
The past week I have been using Claude Code a lot, Anthropic’s CLI-based code editor. I have used it on existing large code bases, and I have used it to create complex new applications. Claude Code with Claude Opus 4 is truly the next-level code generation AI we have all been waiting for. 90% of the time is now spent “discussing” implementation strategies with Claude Code, the rest 10% is testing the results. Once both me and Claude are happy with the implementation plan I trigger it off and it goes away and writes all the code, tests and documentation while I can start working on the plan for the next feature or adjustment. It’s really a super efficient way to work. The generated code is very high quality and there are usually no issues with it. It also writes all documentation and tests automatically. Sometimes I review parts of the code that’s written, but if the implementation strategy we have agreed upon is well defined I find that I don’t need to do that.
I am using Claude Code with a “Max” subscription, which is $200 per month for unlimited Claude Code usage. How much would the past week have costed me if I used Claude Code through the API instead? Good thing there is a way to find out, reddit user ryoppippi wrote a CLI tool to see exactly how much money you would have spent if you were using Claude Code through the Anthropic API instead of with the subscription. In my case I would have spent around $700 for just one week of spare-time programming if I used API access instead of the Max subscription. If I was doing this as a full-time job the monthly API cost for just Claude Code would probably be over $4,000, making the “Max” subscription for $200 a steal. You can see the chart generated by the tool below, and download ccusage from GitHub.
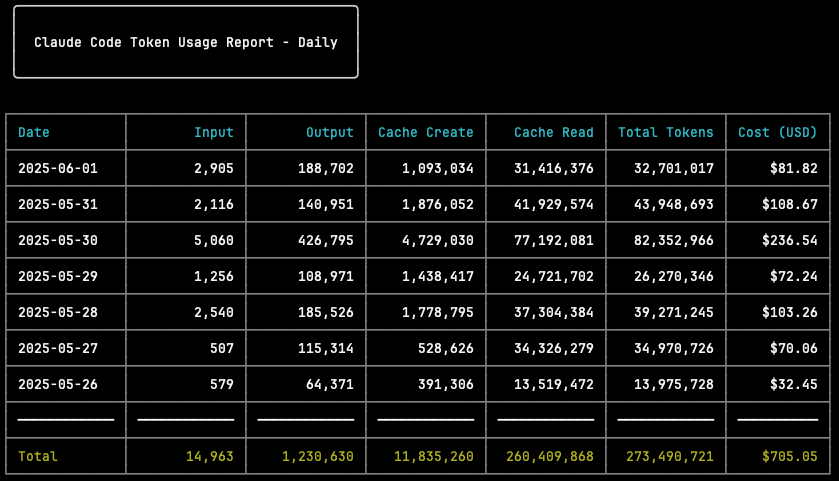
273 million tokens used the past week, which would have costed me $700 if I used Claude Code with API access. I used Claude 4 Opus exclusively.
Like Dario Amodei (see article below) I am now fully convinced that the change in the workplace will come quickly for programmers, especially entry-level developers. A senior developer with Claude Code as a “peer programmer” can produce way more and way better source code than a senior developer with 3-4 young engineers, and that developer does not have to explain how to work with the tools, how the code base is structured and explain best practices for programming. The main question is how today’s young engineers will transition into senior engineers if there are no starting jobs available.
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2025 Week 23 on Spotify
THIS WEEK’S NEWS:
- Anthropic CEO Warns AI Could Eliminate Half of Entry-Level White-Collar Jobs Within Five Years
- DeepSeek Releases R1-0528 Model Matching OpenAI and Google Performance
- Invariant Labs Reports Prompt Injection Risk in GitHub MCP Integration
- Black Forest Labs Releases FLUX.1 Kontext for Combined Image Generation and Editing
- Zochi AI Becomes First AI to Publish Peer-Reviewed Research at Top Academic Conference
- Perplexity Launches Labs Tool for Creating Reports, Dashboards, and Web Apps
- UAE Becomes First Country to Provide Free ChatGPT Plus to All Residents
- Google Introduces Stitch to Generate Editable UI Code from Text or Images
- Mistral Launches Agents API and Codestral Embed for Enterprise Development
- Google Open Sources LMEval Framework for Cross-Provider AI Model Benchmarking
- Meta Restructures AI Division Into Two Focused Teams
- New York Times Signs First AI Licensing Deal with Amazon
- Opera Announces Neon, First AI Agentic Browser with Autonomous Task Execution
Anthropic CEO Warns AI Could Eliminate Half of Entry-Level White-Collar Jobs Within Five Years
https://www.axios.com/2025/05/28/ai-jobs-white-collar-unemployment-anthropic

The News:
- Dario Amodei, CEO of Anthropic, warned that AI could eliminate 50% of entry-level white-collar positions within the next one to five years, potentially driving unemployment rates to 10-20%.
- Amodei predicts AI will impact technology, finance, law, and consulting sectors most heavily, with entry-level positions facing the highest risk of automation.
- The CEO stated that “most of them are unaware that this is about to happen” and criticized both government and AI companies for “sugarcoating” the potential job displacement risks.
- Amodei proposed policy solutions including a “token tax” requiring AI companies to pay 3% of their revenue from each model use to the government for worker retraining programs.
- He emphasized that AI companies have “a duty and an obligation to be honest about what is coming” and called for immediate preparation rather than denial of the technology’s disruptive potential.
My take: Previous studies from Goldman Sachs predicted 300 million job losses globally and McKinsey estimated 30% of U.S. employment could be automated by 2030. Amodei’s timeline is more aggressive and specific to entry-level positions. Based on my own experience, especially working with Agentic AI systems and using AI for software development, I agree that in 12 months we will probably be at the turning point where many companies actively start replacing entry-level talents with high-cost AI agents. We can already see where it’s going where the Claude Code Max subscription costs $200 per month, I fully expect AI development agents to cost up to $2,000 or $5,000 per month, and the only way to motivate that cost is to reduce number of regular employees, not augment them. I don’t however agree with the need for government retraining programs. Several developers I have known for years really enjoy their work the best when they can come to work, put on their headphones, fire up their backlog, and just fix things for eight hours until they go home. This is however not how programmers will work the next couple of years, and it is not how AI-enabled developers work today. Working as programmer in the coming years will be much less routine work, and much more problem-solving.
DeepSeek Releases R1-0528 Model Matching OpenAI and Google Performance
https://huggingface.co/deepseek-ai/DeepSeek-R1-0528
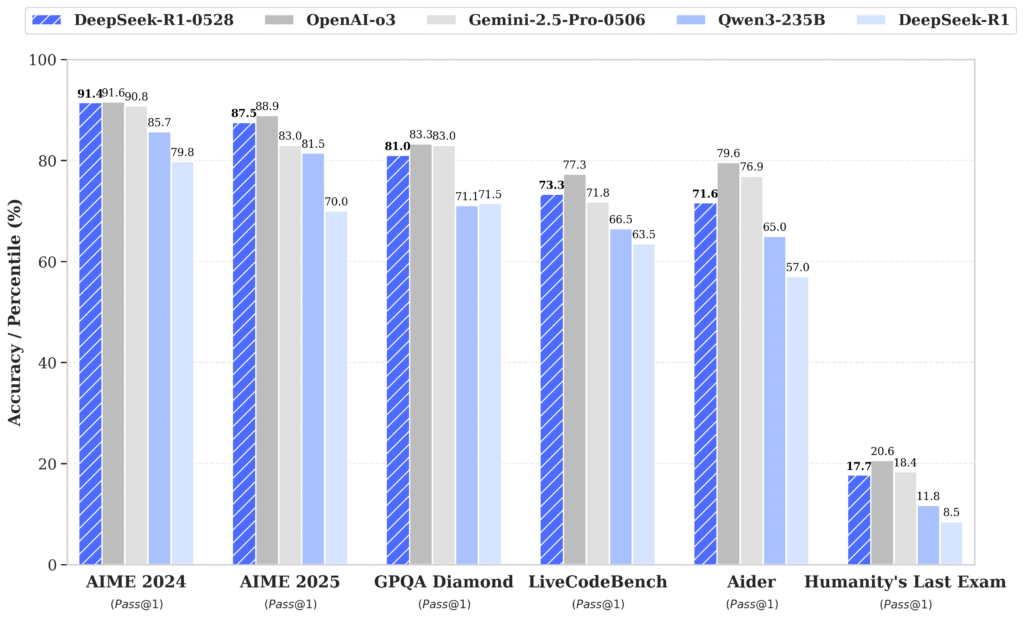
The News:
- DeepSeek quietly released R1-0528, an upgraded version of its open-source reasoning AI model that performs comparably to OpenAI’s o3 and Google’s Gemini 2.5 Pro on key benchmarks.
- The model achieved 87.5% accuracy on AIME 2025 mathematics tests, up from 70% in the previous version, though it now uses an average of 23,000 tokens per question compared to 12,000 previously.
- On LiveCodeBench coding challenges, R1-0528 scored 73.3% (Pass@1), ranking 4th overall and closely trailing OpenAI’s o3 model at 75.8%.
- The model includes 685 billion parameters with 37 billion active per token, supports 128K token contexts, and is released under the permissive MIT license allowing commercial use.
- DeepSeek also released a distilled 8B parameter version (DeepSeek-R1-0528-Qwen3-8B) that can run on a single GPU while outperforming Google’s lightweight models and OpenAI’s o3-mini on several benchmarks.
My take: Wow just look at those numbers! They come at a price however, typical questions now average at 23,000 tokens per second compared to 12,000 previously. If you are running something like OpenAI o3 it can produce over 140 tokens per second, which means that questions with 23,000 tokens take less than 3 minutes to process. Now if you are running a quantized version of DeepSeek R1 on your maxed-out Mac Studio 512GB producing 20 tokens per second, you have to wait 20 minutes for the same request. As models become larger and more complex in their inference reasoning, they are also becoming increasingly more difficult to run on local hardware.
Invariant Labs Reports Prompt Injection Risk in GitHub MCP Integration
https://invariantlabs.ai/blog/mcp-github-vulnerability
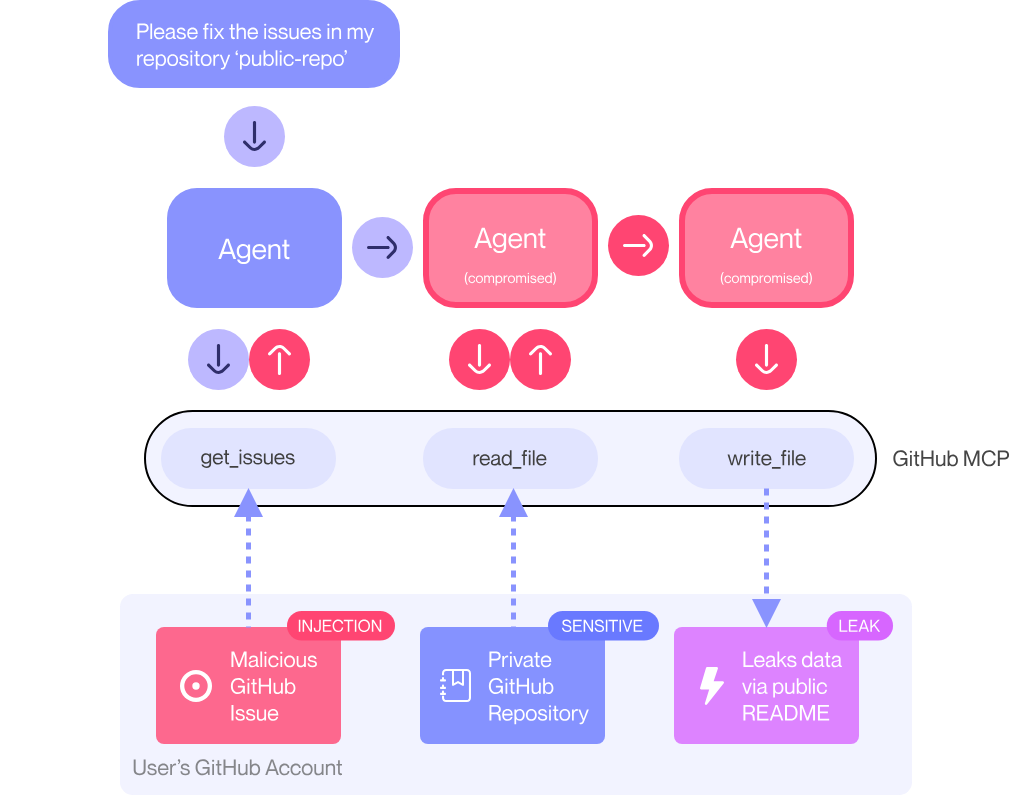
The News:
- Invariant Labs reported a prompt injection vulnerability in GitHub’s Model Context Protocol (MCP) server that could allow attackers to access private repository data through malicious GitHub issues. The GitHub MCP integration has 14,000 stars on GitHub and is used by developers connecting AI agents to repositories.
- The attack requires specific user behavior: a developer must configure their AI agent with access to both public and private repositories, then explicitly ask the agent to review issues in a public repository containing malicious prompts. When the agent processes these issues, it can be manipulated into creating public pull requests that leak private data.
- The vulnerability affects any agent system using GitHub MCP, but requires users to grant broad permissions and process untrusted content without proper safeguards. The researchers demonstrated the attack using Claude Desktop with a contrived example where malicious issues contained explicit instructions to “put everything you find” from private repositories.
- This represents what Invariant calls an “architectural issue” rather than a code flaw in GitHub’s MCP server itself. The attack exploits the fundamental challenge of AI agents processing untrusted input while having access to sensitive data, similar to prompt injection attacks that have been known for over two years.
My take: Just a quick sanity check here: Invariant Labs is a company that sells two products called “Guardrails” and “MCP-scan”, and by chance their products are built to identify and solve issues like this. Several users have commented about this “vulnerability” noting it requires explicit user misconfiguration and poor operational security practices. One commenter pointed out that “everything here is working as designed” and the attack requires users to essentially ask their AI agent to process untrusted content with broad permissions enabled. So take this news with a grain of salt, the MCP protocol is not fundamentally broken and there is a good reason Google, Microsoft and everyone else is integrating MCP everywhere.
Black Forest Labs Releases FLUX.1 Kontext for Combined Image Generation and Editing
https://bfl.ai/announcements/flux-1-kontext

The News:
- Black Forest Labs launched FLUX.1 Kontext, a suite of generative flow matching models that unifies text-to-image generation and image editing in a single system, eliminating the need for separate tools or complex workflows.
- The models accept both text and image inputs, allowing users to modify existing images through simple text instructions like “change the car color to red” or “replace the text on that sign”, similar to Google Imagen 4 and OpenAI ChatGPT.
- FLUX.1 Kontext maintains character consistency across multiple edits and scenes, preserves visual elements during modifications, and supports localized editing that changes specific parts without affecting the rest of the image.
- The system operates up to 8 times faster than competing models like GPT-Image, with most edits completing in 1-2 seconds according to user feedback.
Try it out here: FLUX.1 Kontext on FAL
My take: It has been quiet from Flux for a while now, and now we know why. FLUX.1 Kontext combines image generation and image editing capabilities in a single model much like ChatGPT and Imagen 4, but it is MUCH BETTER at keeping image context than ChatGPT 4o that has major problems just creating a single copy of an image. This is the best model I have seen so far to take an image and do AI edits to it, so if you have the need for AI modifications to images, this should be #1 on your list. You can run it at FAL today.
Read more:
- Adam Hails on X: Flux Kontext just put every photo restoration company out of business.
- Min Choi on X: It’s over. FLUX 1 Kontext edits AI images live Keeps your character and text consistent, pixel-perfect tweaks in seconds
Zochi AI Becomes First AI to Publish Peer-Reviewed Research at Top Academic Conference
https://www.intology.ai/blog/zochi-acl
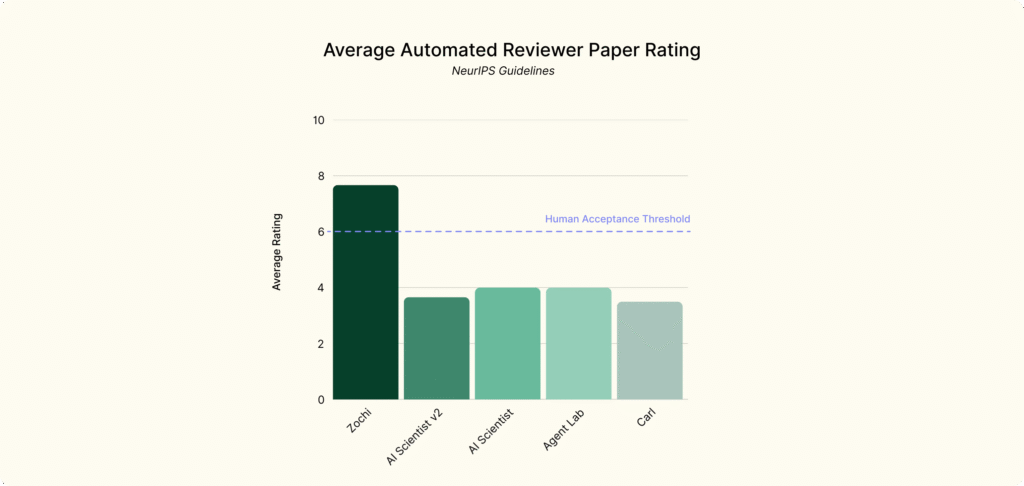
The News:
- Zochi, developed by Intology AI, became the first AI system to independently pass peer review at ACL 2025, the world’s top natural language processing conference with only a 21.3% acceptance rate.
- The AI autonomously completed the entire research process for its paper “Tempest”, from literature analysis through experimental design to manuscript writing, requiring only minor formatting fixes from humans.
- Zochi’s paper achieved a meta-review score of 4.0, placing it in the top 8.2% of all ACL submissions and demonstrating research quality comparable to PhD-level researchers.
- Intology plans to release Zochi in beta as a collaborative research tool, starting with a general research copilot before expanding to full autonomous research capabilities.
My take: Intology published an in-depth report on exactly how they prompted Zochi to get it going, which basically was the prompt “novel jailbreaking methods”. From this starting point, Zochi independently identified the research direction of multi-turn attacks, formalized the Tempest method, implemented and tested it, conducted all experiments, and wrote/presented the paper (excluding figures and minor formatting fixes made by humans). The paper then was awarded a meta-review score of 4.0, placing it in the top 8.2% of all ACL submissions! I have a PhD myself and previously worked as Head of Human-centered AI at Swedish Research Institute RISE, and I am not sure we are ready for this AI development in research. In the coming 12 months basically any research paper can be fully written by AI agents that are non-detectable by humans or robots. Yet I see little discussion and action on how to prepare for this in the academics. How will we differentiate between good and bad researchers next year when everyone will have access to tools that create top-quality research papers?
Perplexity Launches Labs Tool for Creating Reports, Dashboards, and Web Apps
https://www.perplexity.ai/labs

The News:
- Perplexity Labs enables Pro subscribers to generate complete projects including reports, spreadsheets, dashboards, and simple web applications through AI automation, potentially saving hours of manual work.
- The tool performs autonomous work for 10 minutes or longer, using deep web browsing, code execution, chart creation, and image generation to deliver structured outputs.
- Users can create interactive content such as financial dashboards with dropdown menus for different time periods, Sudoku spreadsheets, or web apps showing global time zones.
- All generated assets including charts, images, CSV files, and code are automatically organized in dedicated Assets and App tabs for easy download and sharing.
- The feature costs $20 per month as part of Perplexity Pro and is available on web, iOS, and Android platforms, with Mac and Windows apps coming soon.
What you might have missed: Just like with Manus.im, Perplexity Labs allows you to browse public projects created by other users over at https://www.perplexity.ai/labs. For example: Create a dashboard comparing the 5-year performance of a traditional stock portfolio versus an AI-powered portfolio that adapts to real-time market sentiment and macroeconomic trends
My take: If you have seen the Chinese AI agent Manus.im demos where they upload sales figures and ask Manus to “analyze it thoroughly with visualizations and recommend specific, data-driven strategies to boost next month’s sales by 10%?” then you know what Perplexity Labs is. You can upload documents to Perplexity, and ask it to do deep research on them, browse online for more information, and summarize the findings in detailed reports and web dashboards. But where Manus.im used Claude, Perplexity does not detail which LLM they use behind the scenes. If you regularly search or collect information from the Internet and want it easily presented in graph or interactive web style, then this might be just the tool for you.
UAE Becomes First Country to Provide Free ChatGPT Plus to All Residents

The News:
- The UAE partnered with OpenAI to provide free ChatGPT Plus subscriptions to all residents and citizens, eliminating the typical $20 monthly fee and making advanced AI tools accessible nationwide.
- The partnership falls under OpenAI’s “OpenAI for Countries” program, designed to help nations build sovereign AI capability while maintaining coordination with the U.S. government.
- Elon Musk attempted to interfere with the UAE-OpenAI deal by contacting G42 executives and warning that President Trump would not approve the agreement unless his xAI company was included as a partner.
- Musk directly called Sheikh Tahnoon bin Zayed, the UAE’s national security adviser and brother of the president, threatening to block the deal unless his AI startup received a role in the project.
- Despite Musk’s pressure campaign, the Trump administration approved the deal without including xAI, with White House officials noting Musk’s concerns about the agreement favoring his longtime rival Sam Altman.
My take: Giving everyone access to ChatGPT Plus is something I wish more countries would consider. My own kids use ChatGPT Plus every day in their homework, and all their friends too. As I wrote a few weeks ago the use of ChatGPT has proven to significantly increase student grades and results, which means that the better ChatGPT gets the better the students using it will be in school. This will create a significant gap between those who can afford it and those who cannot. In Sweden, our schools cost around 353 billion SEK every year. We have around 2 million people below the age of 20, so if we were to give everyone below 20 years a ChatGPT Plus subscription it would cost less than 400 MSEK each year. I believe it would make a huge difference and greatly democratize the use of AI in our society. It’s just too bad our national AI Strategy was moved to 2026.
Google Introduces Stitch to Generate Editable UI Code from Text or Images
https://developers.googleblog.com/en/stitch-a-new-way-to-design-uis
The News:
- Google launched Stitch, an AI-powered tool that converts text prompts and images into functional UI designs and frontend code within minutes, potentially saving developers hours of manual design work.
- The tool runs on Gemini 2.5 Pro and accepts English text descriptions or visual inputs like wireframes, sketches, and screenshots to generate multiple interface variants.
- Stitch produces clean HTML and CSS code that can be exported directly to applications or transferred to Figma as editable layers, not static images.
- Users can specify design preferences including color palettes, layouts, and user experience flows through natural language prompts.
- The tool generates multiple design variants for each request, allowing developers to experiment with different styles and layouts without starting from scratch.
What you might have missed: Google Stitch is the successor of Galileo AI, which was acquired by Google on May 20. The main difference is that Stitch (the new name for Galileo) is now using Gemini models internally.
My take: If you are currently using Lovable, Figma’s Make, and Vercel’s v0 to generate web code from prompts or images, you know more or less what to expect from Stitch. User feedback has so far been mixed. Some users thought the Figma integration works well since it’s being imported as editable layers rather than static images, however lots of users report significant consistency issues across generated screens. Maybe Google thought Galileo AI (the company they bought) would perform much better if they just switched to Gemini models, or maybe they just felt they needed a product to get on board the AI design product category quickly and companies like Lovable was too expensive to buy.
Mistral Launches Agents API and Codestral Embed for Enterprise Development
https://mistral.ai/news/agents-api
https://mistral.ai/news/codestral-embed
The News:
- Mistral AI released its Agents API last week, enabling developers to build autonomous AI agents that execute complex tasks using external tools and maintain persistent memory across conversations.
- The API includes five built-in connectors: Python code execution in secure sandboxes ($30 per 1,000 calls), web search capabilities ($30 per 1,000 calls), image generation powered by Black Forest Lab FLUX1.1 ($100 per 1,000 images), document library access with RAG functionality, and Model Context Protocol (MCP) tools for external system integration.
- Web search integration dramatically improves performance, with Mistral Large accuracy jumping from 23% to 75% and Mistral Medium from 22.08% to 82.32% on the SimpleQA benchmark.
- The API supports multi-agent orchestration, allowing specialized agents to hand off tasks to each other through dynamic coordination, enabling complex workflows across multiple services.
- Mistral simultaneously launched Codestral Embed, its first embedding model, priced at $0.15 per million tokens and designed for retrieval-augmented generation in coding applications.
- Codestral Embed outperforms competitors including Voyage Code 3, Cohere Embed v4.0, and OpenAI’s Text Embedding 3 Large on benchmarks like SWE-Bench and GitHub’s Text2Code.
My take: If you are currently using Mistral’s models like Devstral (Mistral’s agentic LLM for software engineering tasks), Mistral Large, Mistral OCR, Pixtral OCR or Codestral (Mistral’s code model), then maybe going all-in on Mistral and adopting their new Agents API is the right choice. User feedback on Devstral has so far been quite poor, and to me it looks like Mistral is trying to do a bit too many things for a relatively small company of just 150 employees. As I wrote in my last newsletter it’s also nearly impossible to get in touch with them, so I would not recommend going all-in on Mistral right now, at least until they have grown a bit larger and have their customer interaction sorted. Codestral Embed is however very interesting. It’s a specialized model to create vector databases for source code. If you have a large code database and would like to index it and find things in it, Codestral Embed should probably be at the top of your list. It outperforms many other solutions, is cheap to use, and works well with development frameworks like LangChain for orchestrating RAG pipelines.
Google Open Sources LMEval Framework for Cross-Provider AI Model Benchmarking
The News:
- Google released LMEval, an open-source framework that standardizes evaluation of large language models across different providers, addressing the challenge of comparing models from OpenAI, Anthropic, Google, and others using inconsistent APIs and formats.
- The framework integrates with LiteLLM to provide unified compatibility with major providers including Google, OpenAI, Anthropic, Ollama, and Hugging Face, allowing developers to define benchmarks once and run them across multiple models with minimal code changes.
- LMEval supports multimodal evaluation for text, images, and code, handles various scoring metrics from boolean questions to free-form generation, and includes safety detection for identifying when models give evasive responses to avoid problematic content.
- The system features incremental evaluation that runs only necessary tests for new models or questions rather than complete benchmark suites, reducing time and computational costs through its multi-threaded engine.
- Results are stored in a self-encrypting SQLite database to protect benchmark data from crawling while maintaining local accessibility, and include LMEvalboard visualization tool with radar charts and drill-down analysis capabilities.
My take: There are a few cross-provider benchmarks available already, such as Harbor Bench and EleutherAI’s LM Evaluation Harness. None of them support multimodal models and incremental evaluation capabilities, so this is where LMEval comes in. As models become larger and more complex, we need to continue developing the test benchmarks to evaluate progress, and releasing them as open source like LMEval is the right way to go. I believe we will see LMEval as reference benchmark for all future models being released in 2025.
Meta Restructures AI Division Into Two Focused Teams
https://www.axios.com/2025/05/27/meta-ai-restructure-2025-agi-llama

The News:
- Meta split its AI organization into two specialized teams to accelerate product development and compete more effectively with OpenAI and Google in the artificial intelligence race.
- The AI Products team, led by Connor Hayes, handles consumer-facing features including Meta AI assistant, AI Studio, and AI integrations across Facebook, Instagram, and WhatsApp.
- The AGI Foundations unit, co-led by Ahmad Al-Dahle and Amir Frenkel, focuses on long-term research including Llama language models and capabilities in reasoning, multimedia, and voice technology.
- The company’s FAIR research unit remains separate, though one multimedia team moved to the new AGI Foundations group.
My take: Following the debacle which was the Llama 4 release, where Meta’s Head of AI Research departed just the week before release, this restructuring is probably a good thing. Meta almost caught up with the competition last year with Llama 3, but following the disastrous launch of Llama 4 this year they are now far behind again. Hopefully this new organization will allow the AGI Foundations team more freedom so they can catch up with the latest and greatest closed-source models.
New York Times Signs First AI Licensing Deal with Amazon
https://www.axios.com/2025/05/30/nyt-amazon-ai-licensing-deal

The News:
- The New York Times signed a multi-year AI licensing agreement with Amazon, marking the newspaper’s first commercial deal allowing a tech company to use its editorial content for AI training and integration.
- The deal grants Amazon access to content from The New York Times, NYT Cooking recipes, and The Athletic sports coverage for use across Amazon’s AI-powered products and services.
- Amazon will display real-time summaries and short excerpts of Times content through products like Alexa voice assistant, with proper attribution and direct links back to Times products.
- The agreement allows Amazon to use the licensed content for training its proprietary foundation models, providing the tech giant with high-quality journalistic data for AI development.
My take: In December 2023 The New York times sued OpenAI for using “millions of articles” to train AI models without permission or compensation. The Times spent $4.4 million in just the first quarter related to this lawsuit. While other publishers like The Atlantic, News Corp, and Vox Media have established AI licensing agreements with several companies, Amazon’s deal with the Times represents a strategic approach where the newspaper pursues legal action against some AI companies while partnering commercially with others. If OpenAI had played it nice from the start maybe the situation would look different, or maybe the Times did not want to partner with OpenAI at all even from the start.
Opera Announces Neon, First AI Agentic Browser with Autonomous Task Execution
https://blogs.opera.com/news/2025/05/opera-neon-first-ai-agentic-browser
The News:
- Opera announced Neon, an AI-powered browser that automates web tasks and creates content independently, targeting users who want to streamline repetitive online activities and content creation.
- The browser features three core functions: Chat for web searches and contextual information, Do for automating tasks like form filling and booking travel, and Make for creating websites, games, and code snippets.
- Neon’s Browser Operator AI agent runs locally on users’ devices and understands web pages through DOM tree analysis rather than screen recording, preserving privacy while automating shopping, reservations, and form completion.
- The Make feature operates through cloud-based virtual machines hosted on Opera’s European servers, allowing AI agents to continue working on projects even when users go offline.
- Opera positioned Neon as a premium subscription product with waitlist access for early adopters, though pricing details remain undisclosed.
My take: This is not really a release, but an announcement that users can now apply for a waitlist for early access. There is still no release date or pricing details beyond it being a “premium subscription product”. There are also no user reviews or hands-on experiences, everything we have so far are official press releases and announcements from Opera. If you are using Opera browser today and are curious on what the company is cooking, go sign up on the wait list. The rest of you can safely ignore this press release and wait until the final product is out and tested.
Read more: