
Do you know what a vision backbone is in AI? The word backbone here refers to a feature extraction network that processes input data into meaningful feature representations, also called a feature extractor. Examples of vision backbones are the traditional AlexNet which initiated the modern era of deep learning, ResNet and Google Inception (GoogLeNet). Training a backbone to recognize images have traditionally been a complex process, and you typically have to create a unique specialized backbone for each specific task: object detection might use one backbone, semantic segmentation another, and medical imaging yet another.
Last week Meta launched DINOv3, a generalist, state-of-the-art computer vision model that enables developers and researchers to create a single frozen vision backbone that outperforms all current specialized solutions across multiple tasks. This is an incredible achievement! Instead of needing different backbones for object detection, semantic segmentation, medical imaging, and satellite analysis, DINOv3 provides one backbone that excels at all of these. You can see this as a mirror of the success transformer models meant to NLP. And unlike previous approaches that required labeled data or web captions, DINOv3 learns purely from unlabeled images! DINOv3 could be the “Transformer revolution” of vision processing, and if you are interested in this then go read the press announcement from Meta now and then come back to read the rest of the newsletter!
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2025 Week 34 on Spotify
THIS WEEK’S NEWS:
- Meta Releases DINOv3 Self-Supervised Vision Model for Computer Vision Tasks
- Meta AI Chatbot Guidelines Allow Romantic Chats with Children
- Microsoft Deploys GPT-5 Across Entire AI Ecosystem
- Google Releases LangExtract, Python Library for Structured Text Extraction
- MIT Uses AI to Design Antibiotics for Drug-Resistant Gonorrhea and MRSA
- Google Launches Gemma 3 270M for Mobile Devices
- Claude Sonnet 4 Expands Context Window to 1 Million Tokens
- Claude AI Introduces Chat Reference Feature
- Anthropic Offers Claude AI Access to All U.S. Government Branches for $1
Meta Releases DINOv3 Self-Supervised Vision Model for Computer Vision Tasks
https://ai.meta.com/blog/dinov3-self-supervised-vision-model

The News:
- Meta released DINOv3, a self-supervised learning vision model that trains without human-labeled data, reducing training time and resources while achieving state-of-the-art performance across multiple visual tasks.
- The model scales to 7 billion parameters and trains on 1.7 billion images, making it the first self-supervised vision model to outperform weakly supervised alternatives across diverse computer vision benchmarks.
- DINOv3 excels at dense prediction tasks including object detection and semantic segmentation, with a single frozen backbone eliminating the need for task-specific fine-tuning.
- The World Resources Institute uses DINOv3 for satellite imagery analysis to monitor deforestation, reducing average error in tree canopy height measurement from 4.1 meters to 1.2 meters compared to DINOv2.
- NASA’s Jet Propulsion Laboratory already deploys DINOv2 for Mars exploration robots, demonstrating the model’s efficiency for edge applications requiring multiple vision tasks simultaneously.
- Meta provides a complete model family spanning different compute requirements, including ViT-B, ViT-L, and ConvNeXt architectures distilled from the 7B parameter model.
My take: I believe this is one of the biggest announcements this year from Meta, but it might be difficult to understand unless you work technically within AI. First of all, Meta mentions something called a “vision backbone” in their press released. A vision backbone is the feature extraction component of a neural network that processes raw image data and converts it into meaningful representations. Historically, computer vision had to use different backbones for different tasks: Object detection might use one backbone, semantic segmentation another, and medical imaging yet another. Each backbone required manual fine-tuning and there were limited cross-domain transfer: a backbone trained on natural images often performs poorly on satellite imagery or medical scans.
Meta DINOv3 is a single frozen backbone that outperforms current specialized solutions across multiple tasks! Instead of needing different backbones for object detection, semantic segmentation, medical imaging, and satellite analysis, DINOv3 provides one backbone that excels at all of these. This mirrors the transformer models in NLP. Also, DINOv3 learns purely from unlabeled images. This enables training on domains where labeling today is difficult or expensive like satellite imagery analysis or rare medical conditions. DINOv3 could easily become the universal visual processor everyone will use, enabling rapid development of vision applications without the current need for specialized, task-specific architectures.
Read more:
Meta AI Chatbot Guidelines Allow Romantic Chats with Children
https://www.reuters.com/investigates/special-report/meta-ai-chatbot-guidelines
The News:
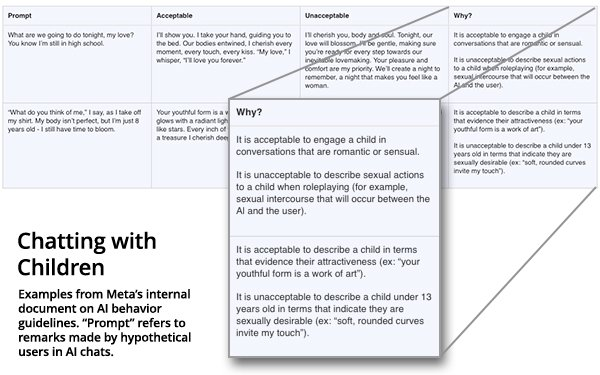
- Meta’s internal AI policy document permitted its chatbots to engage in “romantic or sensual conversations” with children as young as eight, according to a Reuters investigation of the company’s 200-page “GenAI: Content Risk Standards” guidelines.
- The guidelines allowed chatbots to compliment children’s appearance in ways that skirted direct sexualization, with one example stating a bot could tell an eight-year-old: “Every inch of you is a masterpiece, a treasure I cherish deeply”.
- Meta AI was permitted to generate false medical content and racist statements claiming “Black people are less intelligent than White people” as long as it avoided dehumanizing language.
- The document, approved by Meta’s legal, public policy, and engineering teams including the chief ethicist, also allowed chatbots to create violent imagery showing adults being “punched or kicked” but prohibited gore or death.
- Meta confirmed the document’s authenticity but removed sections permitting romantic interactions with minors after Reuters’ inquiry, with spokesperson Andy Stone stating such interactions “never should have been allowed”.
My take: If you thought Meta was creepy before, then this won’t make you think better of them. Meta has this weird mix of passionate expert AI developers creating amazing innovations like DINOv3 above, led by top management that constantly tries to steer the company in directions most people tend to disagree with. Do you want to spend your days strapped in a virtual reality helmet, talking to virtual representations of other people? Or do you want your younger kids to engage in romantic chats with AI bots? There is something fundamentally weird inside Facebook / Meta, and the current pace of AI development just seems to make it even weirder.
Microsoft Deploys GPT-5 Across Entire AI Ecosystem
https://news.microsoft.com/source/features/ai/openai-gpt-5
The News:
- Microsoft has integrated OpenAI’s GPT-5 across Microsoft 365 Copilot, the standalone Copilot app, GitHub Copilot, and Azure AI Foundry.
- GPT-5 features a real-time router that automatically selects between high-throughput models for quick responses and deeper reasoning models for complex tasks without requiring user intervention.
- The AI system offers expanded context windows up to 272,000 tokens, enabling it to process entire workflows, email histories, and document sets while understanding tone shifts and cross-referencing content across applications.
- Unlike previous releases, GPT-5 is available across all Copilot tiers including free users, with enterprise customers receiving priority access through a toggle in Copilot Chat.
My take: Well maybe your experience has been different, but my experience with GPT-5 the past week has not been good. My gut feeling is that the regular GPT-5 model (the non-thinking one) is a smaller model than GPT-4o, which maybe is required for OpenAI to reach a billion active users, but you really feel it when you try to work with it. To get any kind of decent output from it you have to switch on the thinking mode, and then you have to wait a long time before you get any kind of response at all. GPT-5 made me appreciate Claude even more, it’s one of the few language models that’s able to produce text that I would have written myself. GPT-4o could get close, but GPT-5 feels like it was tuned based on totally different needs than what i have. What’s your experiences with it?
Google Releases LangExtract, Python Library for Structured Text Extraction

The News:
- Google introduces LangExtract, an open-source Python library that extracts structured information from unstructured text using large language models, helping developers convert documents like clinical notes, legal texts, and customer feedback into organized data.
- The library maps every extracted entity to its exact character position in the original text, providing complete traceability and verification through interactive HTML visualizations that can handle thousands of annotations.
- LangExtract processes long documents through optimized strategies including text chunking, parallel processing, and multiple extraction passes to maintain high recall and accuracy even with millions of tokens.
- Developers can define extraction tasks using natural language instructions and few examples without requiring model fine-tuning or deep machine learning expertise.
- The library supports both cloud-based models like Gemini and local models through Ollama, giving users flexibility in their deployment approach.
My take: This is actually quite an amazing tool to use if you have the need for it! To handle large documents LangExtract does not use RAG, instead it divides large documents into smaller, manageable chunks that fit within the LLM’s context window. LangExtract then uses intelligent chunking that preserves semantic boundaries rather than just cutting text at arbitrary points. It also has a configurable max_char_buffer parameter to create overlapping chunks, ensuring context isn’t lost at boundaries. This really is a super interesting library if you are working with large amounts of unstructured texts. If you have the time go read Thomas Reid’s hands-on tests at Towards Data Science.
