You have probably seen the headline by now: 95% of all Generative AI pilots are failing according to a new MIT NANDA report. Within minutes thousands of LinkedIn AI experts rushed to declare that the AI bubble is bursting and that we all should be focusing on something else.
But those of us who took the time to actually read the 26-page report discovered something different. The problem isn’t that Generative AI is bad for business, it’s that companies are doing it wrong. The report reveals a fundamental “GenAI Divide” between organizations stuck with failed pilots and those achieving real value. The main difference is how people actually use AI versus how companies think they should.
Lesson 1: Stop Building Inferior Internal Chatbots
Companies proudly launch internal chatbots powered by cheap models, thinking they’re saving money by avoiding premium subscriptions. But it’s not working. One corporate lawyer told the researchers: “Our purchased AI tool provided rigid summaries with limited customization options. With ChatGPT, I can guide the conversation and iterate until I get exactly what I need” (p. 12). The report found that “ChatGPT beats enterprise tools because it’s better, faster, and more familiar” (p. 12). Your homegrown chatbot for “searching sales documents” isn’t competing with nothing, it’s competing with tools your employees already love and use daily.
Lesson 2: Let Employees Use the Tools They Know
“While only 40% of companies say they purchased an official LLM subscription, workers from over 90% of the companies we surveyed reported regular use of personal AI tools for work tasks” (p. 8). This “shadow AI economy” is thriving because employees are voting with their personal credit cards.
Just as companies let employees choose between iPhone and Android, or Mac and PC, why force everyone onto Microsoft Copilot when they’re fluent in Claude? A developer who codes with Claude Code on weekends will be far more productive with that same tool than being forced to use GitHub Copilot. The report emphasizes that “forward-thinking organizations are beginning to bridge this gap by learning from shadow usage and analyzing which personal tools deliver value” (p. 8).
Lesson 3: Build New AI-Powered Processes, Don’t Add Chatbots to Old Ones
The organizations successfully crossing the GenAI Divide aren’t just adding AI to existing workflows – they’re reimagining processes entirely. The report highlights that “Agentic AI, the class of systems that embeds persistent memory and iterative learning by design, directly addresses the learning gap that defines the GenAI Divide” (p. 14).
Instead of yet another chatbot no one wants, successful implementations involve agentic workflows where AI agents handle complete processes end-to-end, learn from feedback, and present results for decision-making. As the report notes, winning startups “build systems that learn from feedback (66% of executives want this), retain context (63% demand this), and customize deeply to specific workflows” (p. 14).
The 95% failure rate isn’t an indictment of AI, it’s an indictment of how most companies approach it. Those crossing the GenAI Divide “buy rather than build, empower line managers rather than central labs, and select tools that integrate deeply while adapting over time” (p. 23).
If you are interested in reading the full report, you can find it here: The GenAI Divide STATE OF AI IN BUSINESS 2025
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2025 Week 35 on Spotify
THIS WEEK’S NEWS:
- Anthropic Bundles Claude Code with Enterprise and Team Plans at Premium Pricing
- DeepSeek V3.1 Introduces Hybrid Thinking Modes for Faster AI Reasoning
- NASA and IBM Release Surya AI Model for Solar Flare Prediction
- Grammarly Launches Eight AI Agents for Academic and Professional Writing
- Alibaba Launches Qwen-Image-Edit for Advanced Image Editing with Text Capabilities
- Runway Launches Game Worlds Beta for AI-Generated Interactive Gaming
- OpenAI’s GPT-5 Surpasses Medical Professionals on Diagnostic Benchmarks
- NVIDIA Releases Nemotron Nano 2 Family of Hybrid AI Models
- Adobe Launches PDF Spaces for AI-Powered Document Collaboration
Anthropic Bundles Claude Code with Enterprise and Team Plans at Premium Pricing
https://www.anthropic.com/news/claude-code-on-team-and-enterprise

The News:
- Anthropic has integrated Claude Code into Enterprise and Team plans through premium seat upgrades that cost $150 per month per user.
- Premium seats provide access to both Claude chat interface and Claude Code terminal agent, allowing developers to research frameworks through conversations then implement production code using the same subscription.
- Early adopters like Altana reports 2-10x development speed improvements and Behavox are deploying Claude Code to hundreds of developers as their primary pair programming tool.
My take: I am using the Max 20x plan from Anthropic, which as of August 28 gives me 24-40 hours of Opus 4 every week. This plan costs $200 per month. Expensive, but worth it if you know how to use it. Now this new Premium seat definitely sounds interesting at “just” $150 per month, but before you go for purchase you might want to read up on the fine details. In this new premium subscription you only get 3-7 hours of Opus 4 usage per week! So yes, it’s easier for you to manage as a company, but 3 hours of Claude Opus 4 per week is nothing. Honestly I have no idea why Anthropic is launching this offer, and I just feel bad for the organizations signing up for this, hoping they will get something usable for their employees. If you want to use Claude Code today (and you should), you still need to sign up for the Max 20x personal plan and stick to Claude 4.1 Opus as your only model.
DeepSeek V3.1 Introduces Hybrid Thinking Modes for Faster AI Reasoning
https://api-docs.deepseek.com/news/news250821

The News:
- DeepSeek launched DeepSeek V3.1, a 671 billion parameter model that switches between thinking and non-thinking modes through different chat templates, allowing developers to deploy one model for both complex reasoning tasks and rapid responses.
- The model extends context length to 128K tokens and achieves significant performance benchmarks with 93.7% on MMLU-Redux, 84.8% on MMLU-Pro, and a 2091 Codeforces rating.
- V3.1-Think mode delivers comparable quality to DeepSeek-R1-0528 while responding faster, while non-thinking mode provides quicker answers for simpler queries.
- The model includes improved tool calling capabilities through post-training optimization, with better performance on agent tasks and multi-step reasoning.
- Available under MIT license on Hugging Face and ModelScope, plus through DeepSeek’s API with metered pricing starting September 5th, 2025.
My take: In benchmarks DeepSeek 3.1 even exceeds Claude Opus 4 in tests like Aider benchmark with a score of 71.6%. Aider is specifically good at measuring how well a model can handle different programming languages. User feedback has so far been overly positive, and being released with MIT license means anyone can use it freely for any purpose. DeepSeek themselves say that V3.1 is their “first step toward the agent era”. This is because DeepSeek V3.1, like Claude 4 Sonnet/Opus and GPT-5 has been post-trained optimized specifically for tool usage and agent tasks. The model also supports supports Strict Function Calling in Beta API, which is crucial for agents that need to interact with databases, web services and other software systems. It’s still too early to see if this is a contender for Claude 4 Opus, but I will be following this one closely.
Read more:
NASA and IBM Release Surya AI Model for Solar Flare Prediction
https://science.nasa.gov/science-research/artificial-intelligence-model-heliophysics/

The News:
- NASA and IBM released Surya, an open-source AI foundation model that predicts solar flares and space weather events to protect satellites, power grids, and communication systems.
- The model analyzes 14 years of data from NASA’s Solar Dynamics Observatory, processing over 250 terabytes of solar imagery captured every 12 seconds in multiple wavelengths.
- Early testing shows Surya can forecast solar flares up to two hours in advance, including their shape, position, and intensity, representing a 15-16% improvement over existing prediction methods.
- The AI generates visual predictions of solar flares and adapts quickly to new tasks without requiring extensive data labeling, unlike traditional AI systems.
- Surya is available on GitHub and HuggingFace for researchers worldwide to test and develop innovative space weather applications.
My take: Every week it feels like we get a new foundation model for various purposes. Last week we got DINOv3, the first foundation model for vision feature extraction, and this week we got Surya, the first ever foundation model specifically designed for solar physics. The model’s foundation architecture allows it to learn directly from raw solar data, distinguishing it from conventional AI systems that need more structured input. Getting a two hour advance warning could be a game changer for protecting expensive equipment from solar flares, and this is only the first version.
Grammarly Launches Eight AI Agents for Academic and Professional Writing
https://www.theverge.com/news/760508/grammarly-ai-agents-help-students-educators

The News:
- Grammarly released eight specialized AI agents integrated into its new “Docs” platform to tackle writing challenges.
- The AI Grader agent analyzes uploaded assignments against rubrics and course information to estimate grades before submission.
- Citation Finder automatically locates relevant sources and generates properly formatted citations to support claims in academic writing.
- Reader Reactions agent predicts how target audiences like professors or managers might interpret text, flagging potential misunderstandings and unanswered questions.
- Additional agents include an AI detector that scores whether text appears AI-generated or human-written, a plagiarism checker that scans against databases and published works, and a paraphraser that adjusts tone and style.
My take: Grammarly is one of those tools that becomes better the more you use it. These new tools look interesting, but you can already do much of this with ChatGPT and Claude. The main exceptions being the AI detector and citation finder, which scans a huge database with academic papers and published works, and compares content against 16 billion web pages. If you are a student or professional that work by delivering texts, and have not yet tried Grammarly, it’s definitely worth checking out.
Read more:
Alibaba Launches Qwen-Image-Edit for Advanced Image Editing with Text Capabilities
https://qwenlm.github.io/blog/qwen-image-edit

The News:
- Alibaba released Qwen-Image-Edit, a 20 billion parameter image editing model that extends Qwen-Image to enable precise text editing and visual modifications.
- The model offers dual editing modes: semantic editing for high-level changes like style transfer and object rotation, and appearance editing for precise local modifications without affecting other image regions.
- Features bilingual text editing in Chinese and English that preserves original font, size, color, and style when adding, deleting, or modifying text within images.
- Supports iterative editing workflows where users can refine images through multiple sequential steps, similar to having a conversation to reach desired outcomes.
- Available through Qwen Chat’s Image Editing feature, GitHub, and Hugging Face under Apache 2.0 license, with API access priced at $0.10 per image.
My take: In Tech Insights 2025 week 23 I wrote about Flux Kontext, which is also marketed as a tool to change specific properties of images. I have tried it but never really got it to work the way I wanted, which is also very similar to what most users express on various forums. User feedback for Qwen-Image-Edit has however so far been very positive, where Qwen is actually able to keep the modified image looking almost exactly like the original but with the changes requested. If you have the need to modify images digitally, definitely give this one a good try.
Runway Launches Game Worlds Beta for AI-Generated Interactive Gaming
https://runwayml.com/research/runway-game-worlds
The News:
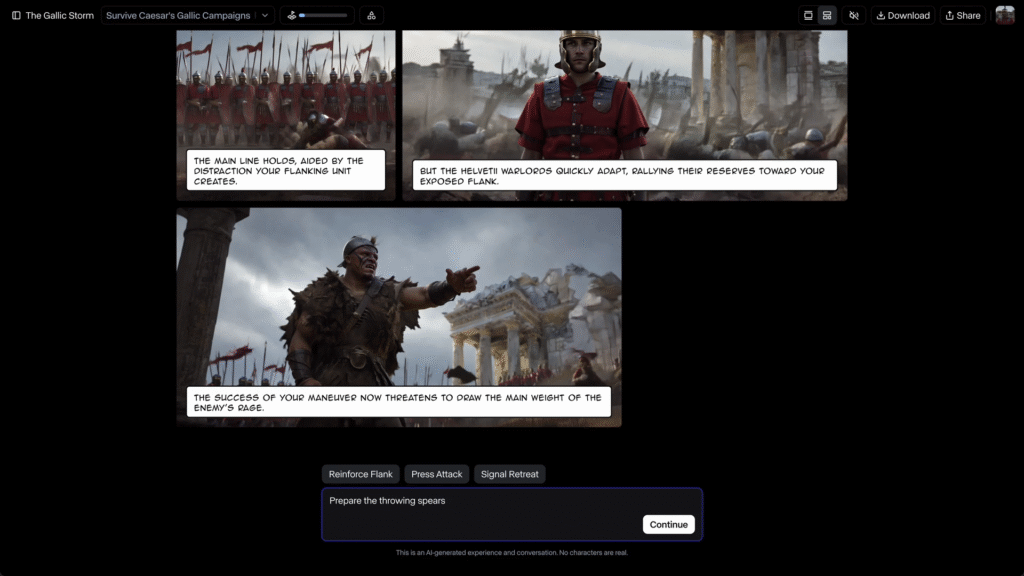
- Runway launched Game Worlds Beta, an AI platform that generates interactive games in real-time with personalized stories, characters, and visual content, offering creators and players a new type of gaming experience where each session is uniquely generated.
- Players can choose from three preset games including The Last Score (a heist game), Athena Springs (a mystery), and The Gallic Storm (an interactive history game), or create custom games from simple text prompts.
- The platform offers two visual modes: traditional Chat Mode for text-based gameplay and Comic Mode that generates accompanying images as the story unfolds.
