
In Sweden there are still AI consultancy companies strongly defending what they call “Mogen AI” (“Mature AI” in English) – traditional machine learning based on manual feature engineering. The argument is that it’s “good enough” and that you really don’t need to invest in deep transformer skills. And I agree that this is often the case, if your bar is modest improvements and narrowly scoped tasks. But this mindset misses a fundamental shift. The most valuable patterns are no longer found in isolated features. They’re found in relationships between events, across time, and at scale. That’s something “Mature AI” just isn’t built to capture.
The problem with “Mature AI” is that it puts humans in charge of guessing what matters. Every new model needs a new feature set, new labels, new training. It’s slow, brittle, and blind to nuance. Modern transformer models change that. They learn directly from raw signals, uncovering deep, contextual structures no analyst could ever define. Unlike traditional ML that requires separate models for each business problem (fraud, disputes, authorizations), these foundation models create unified embeddings that work across multiple tasks simultaneously.
When Stripe moved from “Mature AI” into a modern transformer-based foundation model their fraud detection rates increased from 59% to 97% “practically overnight”. If your organization is stuck developing solutions the “Mature AI” way, let’s book a meeting to see if there is anything a modern transformer-based architecture could do for your company! The possibilities are almost endless, but you need LLM experts that know how to properly embed the data so transformer models can use it.
YOU CAN NOW LISTEN TO THIS NEWSLETTER ON SPOTIFY
I got the request from many that would like to listen to this newsletter as a podcast on their way to work. So you can now listen to it here: Tech Insights 2025 Week 20 on Spotify.
Thank you for being a Tech Insights subscriber!
THIS WEEK’S NEWS:
- Stripe Launches Industry’s First AI Foundation Model for Payments
- ChatGPT Significantly Improves Student Learning Outcomes
- HeyGen Launches Avatar IV: Single-Photo AI Video Creation
- Google Develops Automated Text Simplification System Using Dual Gemini Models
- Google Releases Gemini 2.5 Pro Preview (I/O Edition) with Enhanced Coding Capabilities
- Mistral Medium 3 : High Performance Agentic Model
- Figma Make: AI-Powered Design-to-Prototype Conversion
- Anthropic Launches Web Search API for Claude Models
- Alibaba’s ZeroSearch Cuts AI Training Costs by 88% Without Real Search Engines
- NVIDIA’s Parakeet V2 Sets New Standard for Speech Recognition
- AI Coding Tool Cursor Secures $900M at $9B Valuation
- Meta Introduces Locate 3D for Precise 3D Object Localization
Stripe Launches Industry’s First AI Foundation Model for Payments

The News:
- Stripe has developed a transformer-based foundation model for payments that processes and learns from billions of transactions, creating vector embeddings that capture subtle payment patterns and signals.
- The model dramatically improved fraud detection capabilities, increasing card-testing attack detection rates from 59% to 97% “practically overnight”.
- Trained on tens of billions of transactions using self-supervised learning, the model captures hundreds of subtle signals about each payment that specialized models would typically miss.
- The foundation model is being deployed across Stripe’s payments suite to improve performance in areas including fraud prevention, dispute handling, and payment authorization.
My take: For years Stripe has used traditional Machine Learning models trained on discrete features like BIN, zip code, and payment method. These models worked well in narrow domains but hit a ceiling. They required hand-tuned inputs, task-specific training, and constant manual upkeep. They missed patterns that spanned across transactions, across time, and across users. Stripe’s new foundation model proves that payments behave like languages: structured, contextual, and deeply dependent on sequence.
In Sweden there are still many companies arguing that mature AI (“Mogen AI” in Swedish) is good enough even for these kinds of use cases. I argue the opposite. Mature AI can’t see this structure. Transformers can. That’s why this shift isn’t just an upgrade – it’s a different way of understanding data entirely. The improvement in fraud detection at Stripe from 59% to 97% should be proof enough.
Read more:
ChatGPT Significantly Improves Student Learning Outcomes
https://www.nature.com/articles/s41599-025-04787-y

The News:
- A comprehensive meta-analysis of 51 studies published between 2022-2025 shows ChatGPT has a large positive impact on students’ learning performance and moderately improves learning perception and higher-order thinking.
- The research found ChatGPT has the strongest effect on learning when used in problem-based learning environments (g = 1.113) and when implemented for 4-8 weeks (g = 0.999).
- ChatGPT proved most effective for developing higher-order thinking in STEM courses (g = 0.737) and when functioning as an intelligent tutor (g = 0.945).
- The study revealed that ChatGPT’s impact on learning performance (g = 0.867) significantly outperforms traditional AI assessment tools (averaging at g = 0.390).
My take: Much like AI-based programming won’t replace programmers any time soon, ChatGPT won’t replace good teachers. While ChatGPT significantly helped students learn facts and understand basic concepts really well (g = 0.867, a big improvement), it wasn’t as good at helping students develop deeper thinking skills like analyzing, evaluating, and creating new ideas (g = 0.457). Still this is a three year meta study, and reasoning models have only been out for six months. Give it 2-3 years and I’m quite sure tools like ChatGPT will excel even at helping students analyze, evaluate and creating new ideas. And that is probably when we need to start rethinking our entire school system.
HeyGen Launches Avatar IV: Single-Photo AI Video Creation
https://twitter.com/HeyGen_Official/status/1919824467821551828

The News:
- HeyGen has released Avatar IV, an AI model that transforms a single photo into a talking video with synchronized lip movements and facial expressions.
- The system analyzes vocal tone, rhythm, and emotion to generate facial movements that match the audio, including head tilts, natural pauses, and micro-expressions.
- Videos are limited to 30 seconds per generation, with Creator Plan users receiving 5 minutes of Avatar IV video generation per month.
My take: I’m actually quite stunned by this release. What makes Avatar IV so interesting is not that it is very good at creating realistic deep fake videos. It is. The microexpressions they have embedded in the output actually makes it really difficult to spot that the video is a deep fake. No, the most interesting feature about this release is the accessibility, since everyone can now create realistic deep fakes using a very simple point-and-click web interface! If used the right way with some post-processing, HeyGen Avatar IV can produce video content that is virtually impossible to differentiate from real video. I am quite sure this will have an effect on everything we consume, I’m just not sure exactly what the long-term effect will be.
Read more:
- el.cine on X: “can you still tell what’s real? not anymore. HeyGen just dropped Avatar IV, it can make anyone talk anything with human like expression and movement the lines between real and AI is gone.
- Heygen Avatar IV – Strangers Words of Wisdom to YOU – YouTube
- HeyGen Avatar IV: Deepfakes Are Point-and-Click Now.
Google Develops Automated Text Simplification System Using Dual Gemini Models

The News:
- Google Research has developed a “minimally-lossy text simplification” system using Gemini AI models that makes complex text easier to understand while preserving original meaning, addressing barriers to information access in fields like healthcare, law, and finance.
- The system employs a novel automated evaluation and prompt refinement loop where one Gemini model evaluates the output of another and refines instructions based on readability and fidelity metrics, enabling autonomous discovery of effective simplification strategies over 824 iterations.
- In a large-scale study with 4,563 participants, simplified text improved comprehension accuracy by 3.9% overall, with medical texts showing the most significant improvement at 14.6% and financial documents at 6%.
- Beyond improved comprehension, participants reported reduced cognitive load when using simplified text, with an absolute improvement of 0.33 on a 5-point scale based on a simplified NASA Task Load Index.
My take: Have you ever been handed medical texts of financial documents, and wished you could have someone explain to you what it says? Instead of handing them over to ChatGPT and asking it to explain it to you, this new approach just rewrites the documents so they are easier to understand but still contains the same information! Google has already implemented it into their Google app as a “Simplify” feature on iOS, but use it with caution since the research team clearly states that “while our system aims for high fidelity, LLM errors are possible”. It will be interesting to see the long-term effects of this, and how it will affect the way we communicate in different sectors.
Google Releases Gemini 2.5 Pro Preview (I/O Edition) with Enhanced Coding Capabilities
https://blog.google/products/gemini/gemini-2-5-pro-updates

The News:
- Google released an early access version of Gemini 2.5 Pro Preview (I/O edition) with significantly improved coding capabilities, especially for building interactive web applications.
- The updated model now ranks #1 on the WebDev Arena leaderboard, surpassing the previous version by +147 Elo points, demonstrating superior ability to build aesthetically pleasing and functional web apps.
- Gemini 2.5 Pro achieves state-of-the-art video understanding with a score of 84.8% on the VideoMME benchmark, enabling new capabilities like transforming YouTube videos into interactive learning applications.
- Gemini 2.5 Pro can generate sophisticated code including multi-GPU implementations for machine learning models like transformers and GANs that work seamlessly from the start.
My take: The updated Gemini 2.5 Pro outperforms all other AI models from OpenAI, DeepSeek, and Anthropic in coding benchmarks. According to Silas Alberti from Cognition, “It was the first-ever model that solved one of our evals involving a larger refactor of a request routing backend. It felt like a more senior developer because it was able to make correct judgement calls and choose good abstractions”. I have used it myself over the weekend, giving it complex issues to solve that Claude 3.7 and o3 couldn’t handle. The new Gemini 2.5 Pro solved them all, and you almost get the same feeling as when you first installed Claude 3.5 last summer and you suddenly could code anything with AI. Most users on Reddit seem to agree with me, with threads like “Gemini 2.5 Pro is another game changing moment” including comments like “gemini 2.5 pro is a paradigm shift”. If you want to use it from Cursor you have to setup a custom configuration to use it, since Cursor doesn’t natively support it yet.
Read more:
- Using Gemini-2.5-Pro-preview-05-06 with Cursor & Cline
- Bishal Nandi on X: “It’s been just a few hours since Google dropped Gemini 2.5 Pro (I/O edition) And people can’t stop being creative with it. Here are 10 WILD examples so far
Mistral Medium 3 : High Performance Agentic Model
https://mistral.ai/news/mistral-medium-3

The News:
- Mistral AI released Medium 3, a new AI model that delivers state-of-the-art performance at 8x lower cost than competitors while simplifying enterprise deployments.
- The model performs at or above 90% of Claude Sonnet 3.7 on benchmarks across the board while costing significantly less at $0.40 per million input tokens and $2.00 per million output tokens.
- Medium 3 shows decent results in coding and multimodal understanding, surpassing models like Llama 4 Maverick and Cohere Command A.
- The model can be deployed on any cloud platform, including self-hosted environments requiring only four GPUs.
My take: Make no mistake, this is a model specifically built for large corporations that want a decently sized model (I am guessing 195B parameters) that they can run on their own hardware setup (you need four Hopper GPUs to run it). Mistral Medium can be “continuously pretrained, fully fine tuned, and blended into enterprise knowledge bases” so if this is what you have been looking for then this is your model. This is not a model you use for every day chat or programming tasks, this is an agentic model used for data pipelines, and companies that have worked with Mistral during development are active in financial services, energy, and healthcare sectors. Mistral seems to be working very closely with companies when they build these models, so it will be very interesting to see what Mistral Large 3 will be capable of when it’s launched in a few weeks.
Figma Make: AI-Powered Design-to-Prototype Conversion
The News:
- Figma has launched Figma Make, an AI-powered feature that transforms static designs into interactive prototypes using text prompts.
- The tool uses Anthropic’s Claude 3.7 Sonnet AI model to generate functional code while preserving original design structures, allowing users to create clickable demos with animations and real-time feedback.
- Figma Make also enables direct editing of AI outputs, letting designers replace images or adjust padding and margins without coding knowledge.
- The feature allows publishing completed designs as functional web apps, with a Supabase integration coming soon for backend setup.
My take: Unlike other platforms like Vercel v0 and StackBlitz’s Bolt.new, Figma Make can inherit existing design systems directly. This is a major advantage for Figma, and it’s already included in Figma’s paid plans starting at $16 per seat per month. Early access customers have already used it to “craft video games, a note-taking app and a personalized calendar”. Like most vibe-coding tools today, expect to use these tools for early prototypes, and be prepared to throw all code away when you want to move into production. That will probably change in the future, but that future will not happen in 2025. In 2025 you still need to be good at coding to produce high quality source code, and it doesn’t really matter if you use Lovable, v0, Windsurf, Cursor or Figma since they all use the same models “under the hood”.
Anthropic Launches Web Search API for Claude Models
https://www.anthropic.com/news/web-search-api

The News:
- Anthropic has introduced their Web Search API that gives Claude AI models access to current information from the Internet.
- When enabled, Claude uses reasoning capabilities to determine if web search would help answer a query, then generates search queries, retrieves results, analyzes information, and provides comprehensive answers with citations.
- Claude can perform multiple progressive searches, using earlier results to inform subsequent queries for more thorough research, with developers able to control this behavior through the max_uses parameter.
- The API includes customization options such as domain allow lists and block lists.
- Web search is available for Claude 3.7 Sonnet, Claude 3.5 Sonnet, and Claude 3.5 Haiku models at $10 per 1,000 searches plus standard token costs.
My take: $10 per 1,000 searches is actually very reasonable. Google Gemini charges $35 per 1,000 queries, Bing Search API charges $15, and Brave API charges $9. Early results have so far been positive, with customers like Quora saying “It is cost effective and delivers search results with impressive speed”. Definitely worth checking out if you have needs for an LLM with web access.
Alibaba’s ZeroSearch Cuts AI Training Costs by 88% Without Real Search Engines
https://arxiv.org/html/2505.04588v1
The News:
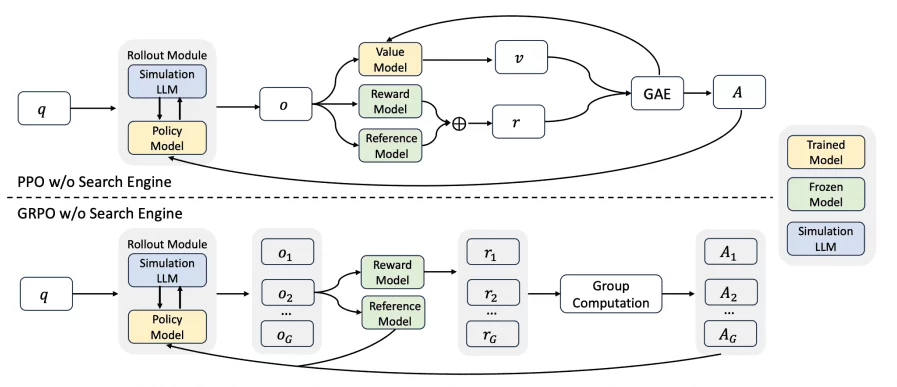
- Alibaba researchers have developed ZeroSearch, a reinforcement learning framework that teaches language models to search for information without using real search engines, reducing training costs by 88% while matching or exceeding traditional methods.
- The system transforms pre-trained LLMs into retrieval modules through lightweight supervised fine-tuning, enabling models to generate both relevant and noisy documents in response to queries without external API calls.
- ZeroSearch employs a curriculum-based rollout strategy that gradually increases difficulty during training, starting with high-quality documents and progressively introducing challenging retrieval scenarios to strengthen reasoning abilities.
- In extensive evaluations across seven question-answering datasets, a 7B parameter model achieved performance comparable to Google Search, while a 14B parameter model surpassed Google’s capabilities with higher accuracy scores.
- Training with approximately 64,000 search queries using Google Search via SerpAPI would cost about $586.70, while ZeroSearch’s approach using a 14B parameter model on four A100 GPUs costs only $70.80.
My take: Maybe you heard about this news last week but wondered what this was all about? What does it really mean to teach language models to search for information without using real search engines? The purpose with ZeroSearch is to teach LLMs two important skills: (1) when they should search for additional information (recognizing knowledge gaps), and (2) how to effectively use search results to answer questions. Traditionally, to do that, you need to connect the model to real search engines like Google during training, pay thousands of dollars for API calls, and deal with the unpredictable quality of search results. ZeroSearch solves all these problems by creating a simulated search environment where one LLM acts as a “fake search engine” generating documents, and another LLM (the one being trained) learns to search and use information. There are still several situations where you want to train the model on actual live search data, but for smaller companies and researchers that want to train models on specific data or use cases this is a game changer!
NVIDIA’s Parakeet V2 Sets New Standard for Speech Recognition

The News:
- NVIDIA released Parakeet-TDT-0.6B-v2, a fully open-source automatic speech recognition (ASR) model that transcribes one hour of audio in just one second while achieving a 6.05% Word Error Rate (WER).
- The model operates with only 600 million parameters yet tops the Hugging Face Open ASR Leaderboard, surpassing larger models including OpenAI’s Whisper-large-v3 which has 1.6 billion parameters.
- Parakeet V2 includes advanced features such as accurate word-level timestamps, automatic punctuation and capitalization, and can efficiently process audio segments up to 24 minutes long in a single pass.
- The model demonstrates strong performance on challenging audio, including spoken numbers and song lyrics, with minimal degradation even in noisy environments (at SNR 5 dB, WER only increases to 8.39%).
- Released under the CC-BY-4.0 license, Parakeet V2 is free for commercial use and requires minimal hardware resources, needing only 2GB of RAM to run.
My take: If you are only using English language then Parakeet should probably be your go-to option for speech-to-text. If you have ever used Whisper v3 before you know how slow it can be especially if you run it locally. However if you use strong dialects or need other languages than English you are still stuck with the older Whisper V3 released in November 2023 for a while longer. Here’s a tip by the way: if you need to transcribe large amounts of spoken text and use MacOS I recommend the two apps Hush and Whisper Transcription. By running the audio through Hush first to remove echo and noise the quality you get out from the Whisper transcription is way better.
AI Coding Tool Cursor Secures $900M at $9B Valuation

The News:
- Anysphere, the company behind AI-powered code editor Cursor, has raised $900 million in a funding round led by Thrive Capital, with participation from Andreessen Horowitz and Accel, valuing the company at $9 billion.
- Cursor generates nearly a billion lines of working code per day and promises to transform programming into what is typically called “vibe coding” – a creative flow process powered by AI.
- Anysphere’s annual recurring revenue reportedly reached $200 million by April 2025, making it one of the fastest-growing software companies in history.
My take: In January Cursor was valued at $2.6 billion, and that has now tripled to $9 billion. While GitHub Copilot and Windsurf might look similar if you just go by specification, as soon as you start using Cursor on a daily basis it becomes clear just how good their IDE is. There is a good reason Cursor is valued at $9 billion and that developers are creating around 1 billion lines of working code per day in it (this is the number of lines of code developers actually have accepted into their code base). If you are developing with AI today and still have not tried Cursor I strongly recommend that you do, just read up a bit on context sizes, rules files, chat summarizations, and prompting techniques first.
Read more:
Meta Introduces Locate 3D for Precise 3D Object Localization

The News:
- Meta has released Locate 3D, an AI model that enables robots to locate specific objects in 3D environments using natural language commands like “the small coffee table between the sofa and the lamp”.
- The system operates directly on sensor observation streams from RGB-D sensors, making it immediately deployable on robots and AR devices without requiring complex 3D ground-truth data.
- Locate 3D consists of three key components: a preprocessing step that lifts 2D foundation features to 3D point clouds, a 3D-JEPA encoder for contextual understanding, and a language-conditioned decoder that predicts object locations.
- Meta has open-sourced the model, code, and a new dataset containing over 130,000 language annotations across 1,346 scenes, doubling existing data annotations.
My take: Two months ago, Google connected two hands to Gemini and asked it to interact with its environment. That model was still very much 2D, in that objects were lying flat on a table. Meta’s Locate 3D brings this to the next level, where a robot or autonomous vehicle will be able to precisely find and track objects in 3D space based on their description. There are so many applications for this, just to mention a few we have assistive technologies, warehouse automations and disaster responses. Meta has a pretty cool interactive demo you can try out, if you have time give it a go!