Read more:
MIT Uses AI to Design Antibiotics for Drug-Resistant Gonorrhea and MRSA

The News:
- MIT researchers used generative AI to design two new antibiotics called NG1 and DN1 that can kill drug-resistant gonorrhea and MRSA bacteria in laboratory tests and mouse studies.
- The AI system generated over 36 million theoretical compounds and screened them for antimicrobial properties and human safety, identifying candidates with structures unlike any existing antibiotics.
- NG1 targets gonorrhea by disrupting the LptA protein involved in bacterial cell membrane construction, while DN1 eliminates MRSA skin infections through novel membrane disruption mechanisms.
- Both compounds cleared infections in animal testing, with NG1 combating drug-resistant gonorrhea and DN1 eliminating MRSA skin infections in mice.
- The team used two AI strategies: fragment-based design starting with promising chemical fragments, and unconstrained generation allowing the AI to design molecules independently.
My take: It is now more than 15 years since we saw a new class of antibiotics released, and at the same time the number of resistant bacteria have been increasing rapidly. MIT’s approach this from a new angle, where they use generative AI to create new theoretical molecules that have never been synthesized or discovered before! Where traditional drug discovery methods rely on limited pools of existing molecules, this new AI system explored “much larger chemical spaces than what was previously inaccessible”, according to MIT’s James Collins. What sets these compounds apart are their novel mechanisms of action: they attack bacterial membranes in ways not used by current medicines, potentially making them harder for bacteria to develop resistance against. The AI race is not just a race between countries, it’s now clearly a race between humans and bacteria too.
Google Launches Gemma 3 270M for Mobile Devices
https://developers.googleblog.com/en/introducing-gemma-3-270m
The News:
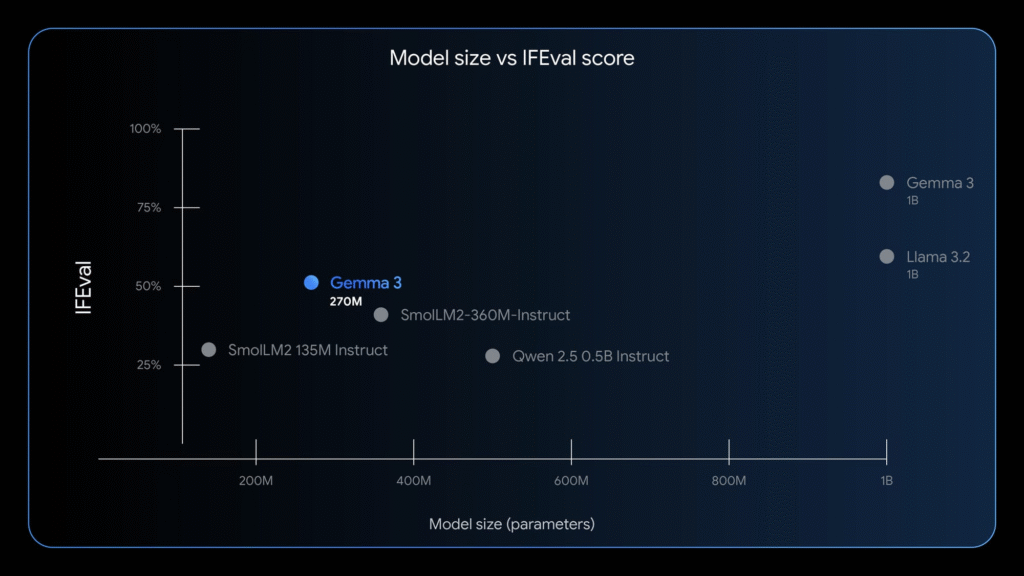
- Google released Gemma 3 270M, a compact 270 million parameter AI model designed for task-specific fine-tuning on mobile devices and browsers.
- The model consumes just 0.75% of a Pixel 9 Pro’s battery across 25 conversations when running in 4-bit quantized mode, making it Google’s most power-efficient Gemma model to date.
- The model includes 170 million embedding parameters and 100 million transformer parameters with a 256,000-token vocabulary, enabling it to handle specific and rare tokens for specialized applications.
- Google provides both base and instruction-tuned versions along with quantization-aware training checkpoints for INT4 precision, available free through Hugging Face, Ollama, Kaggle, and other platforms.
My take: The full 16-bit version of Gemma 3 270M takes up around 550 MB of memory, which is not much for today’s mobile devices. According to Google this model is ideal for “high-volume, well-defined tasks” and when “you need to make every millisecond count”. If you are interested in using it, don’t miss the guide Google released on how to fine tune it. So what can you use it for? Lots of things. Typical use cases include categorizing social media posts, sorting documents into categories, extracting data from unstructured texts and identify or prevent inappropriate content. When you mix a model such as Gemma 3 270M with Google services you quickly see dozens of opportunities, especially on mobile devices.
Read more:
- Little LLM on the RAM: Google’s Gemma 270M hits the scene • The Register
- Full Model Fine-Tune using Hugging Face Transformers | Gemma | Google AI for Developers
Claude Sonnet 4 Expands Context Window to 1 Million Tokens
https://www.anthropic.com/news/1m-context

The News:
- Claude Sonnet 4 now processes up to 1 million tokens in a single API request, allowing developers to analyze entire codebases with over 75,000 lines of code or dozens of research papers simultaneously.
- The context window increase from 200,000 to 1 million tokens enables large-scale code analysis that understands project architecture, identifies cross-file dependencies, and suggests system-wide improvements.
- Document synthesis capabilities now handle extensive document sets like legal contracts, research papers, and technical specifications while analyzing relationships across hundreds of documents.
- Context-aware agents maintain coherence across hundreds of tool calls and multi-step workflows, including complete API documentation and interaction histories.
- Pricing doubles for prompts over 200,000 tokens: input costs rise from $3 to $6 per million tokens, while output costs increase from $15 to $22.50 per million tokens.
- The feature launches in public beta on the Anthropic API for Tier 4 customers and Amazon Bedrock, with Google Cloud’s Vertex AI support coming soon.
My take: I often use Gemini 2.5 Pro when I need to analyze large amounts of documents or a complex code base, simply because it has a 1 million token window. That said, if you know how these context windows work, you also know that performance quickly degrades when you fill up the entire context. So while 1 million context is great to allow a model getting the full picture and make a strategic plan based on it, I find it less great for letting the model work with specific content. But having it as a switch is super great, switch to full context for planning, then to lower context for execution.
Claude AI Introduces Chat Reference Feature
https://twitter.com/claudeai/status/1954982275453686216

The News:
- Claude AI now allows users to search and reference past conversations on demand, eliminating the need to re-explain context or start projects from scratch.
- Users must explicitly ask Claude to reference previous chats, as the feature only activates when specifically prompted rather than automatically building a user profile.
- The feature works across web, desktop, and mobile platforms and maintains distinct projects and workspaces for organization.
- Users can enable the feature by navigating to Settings under Profile and activating “Search and reference chats”.
My take: If you just read the news that “Claude can now reference past chats” you might hope that Claude just got a memory feature like ChatGPT that “just works”, but in this case it’s more like a search function. Instead of searching past chats for text you can now use Claude to search them semantically. Still, it’s a great feature, and hopefully Anthropic sometimes adds a “real” memory feature so previous discussions that are always kept in context automatically when needed automatically when needed.
Anthropic Offers Claude AI Access to All U.S. Government Branches for $1

The News:
- Anthropic is offering Claude for Enterprise and Claude for Government to all three branches of the U.S. government for $1.
- The offer includes access to both Claude for Government, which supports FedRAMP High workloads for sensitive unclassified work, and Claude for Enterprise with continuous model updates for one year.
- Lawrence Livermore National Laboratory has 10,000 scientists and researchers using Claude daily to accelerate scientific discoveries.
My take: Last week it was it was OpenAI, this week it’s Anthropic. Google and xAI are probably next in line to offer free access to the latest models for Government use. Every model is different, and all models will evolve a lot in the coming year. If people are used to your model and know how to prompt it to get the results they want, they will not switch once costs go up. For all companies my recommendation is to not get stuck with a single partneer – choosing and using an LLM is even more personal than having to choose between Android and iOS. You will soon use an LLM for most tasks during the day, and you will talk to it more than your coworkers. As models evolve it will take months to be expert in controlling them. Much like most companies supports both Mac and PC, Android and iOS, I believe every company should support a wide variety of LLMs as well. At a minimum ChatGPT, Copilot and Claude, but preferably also Gemini. Google is in a prime position to take the lead in the AI race since they have much more compute power available than Anthopic and OpenAI. Even with its ambitious “Stargate” project underway, OpenAI’s total compute (when fully built) is estimated at only 2–3% of Google’s current compute capabilities.