- Custom games are private by default but can be made public for sharing, allowing users to explore any genre from standard gameplay mechanics to experimental narrative experiences.
- Runway positions this as a first step toward their vision of “General World Models” where game worlds, characters, and storylines are generated rather than pre-scripted or rendered.
My take: An interactive storybook that draws itself when you progress! This is not an interactive world like Google Genie 3 launched two weeks ago, instead it’s a cartoon-style interactive adventure where you chat and the story will unfold visually as it progresses. It looks really good, and this is definitely an area I believe we will see much more products being launched in the near future.
OpenAI’s GPT-5 Surpasses Medical Professionals on Diagnostic Benchmarks
https://arxiv.org/pdf/2508.08224

The News:
- OpenAI’s GPT-5 demonstrates medical diagnostic abilities that exceed both its predecessor GPT-4o and human medical professionals, marking a shift from human-comparable to above-human performance on standardized medical benchmarks.
- The model achieved 95.84% accuracy on MedQA clinical questions, a 4.8 percentage point improvement over GPT-4o’s 91.04% score.
- GPT-5 scored 70% on multimodal medical reasoning tasks that integrate patient histories with medical imaging, gaining nearly 30 points over GPT-4o.
- The system outperformed pre-licensed medical professionals by 24.23% in reasoning and 29.40% in understanding on expert-level tests.
- In a case study, GPT-5 correctly diagnosed Boerhaave syndrome, a rare esophageal perforation, from CT scans and lab values, and recommended a Gastrografin swallow study as the appropriate next step.
- The model showed fewer hallucinations and provided clearer, more interpretable explanations compared to GPT-4o, though it still struggled with some rare, image-heavy cases.
My take: Take a minute to consider this – an AI is now outperforming medical professionals doing their job faster and with more precision. It wont’ take long now until AI is also outperforming humans in domains like legal, programming, requirements analysis, and more. When AI is better than expert humans at a task, it’s no longer a question IF AI should be used, but how many humans are required to run it. When it comes to doctors however, I never believe the physical meeting will be replaced fully by machines. But when it comes to layers, programmers, and management consultants? Things are about to change.
Read more:
NVIDIA Releases Nemotron Nano 2 Family of Hybrid AI Models
https://research.nvidia.com/labs/adlr/NVIDIA-Nemotron-Nano-2
The News:
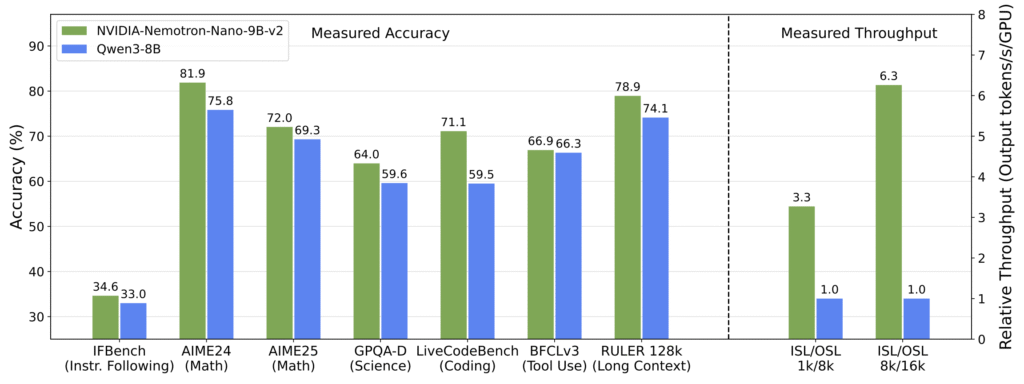
- NVIDIA released Nemotron Nano 2, a family of hybrid Mamba-Transformer reasoning models that deliver up to 6 times higher throughput than comparable models while maintaining similar accuracy levels.
- The flagship 9B parameter model uses a hybrid architecture combining Mamba-2 layers with attention layers to accelerate inference speed during long reasoning tasks.
- The model achieves 128,000 token context length on a single NVIDIA A10G GPU with 22GB memory, making long-context reasoning accessible on midrange hardware.
- Nemotron Nano 2 includes a configurable “thinking budget” feature that allows developers to control internal reasoning depth, potentially reducing inference costs by up to 60%.
- NVIDIA open-sourced most training datasets and methodologies alongside the model weights on Hugging Face with permissive licensing.
My take: If you are currently using Qwen3-8B for specific tasks then you might want to check this one out. Around the same performance on most benchmarks, but up to six times faster! While it seems like a perfect fit for 4090 and 5090 GPUs, NVIDIA only mentions the old A10 card from 2021 in their press release (which is using the Ampere-architecture, same as the RTX 30-series), and I wasn’t able to find any report from anyone running it on a consumer-grade GPU. So while it looks good in practice, you might want to wait for people to report if it actually runs on your hardware before trying to deploy it.
Adobe Launches PDF Spaces for AI-Powered Document Collaboration
The News:
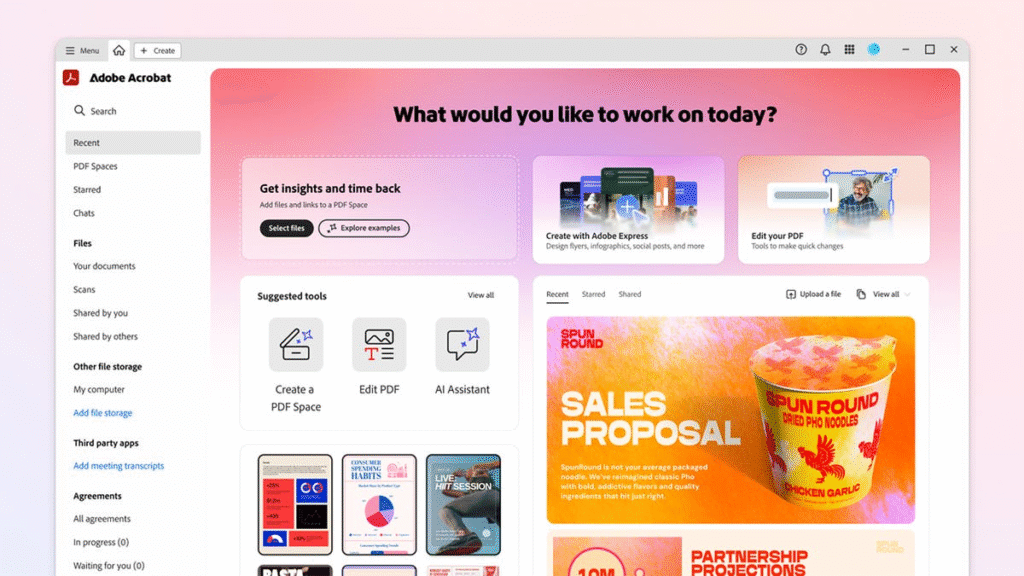
- Adobe introduced PDF Spaces, a new AI-powered workspace in Acrobat that consolidates up to 100 files and websites into interactive knowledge hubs where users can chat with AI assistants to extract insights and generate content.
- PDF Spaces supports PDFs, Microsoft 365 files, text files, and web links, using only uploaded content to generate responses without web searches. Users can create personalized AI assistants with specific roles like analyst or instructor, and the system provides citations linked directly to source material for verification.
- Teams can share entire PDF Spaces including custom AI assistants and notes, allowing colleagues to access the same knowledge base and AI-guided insights rather than just static files. The feature generates automatic summaries, answers questions, and surfaces key insights from uploaded documents.
- Adobe offers PDF Spaces free during a 14-day trial period from August 19 to September 1, 2025, after which it requires an Acrobat Studio subscription or AI Assistant add-on. The feature is available on desktop, web, and mobile platforms but currently supports English language only.
My take: This is Adobe’s take on Google NotebookLM, which has quickly established itself as the leading tool for AI document interaction. Both platforms offer similar functionality: uploading documents, chatting with them, and citation-backed responses, but with the main difference that NotebookLM is free and PDF Spaces require an Acrobat Studio subscription ($30 per month and user and includes Acrobat, PDF Spaces and Acrobat AI Assistant). So who is this service for? Honestly, I don’t really know. You do not get the features like the podcast or presentation generation features offered by NotebookLM. And you don’t get the performance of the latest and greatest models like Claude 4.1 Opus. Adobe don’t even mention which LLM is powering PDF spaces. And if you already have a Claude subscription, Anthropic offers their own Citations capabilities when discussing documents with Claude. Adobe PDF Spaces is probably a great tool for companies that focus 100% on Adobe and Microsoft products, and do not want to introduce new tools. For those companies PDF Spaces is probably OK, but it comes at a price.