokens.
- The model uses a unified transformer-based architecture where different decoder heads specialize in predicting depth, normals, camera poses, or point maps while sharing the same underlying scene representation.
My take: This is a seriously impressive model. Take any video, multi-view image, text or image and WorldMirror will generate a complete 3D geometry as dense point clouds, gaussian splattings, multi-view depth maps, surface normals and even camera parameters. All in one single pass! I can see so many uses for this – game developers can now quickly prototype environments for their game, film studios can easily generate full 3D models for advanced compositioning, and robotics engineers can now create varied environments just from a video capture. Hunyan continues to push the boundaries of AI-3D and it will be interesting to see just how far they will have come in 2-3 years.
Read more:
Runway Launches Three New Features for Custom AI Workflows

The News:
- Runway introduced three features last week: Apps for Advertising, Workflows, and Model Fine-tuning. Apps simplify video and image generation by breaking down AI capabilities into task-specific tools.
- Apps for Advertising includes nine tools such as Reshoot Product, which transforms product photos into multiple assets by changing settings and styling. Other apps handle relighting scenes, removing objects from video, adding dialogue to images, upscaling to 4K, changing weather conditions, swapping backgrounds, and shifting time of day.
- Workflows provides node-based workflow creation. Users chain multiple models and processing steps together. Workflows live inside the Runway platform.
- Model Fine-tuning targets vertical industries including robotics, life sciences, education, and architecture. Runway stated its general-purpose models struggle with real-world tasks in these domains. Fine-tuning uses less data and compute than training from scratch.
My take: If you have a moment, check their announcement for Apps for advertising over at X. Scroll down and check The Mockup app, The Vary Ads app and The Expand app. Basically you give it an input image and it then creates a mockup ad for it. It’s like vibe coding but for ads. Workflows I think looked amazing too, especially for getting consistent output with AI generated videos. I will definitely check this one out in more detail. Runway say that “Model Fine-tuning is available now for select pilot partners and coming soon to everyone” – this could be a true game changer for AI generated videos.
Read more: