
Last week OpenAI launched GPT-5, their new “system of models”. Unlike GPT-4 and GPT-4o, GPT-5 is not a model but is instead a system with a smart router (OpenAI calls it the “autoswitcher”) that will try to direct your message to the right model for the task. Ask it to solve a math problem – and your request will be sent to the thinking model. Ask it about a political question, and your request is sent to a large model without thinking. And ask it to process a document or automate a simple task, then your request is sent to a cheap “mini” model. The problem was that the router didn’t really work as expected during launch, so social media quickly filled up with AI experts shocked over how bad the new GPT-5 model performed. Sam Altman later clarified on X that “the autoswitcher broke and was out of commission, and the result was GPT-5 seemed way dumber”. They also did not show if the thinking model was used or not in the interface, something they fixed over the weekend.
I have run GPT-5 quite a lot over the weekend together with Claude 4.1 Opus, and have asked them to review each other’s code and come up with code proposals. GPT-5 performed surprisingly well when it comes to noticing details in large documents and making things organized. Where Claude Opus is great at producing large volumes of highly specified source code, GPT-5 was actually amazingly good finding things to improve. I have previously used Gemini 2.5 Pro as my “code structure” buddy but based on my early results I will switch to GPT-5 in the next week. Be prepared however that the GPT-5 system can be quite difficult to prompt to get it to perform right, so if you plan to use it I highly recommend you read through the official GPT-5 prompting guide by OpenAI. You need to spend some time to learn the system and the models to get them to perform the best.
Last week OpenAI also announced they are giving access to ChatGPT Enterprise to Federal Agencies for just $1 per year. The interesting thing here is that they had done a pilot program where people saved up to 95 minutes per day, with 85% of participants reporting positive experiences. The problem is that while 95 minutes sounds like a lot of time, in practice it is maybe two tasks per hour that takes 6 minutes less to perform. And is this really time saved, or is it just an extra coffee break for the employee? Calculating ROI for Generative AI today where the tools are reactive and needs strict guidance is actually quite hard unless you enroll agentic AI solutions. I am however quite confident that these savings will be much larger in just 6-12 months, so if the saving today is 95 minutes maybe it’s 4-5 hours per day in a year. Then the ROI is much easier to calculate. Until then if you really want to save money from your AI investment, agentic AI solutions is where the big savings are today.
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2025 Week 33 on Spotify
THIS WEEK’S NEWS:
- Google DeepMind Releases Genie 3 AI Model That Creates Interactive 3D Worlds From Text
- ElevenLabs Launches AI Music Generator with Commercial Licensing
- OpenAI Releases GPT-5 Amid Technical Launch Issues
- OpenAI Launches gpt-oss Open-Weight Models Under Apache 2.0 License
- OpenAI Offers Federal Agencies ChatGPT Enterprise for $1 Per Year
- Anthropic Releases Claude Opus 4.1 with Enhanced Coding Performance
- Apple Researchers Develop Multi-Token Prediction to Speed Up LLM Responses
- Google Releases Jules AI Coding Agent with Gemini 2.5 Integration
- Cursor Releases CLI Terminal Coding Agent in Early Beta
Google DeepMind Releases Genie 3 AI Model That Creates Interactive 3D Worlds From Text
https://deepmind.google/discover/blog/genie-3-a-new-frontier-for-world-models

The News:
- Google DeepMind launched Genie 3, an AI world model that generates interactive 3D environments from single text prompts, creating unlimited training simulations for AI agents and robots.
- The system produces playable worlds at 720p resolution and 24 frames per second in real time, maintaining visual consistency for several minutes compared to Genie 2’s 10-20 second duration.
- Users can navigate these environments interactively and modify them through additional text commands, such as changing weather conditions or adding objects while exploring.
- The model features “world memory” that preserves user actions and environmental changes, allowing painted walls or moved objects to persist when users return to previously visited areas.
- Genie 3 enables “promptable world events” where users can instantly add elements like other characters, vehicles, or unexpected scenarios to test AI agent responses.
- Current limitations include restricted action spaces, interaction durations of only a few minutes, imperfect geographic accuracy, and inability to support multiple agents in the same environment.
My take: This is one of the most exciting AI news this year – if you have two minutes go watch their launch video, this really gives an exciting glimpse into a possible future where all content you see on screen is created in real-time by smart AI models. This model can generate any 3D world you can imagine, which you can then move around in freely and interact with it. The world even has memory, so if you move objects or interact with things it will persist state. This is one of those things that’s hard to describe and has to be seen.
Read more:
- Genie 3: Creating dynamic worlds that you can navigate in real-time – YouTube
- DeepMind thinks its new Genie 3 world model presents a stepping stone toward AGI | TechCrunch
ElevenLabs Launches AI Music Generator with Commercial Licensing
The News:
- ElevenLabs released Eleven Music, an AI service that creates studio-quality music from text prompts across multiple languages and genres. The service costs $0.50 per minute of generated audio and represents the first AI music generator with comprehensive commercial licensing.
- The company secured partnerships with Merlin Network and Kobalt Music Group to train its AI model on licensed independent artist catalogs. These deals include opt-in requirements for artists and revenue sharing structures, ensuring participants benefit financially from AI training usage.
- Generated music can be used commercially in films, TV shows, podcasts, games, and advertisements. The service supports multiple languages including English, German, Spanish, and Japanese with customizable vocals, instrumentation, and song structure.
- The platform includes safeguards that prevent generation using specific artist names or copyrighted lyrics, addressing legal concerns that have led to lawsuits against competitors Suno and Udio.
- Artists represented by Merlin include Adele, Nirvana, Mitski, and Phoebe Bridgers, while Kobalt’s catalog features Beck, Bon Iver, and Childish Gambino.
My take: I really like the licensing-first approach by ElevenLabs. Where competitors like Suno and Udio face ongoing lawsuits from record labels for training on copyrighted material without permission, ElevenLabs has secured legitimate licensing deals with commercial rights. The platform competes on quality with Suno, often outperforming it in vocal synthesis, using ElevenLabs’ amazing AI voice technology as a foundation. User feedback has been very positive, especially on the quality of the generated audio. Main negative aspect has been the price. If you produce video and need music to your productions this should be at the top of your list right now.
OpenAI Releases GPT-5 Amid Technical Launch Issues
https://openai.com/index/introducing-gpt-5

The News:
- OpenAI released GPT-5 as a unified AI system that automatically selects between fast responses and deeper reasoning modes based on query complexity, eliminating the need for users to manually switch between different models.
- The model delivers state-of-the-art performance on multiple benchmarks: 94.6% on AIME 2025 math problems, 74.9% on SWE-bench Verified coding tasks, 84.2% on MMMU multimodal understanding, and 46.2% on HealthBench Hard medical evaluations.
- GPT-5 reduces hallucinations by 45% compared to GPT-4o while demonstrating improved instruction following and reduced misleading behavior.
- The system includes three tiers: standard GPT-5 for all ChatGPT users, GPT-5 Pro for extended reasoning (available to Pro subscribers), and API access starting at $1.25 per million input tokens with GPT-5 Mini at $0.25/$2.00 and GPT-5 Nano at $0.05/$0.40.
- Sam Altman confirmed on X that OpenAI messed up the launch presentation, specifically addressing incorrect bar charts and admitting the routing system malfunctioned on launch day, making GPT-5 appear “way dumber” initially.
My take: Most people seem to have difficulty understanding that GPT-5 is a system of many models, not a single monolithic model like GPT-4o. I believe this was the right way to go, allowing models to grow in individual specializations and using a smart router that automatically involves one or many to answer questions based on the strengths of each model. I fully expect it will take a few weeks before the router works reliably, before then if you just know there are several models doing the work, think a bit how you prompt it and try different strategies to see how to get it work for you. My own experience with GPT-5 has been very positive, but right now this is a tricky model to prompt to get it to perform the best. I have no doubt OpenAI will solve this in the coming weeks, improving their system prompts and improving their router, but for now if you don’t consider yourself a prompting expert your experience with GPT-5 might even be worse than with GPT-4o.
Read more:
OpenAI Launches gpt-oss Open-Weight Models Under Apache 2.0 License
https://openai.com/index/introducing-gpt-oss

The News:
- OpenAI released gpt-oss-120b and gpt-oss-20b, two open-weight language models under Apache 2.0 license, marking the company’s first open-source models since GPT-2 in 2019. These models enable developers to download, modify, and deploy without API costs or cloud dependencies.
- The gpt-oss-120b model achieves near-parity with OpenAI’s o4-mini on core reasoning benchmarks while running efficiently on a single 80GB GPU. It activates 5.1B of its 117B total parameters per token using mixture-of-experts architecture.
- The smaller gpt-oss-20b model delivers similar results to o3-mini on common benchmarks and can run on edge devices with just 16GB memory. It activates 3.6B of its 21B parameters, making it suitable for local inference and laptop deployment.
- Both models support chain-of-thought reasoning with configurable effort levels, tool use, and structured outputs. They handle 128k context lengths and excel at coding tasks, with gpt-oss-120b scoring 62.4% on SWE-bench Verified.
- Performance benchmarks show gpt-oss-120b achieved 63% accuracy on math reasoning tests, outperforming OpenAI’s o3 model by 11 points. It processes output at 260 tokens per second with 8.1 second first-token latency.
My take: I think the key here is that both models are quite easy to deploy. Just buy a modern Pro GPU with 80GB of RAM and you can run the 120b model, or buy a large gaming card and run the smaller 20b model. User feedback has been quite mixed, the models seem to perform well on some tasks, but much worse on others. I think it’s clear that these are models are not OpenAI use for themselves, and I think the actual use cases for them is not yet really clear. Still if you are running something like Qwen 3 today, then do check these models out, maybe they work well for your specific use case.
OpenAI Offers Federal Agencies ChatGPT Enterprise for $1 Per Year
https://openai.com/index/providing-chatgpt-to-the-entire-us-federal-workforce

The News:
- OpenAI partnered with the U.S. General Services Administration to offer ChatGPT Enterprise to all federal agencies for $1 per agency for one year, aiming to help government workers spend less time on administrative tasks.
- Federal agencies receive access to OpenAI’s most advanced frontier models through ChatGPT Enterprise, plus unlimited use of advanced features including Deep Research for an additional 60-day period.
- The company established a dedicated government user community with tailored training resources through OpenAI Academy, including custom training platforms and guided learning sessions.
- Security measures include data firewalls ensuring that federal employee inputs and AI responses are not used to train future model versions.
- OpenAI claims pilot programs showed federal employees saved an average of 95 minutes daily on routine tasks, with 85% of participants reporting positive experiences.
My take: I find it interesting how big of a resistance it can be in large organizations to invest in something like Generative AI, when almost every study shows that people save hours of work every week from using these tools. I think the main reason for the reluctancy is that it’s very difficult to measure the actual benefit. So let’s say a typical worked saves on average 95 minutes every day on routine tasks. First of all, this is not a single 95 minute time block, but maybe rather twenty 5-minute blocks saved during the whole day. This is what makes it so difficult to calculate ROI. Yes everyone is more happy since their work is easier, but the actual cost saving for the company is extremely difficult to measure. By giving out these tools for free it’s no longer a discussion about cost, it’s only about getting happier employees for free. And within a year I don’t think anyone will be able to do any office work at all without AI, so then the cost is no longer optional but a requirement.
Anthropic Releases Claude Opus 4.1 with Enhanced Coding Performance
https://www.anthropic.com/news/claude-opus-4-1

The News:
- Anthropic launched Claude Opus 4.1, an upgraded version of its flagship AI model that improves coding, research analysis, and autonomous task handling capabilities for developers and enterprises.
- The model achieved 74.5% on SWE-bench Verified, surpassing OpenAI’s o3 model at 69.1% and Google’s Gemini 2.5 Pro at 67.2% on real-world software engineering challenges.
- Features hybrid reasoning that allows users to choose between instant responses or extended thinking modes, with API users able to control “thinking budgets” to optimize costs.
- GitHub reports notable improvements in multi-file code refactoring, while Rakuten Group finds the model excels at pinpointing exact corrections within large codebases without introducing bugs.
My take: I have used Claude Opus 4 almost every day since May, and 4.1 is a much bigger update than the benchmarks show. The first release of Opus 4.0 (see my screenshot above) would often get stuck, and rather than accept that it could not find a way forward it either made things up or hacked or patched things just so it could compile, without reflecting much on why the issue was there in the first place. It just had this urge to not fail. I have not yet noticed this behavior with 4.1, it is much better at planning and following complex tasks. Still the code written by Claude Opus 4.1, the world’s best AI for coding, is maybe 70% of all times not optimal and need improvements. If you are used to working with LLMs this should come as no surprise. Sometimes it performs really well at the first try, but that’s very rare. So with this in mind I still would not recommend anyone to “vibe code” anything that will ever be used by anyone. Always inspect all code, tell the LLM what should be better, ask it to clarify things that you know can be improved, be clear in your instructions, and most important of all learn to know your model and how to prompt it for consistent results.
Apple Researchers Develop Multi-Token Prediction to Speed Up LLM Responses
https://arxiv.org/abs/2507.11851
The News:
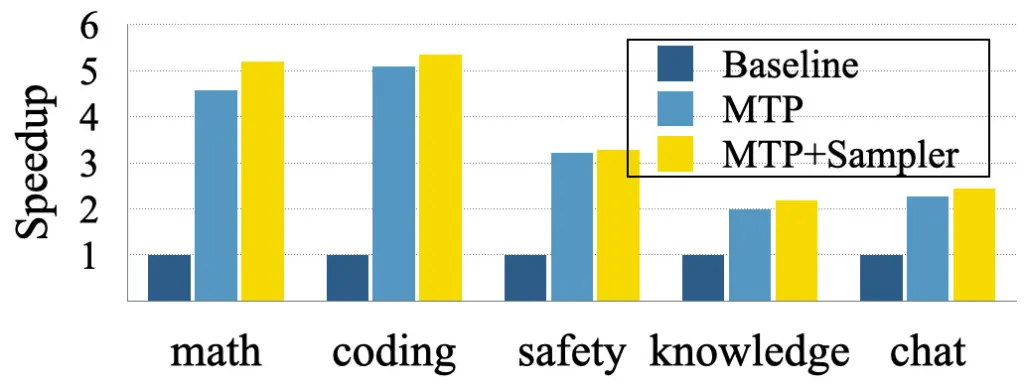
- Apple’s research team created a multi-token prediction (MTP) framework that enables large language models to generate multiple tokens simultaneously instead of one at a time, offering 2-5x speed improvements while maintaining output quality.
- Traditional LLMs use autoregressive decoding, generating text sequentially by predicting each token based on all previous tokens, which creates processing bottlenecks.
- The MTP framework inserts special “mask” tokens into prompts as placeholders, allowing the model to fill multiple positions at once with immediate verification against standard autoregressive results.
- esting on the open-source Tulu3-8B model showed average speedups of 2-3x for general tasks like Q&A and chat, with up to 5x acceleration for predictable domains like coding and mathematics.
- The technique uses “gated LoRA adaptation” to train models for speculative prediction of 8 additional tokens without degrading generation quality.
My take: This new technique could solve the main problem we have today when running models locally: speed. While 20 tokens per second might be OK for basic models that just generate text, for large thinking models that spend time in test-time compute 20 tokens is nothing and they will have you waiting minutes just for a simple query when they burn through thousands of tokens. A speed improvement up to 5x means Apple will be able to run thinking models locally on the iPhone, and I believe this is what they are aiming for in 2026.
Read more:
Google Releases Jules AI Coding Agent with Gemini 2.5 Integration
https://blog.google/technology/google-labs/jules-now-available

The News:
- Google launched Jules, an AI coding agent that autonomously performs coding tasks including writing tests, fixing bugs, building features, and updating dependencies, saving developers significant time on routine work.
- Jules runs asynchronously on secure Google Cloud virtual machines, allowing developers to assign tasks and focus elsewhere while the AI handles complex multi-step coding operations.
- The agent now uses Gemini 2.5 Pro’s advanced reasoning capabilities to create better coding plans and higher-quality code outputs.
- During beta testing, thousands of developers completed over 140,000 code improvements using Jules, demonstrating substantial adoption and practical utility.
- New features include GitHub issues integration, multimodal support for various input types, and the ability to reuse previous setups for faster task execution.
- Three pricing tiers are available: free introductory access (15 daily tasks, 3 concurrent), Google AI Pro at $20/month (5x higher limits), and Google AI Ultra (20x higher limits).
My take: I have used Gemini 2.5 Pro the past months for testing out different coding strategies – I typically ask both Claude 4 Opus and Gemini the same questions. Gemini 2.5 is sometimes able to pick out more details from the source code than Claude 4 Opus thanks to its much larger context window, but most often it actually finds issues or proposes solutions that are not correct. It also tends to greatly overcomplicate even simple topics, so if you just “let it loose” you well end up with source code that’s in such bad shape you will never be able to stabilize it. So while it sounds good in theory to run something like Jules fixing things in your code base, my quite extensive experience is that these models are not ready to let loose on production level source code yet. They get it wrong more times than they get it right, but if you take the time to steer them and correct them, you will still be able to develop source code 3-10 times faster than you can do today with much higher quality too.
Cursor Releases CLI Terminal Coding Agent in Early Beta
The News:
- Cursor CLI brings AI coding assistance directly to the terminal as a terminal-based agentic coding agent, allowing developers to switch seamlessly between command-line and editor-based workflows without requiring the graphical interface.
- The CLI provides full control from the terminal with inline code review capabilities, real-time steering of the agent, and customization options through rules, AGENTS.md, and Model Context Protocol (MCP).
- Developers can choose from multiple cutting-edge AI models including GPT-5, Claude 4, Sonnet, Opus, and Gemini, with automatic access to the latest models as they become available.
- Installation requires a simple curl command and supports MacOS, Linux, and WSL environments, with the tool integrating into any IDE including VSCode, JetBrains, Android Studio, and IntelliJ.
- The agent can perform complex multi-step workflows like “find one bug and fix it” through natural language commands, handling file operations, code modifications, and shell command execution autonomously.
My take: If I would have used Claude 4 Opus through an API, like with Cursor CLI, my monthly cost would have been more than $5,000 every month since May. Claude 4.1 Opus is the only model I have found I can rely on for agentic programming – it often manages to come up with good solutions as a starting point, but most times I still have to correct it. I have tried the cheaper models like Sonnet and GPT-4.1 but they get so many things wrong that the increase in productivity goes down quite a bit. And this is where Cursor’s dilemma lies – I do not know any single developer that would actively choose to use Cursor over Claude Code today. You pay more for worse models, and even if their environment is great, with Claude Code you don’t really miss the environment at all, you work differently.