
The gap between EU and US when it comes to AI development just reached a critical point. Last week the US launched its AI Action Plan, which outlines an “unapologetic strategy” that prioritizes speed, deregulation, and market dominance over regulatory compliance. The Plan outlines over 90 Federal policy actions targeting infrastructure, innovation and global leadership. Meanwhile, the EU continues implementing its AI Act, a comprehensive regulatory framework that imposes strict guardrails and penalties of up to 7% of global revenue for companies using AI systems that have “unacceptable risk.” However, the technical standards needed for compliance still remain unfinished. Most notably, the European Commission’s guidance on general-purpose AI models (originally scheduled for release in May 2024) has been indefinitely delayed and the final technical specifications won’t be complete until early 2026. In stark contrast, the US AI Action Plan took effect immediate through an executive order.
For everyone working with AI, the launch of the US AI Action plan is mostly good news. AI models will continue to develop at record speed, and I have no doubt that we will reach tipping points where most office tasks can be done by an agentic AI system within 2-3 years. The main challenge I see is that every company in the EU will be increasingly dependent on the US for driving their business. With the current AI policies rolling out in the EU it will be close to impossible to stay in the lead for companies doing their own AI development. While Mistral is doing ok, they are still behind Google and OpenAI in terms of raw performance, and that performance gap will grow enormous in the coming years when the US really pushes the power investments required by next generation models. So while the EU will still be a great place to work WITH AI, it will be a challenging environment if you want to work with developing NEW AI.
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2025 Week 31 on Spotify
THIS WEEK’S NEWS:
- Trump Administration Launches AI Action Plan to Boost Data Centers and Tech Exports
- Cursor Releases Bugbot for Automated Code Reviews
- GitHub Spark Enters Public Preview for AI-Powered Web App Development
- Manus AI Shares Context Engineering Techniques for Building Production AI Agents
- Google Launches Backstory AI Tool to Verify Image Authenticity
- Google Gemini 2.5 Pro Achieves Gold Medal Standard on Mathematical Olympiad
- Google DeepMind Introduces AI Model for Ancient Roman Inscription Analysis
- Google Gemini 2.5 Adds Conversational Image Segmentation Using Natural Language
- Runway Releases Act-Two Motion Model with Full-Body and Face Tracking
- Alibaba Releases Qwen3-Coder: Most Agentic Open Source Coding Model to Date
- Alibaba Launches Qwen3-MT Machine Translation Model Supporting 92 Languages
Trump Administration Launches AI Action Plan to Boost Data Centers and Tech Exports
https://www.wsj.com/tech/ai/trump-pledges-moves-to-stimulate-ai-use-and-exports-b85b0b15

The News:
- The Trump administration released a comprehensive AI “action plan” containing over 90 policy actions designed to accelerate American AI development and global competitiveness.
- The plan focuses on three core pillars: boosting AI innovation, building domestic AI infrastructure, and leading global AI diplomacy and security.
- Key regulatory changes include cutting bureaucratic obstacles for data center construction, speeding up permitting processes, and removing barriers that slow AI infrastructure development.
- The administration will restrict exports of sensitive AI technologies while promoting “full-stack” AI technology packages from chips to software to allied nations.
- Federal agencies must ban procurement of AI systems deemed ideologically biased, with requirements that AI firms receiving federal contracts maintain political neutrality.
- The plan includes evaluating Chinese AI models for alignment with “Chinese Communist Party talking points and censorship” and blocking “adversarial technology” from U.S. AI infrastructure.
My take: This plan is a sharp departure from the Biden’s approach, which emphasized AI safety regulations through a 2023 executive order that Trump revoked the same day he took office. While Biden focused on developing safety standards for federal AI use, Trump’s strategy prioritizes rapid development above everything else. Industry feedback has so far been positive, and I personally think this is what it takes to continue improving AI models at the rate we are currently moving. Will the AI action plan have negative consequences? Maybe. But the big question is if the benefits from developing AI at this speed greatly outweighs the negatives. We will have to wait a few years for the answer to that one.
Cursor Releases Bugbot for Automated Code Reviews
https://cursor.com/en/blog/bugbot-out-of-beta
The News:
- Cursor has launched Bugbot, an AI-powered code review agent that automatically analyzes pull requests to identify logic bugs, edge cases, and security issues while maintaining a low false positive rate.
- During its beta phase, Bugbot reviewed over 1 million pull requests and found 1.5 million issues, with more than 50% of flagged bugs resolved before merging.
- Users can define custom coding standards and project-specific guidelines through BUGBOT.md files, and directly fix issues in the Cursor IDE or launch background agents with one click.
- According to Cursor users have reported significant time savings, with one noting that Bugbot helps give back 40% of time spent on manual code reviews, allowing engineers to focus on higher-value work.
“We’ve had PRs approved by humans, and then Bugbot comes in and finds real bugs afterward. That builds a lot of trust.”
Kodie Goodwin, Senior Engineering Manager of AI Tools, Discord
My take: There are two things language models excel at when it comes to programming today: finding logical bugs in source code that are difficult to spot, and going through large amounts of debug logs to quickly find issues in production code. I expect most software development companies to integrate AI for code review and pull requests during the year, where autonomous AI programming will probably not rollout on a large scale until 2026.
Also, as is now typical for Cursor, when they released Bugbot last week they launched a separate pricing model of $40 per month, which they then quickly removed due to negative feedback. They now changed it so Bugbot is available in the Pro license, but they did not post anything about limits and how much usage you can expect from it. Also, having Bugbot detect 1.5 million issues in 1 million pull requests is a lot of bugs detected, but it kind of makes you wonder on what code they actually did this test. Maybe it was based on their own fully AI-generated content just spamming code for review.
GitHub Spark Enters Public Preview for AI-Powered Web App Development
https://github.blog/changelog/2025-07-23-github-spark-in-public-preview-for-copilot-pro-subscribers/
The News:
- GitHub released Spark in public preview, an AI-powered platform that creates complete web applications from natural language descriptions, designed to make app development accessible to non-programmers while providing rapid prototyping for experienced developers.
- The tool uses Claude Sonnet 4 to generate TypeScript and React applications with both frontend and backend components, includes automatic hosting and deployment without setup requirements, and provides built-in data storage through a managed key-value store.
- Copilot Pro+ subscribers receive 375 messages per month and can iterate on their apps using natural language prompts, visual controls, or traditional coding with GitHub Copilot assistance in connected Codespaces.
- Spark integrates with GitHub Models to provide access to LLMs from OpenAI, Meta, DeepSeek, and xAI without API key management, automatically generating prompts for AI features and handling model inference.
- Projects can be exported to full GitHub repositories with Actions and Dependabot integration, and the platform includes a themable design system with pre-built UI components for polished appearances.
My take: A GitHub Copilot Pro+ subscription is $39 per month and gives you 1500 premium model requests per month, which is A LOT. And now you also get access to Spark. And if you are a GitHub Copilot Pro+ user, GitHub does not train their models on your data. Spark is a direct stab at Lovable, which now cost $50 per month if you do not want Lovable to train AI models on your data, and also only includes 100 monthly credits (with an additional 5 daily credits per month). Expect the market for these prompt building apps to shift around a lot in the coming years, and don’t sign up for yearly subscriptions if you can avoid it.
Read more:
Manus AI Shares Context Engineering Techniques for Building Production AI Agents
https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
The News:
- Manus AI published practical insights on context engineering for AI agents, detailing techniques that allow development teams to ship improvements in hours instead of weeks. The Chinese AI company’s approach focuses on prompt and context optimization rather than model fine-tuning, keeping their product independent from underlying model changes.
- KV-cache hit rate emerges as the most critical performance metric, with cached tokens costing $0.30/MTok versus $3.00/MTok for uncached ones using Claude Sonnet – a 10x cost difference. Manus reports an average input-to-output token ratio of 100:1, making cache optimization essential for economic viability.
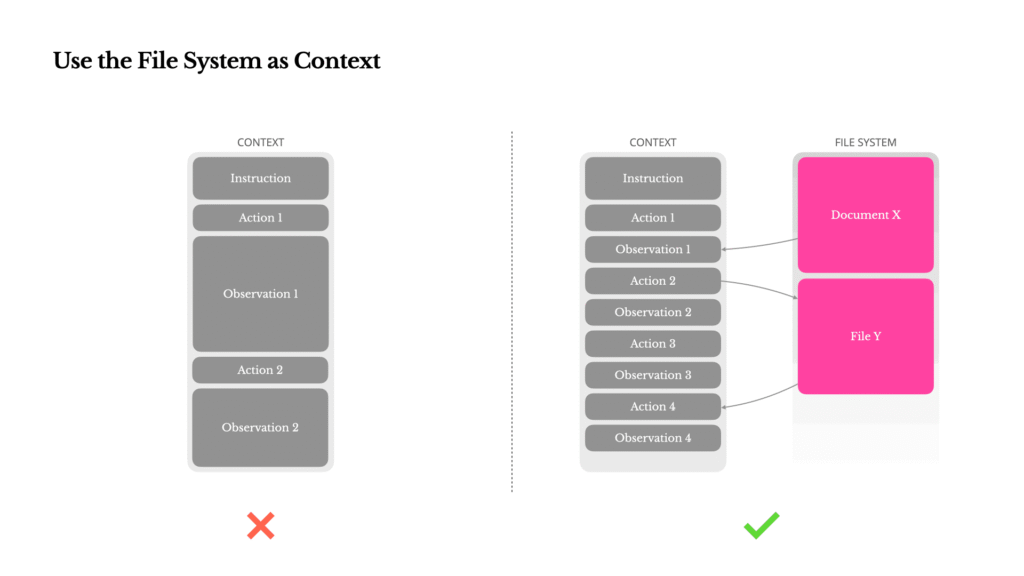
- The company uses file system storage as unlimited agent memory, treating it as “structured, externalized memory” where agents write and read files on demand. This approach handles cases where web pages or PDFs exceed context limits while maintaining restorable compression strategies.
- Tool management involves masking rather than removing capabilities mid-iteration to preserve cache coherence. Manus constrains action selection through logits manipulation and uses consistent naming prefixes like “browser” and “shell” for efficient tool grouping.
- Agents deliberately create and update “todo.md” files to manipulate attention and prevent goal drift during complex 50-step average task sequences. This recitation technique pushes objectives into recent attention spans, reducing “lost-in-the-middle” issues.
- Error preservation strategy keeps failed actions and stack traces in context rather than cleaning them up, allowing models to learn from mistakes and avoid repeating similar errors. The team views error recovery as a key indicator of genuine agentic behavior.
My take: I love articles like this, and if you have the time and have an interest in building efficient agentic AI systems then this article is a must read. It also reflects well with my own experience working with Claude Opus 4 for agentic coding. Keeping task lists always up to date to keep attention in front is critical to prevent focus drift on long complex tasks.
Google Launches Backstory AI Tool to Verify Image Authenticity
https://deepmind.google/discover/blog/exploring-the-context-of-online-images-with-backstory

The News:
- Google introduced Backstory, an experimental AI tool that uses Gemini to help users determine image authenticity and context. The tool addresses growing concerns about AI-generated content and misinformation by providing comprehensive analysis of images found online.
- Backstory detects whether images are AI-generated, tracks previous online usage across websites, and identifies digital alterations. The tool generates readable reports summarizing its findings for each analyzed image.
- The tool examines not just AI generation but also how images have been used across the internet and whether they’ve been presented out of context.
- Google is currently testing Backstory with image creators and information professionals through a gated waitlist. The company plans to gather feedback throughout the year to improve the technology before wider release.
My take: Google’s Backstory builds on their previous image verification tools such as the “About This Image” feature and SynthID watermarking technology. And like those tools the effectiveness of Backstory heavily depends on if the original creators included proper metadata with their material, something most images lack today. But maybe this is where we need to change the way we work – maybe we need to be more disciplined when uploading our photos so they can be tracked accordingly. Because at the rate the AI slop is developing we need AI filters as soon as possible.
Google Gemini 2.5 Pro Achieves Gold Medal Standard on Mathematical Olympiad
https://arxiv.org/abs/2507.15855

The News:
- Google’s Gemini 2.5 Pro successfully solved 5 out of 6 problems from the International Mathematical Olympiad (IMO) 2025, achieving a gold medal standard score through specialized pipeline design and prompt engineering.
- The model used a self-verification pipeline that broke problem-solving into multiple steps, with each step receiving up to 32,768 thinking tokens to allow comprehensive analysis and solution refinement.
- UC Berkeley researchers published the methodology in an arXiv paper, emphasizing they used freshly released IMO 2025 problems to avoid data contamination, ensuring the model’s performance reflected genuine reasoning capabilities rather than memorized solutions.
- Google made the system prompt and methodology publicly available, with the complete code repository accessible on GitHub for researchers to replicate and build upon the approach
My take: It’s interesting that both Google and OpenAI achieved this amazing milestone just days within each other. What I appreciate with Google’s approach is that (1) they waited with announcing the press release for a few days with respect to the human participants at the IMO, and (2) they published both detailed methodology as well as their system prompts online, where OpenAI released nothing. And while Google says they did it with Gemini 2.5 Pro, the pipelines used were made specifically for this challenge. But overall this is a significant milestone for AI progress, and it really shows where things are going in the coming year.
Read more:
Google DeepMind Introduces AI Model for Ancient Roman Inscription Analysis
https://deepmind.google/discover/blog/aeneas-transforms-how-historians-connect-the-past

The News:
- Google DeepMind launched Aeneas, the first AI model designed to help historians analyze and restore ancient Roman inscriptions, providing time-saving assistance with the laborious process of contextualizing fragmentary texts.
- The tool restores missing text with 73% accuracy for gaps up to ten characters, can date inscriptions within a 13-year timeframe, and identifies geographic origins with 72% accuracy across 62 ancient Roman provinces.
- Aeneas processes both text and images, drawing from a dataset of over 176,000 Latin inscriptions spanning from the seventh century BC to the eighth century AD across the former Roman Empire.
- The system identifies textual parallels by comparing linguistic similarities, standardized formulas, and historical patterns across thousands of inscriptions in seconds, accelerating a process that previously required extensive manual research.
- Google made the tool freely available at predictingthepast.com and open-sourced the code and dataset to encourage broader research collaboration.
My take: Aeneas is based on a previous system by Google called Ithaca, which focused Greek texts. What makes Aeneas so interesting is that it uses rich embeddings that capture historical and linguistic patterns beyond exact wording. User feedback has so far been overly positive. Historians reported the AI’s context suggestions were useful in 90% of cases and improved their confidence in key tasks by 44%. As with programming however, the best results occurred when historians and Aeneas worked together. Charlotte Tupman from the University of Exeter described the model as “a revolutionary research instrument” that enables scholars to “uncover connections within their data that might otherwise be missed or require significant time to discover”.
Read more:
- Google’s new AI deciphers missing Latin words in ancient Roman inscriptions | The Independent
- A.I. May Be the Future, but First It Has to Study Ancient Roman History – The New York Times
Google Gemini 2.5 Adds Conversational Image Segmentation Using Natural Language
https://developers.googleblog.com/en/conversational-image-segmentation-gemini-2-5

The News:
- Gemini 2.5 now segments images using natural language descriptions instead of single-word labels, allowing users to specify complex queries like “the person holding the umbrella” or “the third book from the left”.
- The model handles five types of queries: relational understanding (“the car that is farthest away”), ordering (“third book from the left”), comparative attributes (“most wilted flower”), conditional logic (“food that is vegetarian”), and abstract concepts (“damage” or “a mess”).
- Users can identify objects through written text labels in images using Gemini’s OCR capabilities, and the system supports queries in multiple languages.
- Applications include creative workflows where designers can select elements like “the shadow cast by the building”, workplace safety monitoring to “highlight any employees on the factory floor not wearing a hard hat”, and insurance damage assessment to “segment the homes with weather damage”.
- Developers can access the feature through a single API without training separate segmentation models, using the gemini-2.5-flash model with JSON output format.
My take: Image segmentation is a key component for fully automatic image processing agents. Previous open-vocabulary models could segment objects using specific labels like “blue ski boot”, but required exact noun matches. With Gemini 2.5 you can now match using complex descriptive phrases and describe spatial relationships between objects. I see this as a good complement to Meta Segment Anything 2 (SAM 2), where SAM 2 is ideal for real-time processing and Gemini 2.5 excels at asynchronous cloud-based processing.
Runway Releases Act-Two Motion Model with Full-Body and Face Tracking
https://help.runwayml.com/hc/en-us/articles/42311337895827-Creating-with-Act-Two

The News:
- Runway introduced Act-Two, a new motion transfer model that animates characters using driving performance videos, allowing creators to transfer realistic motion, speech, and expressions from human actors to digital characters.
- The system costs 5 credits per second with a 3-second minimum charge and supports video durations up to 30 seconds at 24fps across multiple aspect ratios including 16:9, 9:16, and 1:1.
- Act-Two works with both character images and videos as inputs, automatically adding environmental motion like handheld camera shake when using images, while preserving original camera movement when using videos.
- When using character images, creators can control hand and body movements through gesture settings, with the model transferring poses and bodily motion from the performance video to the animated character.
- The model requires a single subject framed from waist up in well-lit conditions with visible facial features, and performance videos should avoid cuts or interruptions for optimal results.
My take: If you remember Runway Act-One that was basically a video to AI generated animation system that required users to sit on a chair since it could not process movement. Act-Two is the next generation that captures not only facial movement but movement from the waist up. If you have a minute go check their launch video, it’s quite impressive that all those small video clips can be generated from just a smartphone video and a reference image.
Read more:
Alibaba Releases Qwen3-Coder: Most Agentic Open Source Coding Model to Date
https://qwenlm.github.io/blog/qwen3-coder
The News:
- Alibaba’s Qwen team released Qwen3-Coder-480B-A35B-Instruct, a 480-billion parameter Mixture-of-Experts model with 35 billion active parameters designed for autonomous coding tasks. The model reduces development time by automating complex coding workflows that traditionally require multiple manual steps.
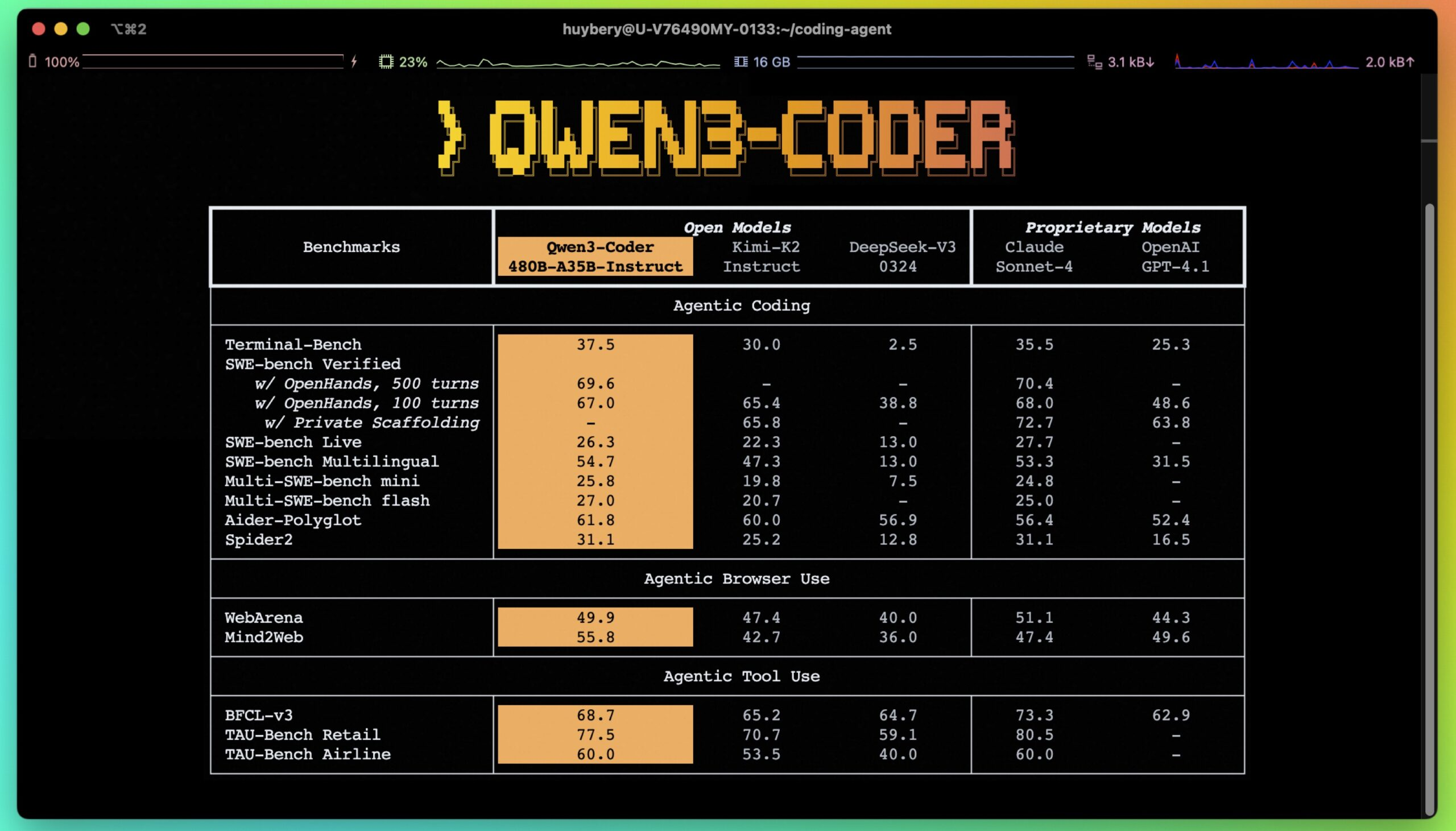
- The model achieves state-of-the-art performance among open models on agentic coding benchmarks, matching Claude Sonnet performance while supporting 256,000 tokens natively and extending to 1 million tokens. It scores 61.8% on Aider Polyglot and over 85% on SWE-Bench Verified, outperforming DeepSeek’s 78% and Moonshot K2’s 82%.
- Qwen3-Coder supports 358 programming languages and includes repository-scale understanding capabilities. The model features specialized function calling for integration with tools like Qwen Code CLI and CLINE, enabling autonomous task orchestration without human intervention.
- The release includes Qwen Code, an open-source command-line tool forked from Gemini CLI with customized prompts and function calling protocols specifically designed for agentic coding workflows. This tool integrates seamlessly with existing developer environments and CI/CD pipelines.
My take: In benchmarks, Qwen3-Coder outperforms all previous open source models for programming. On the SWE-Bench Verified benchmark it achieved 85% compared to DeepSeek’s 78% and Moonshot K2’s 82%, approaching Claude Sonnet 4’s 86% performance. User feedback so far has been quite mixed, the model seems to perform very well in some cases, but much worse in other. Things like “Qwen-3 Coder frequently modified tests to pass instead of fixing bugs” really makes you want to evaluate the model deeply before deciding to integrate it into your toolchain. For me personally these coding benchmarks are all pretty useless, what really matters is how good the model is at executing your exact and detailed instructions. And that is where Claude 4 Opus wins for me, I know how to work with it to get good results, and if I just keep my process going I am never surprised that it did not deliver as expected.
Read more:
Alibaba Launches Qwen3-MT Machine Translation Model Supporting 92 Languages
https://qwenlm.github.io/blog/qwen-mt
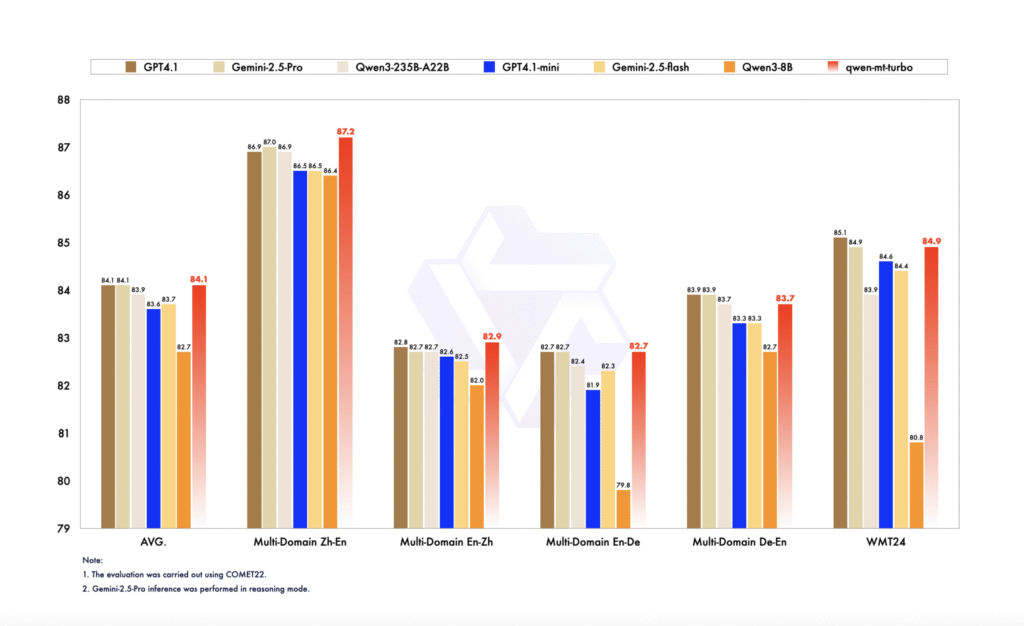
The News:
- Alibaba released Qwen-MT, a machine translation model supporting 92 languages and dialects that covers over 95% of the global population, built on the Qwen3 architecture with reinforcement learning techniques.
- The model achieves translation costs as low as $0.5 per million output tokens through a lightweight Mixture of Experts (MoE) architecture, approximately one-tenth the cost of similar products.
- Automatic evaluation shows Qwen-MT outperforms similarly sized models including GPT-4.1-mini, Gemini-2.5-Flash, and Qwen3-8B on multi-domain translation benchmarks.
- On Chinese-English and English-German translation tasks, the model achieved scores up to 87.2, surpassing GPT-4.1’s score of 86.9.
My take: While the Qwen3 family of models (Qwen3-8B, Qwen3-14B) are released under Apache 2.0 open source license, Qwen-MT is closed-source and proprietary. So if you want to use it you need to access it through API to the Alibaba cloud. Still this is a very interesting model with very high performance and very low cost, so if you have the need for machine translations at low cost, especially to and from Chinese, this could be your top choice.
Read more: