
The biggest news last week was undoubtedly the launch of OpenAI Sora 2. You need an invite code to try it, but if you have it you’re in for a world of fun. If you haven’t already seen Sora 2 in action, do yourself a favor and spend 2 minutes watching The Quack short movie by OpenAI. This is how far we have come with AI generated video today, and while it’s still not perfect it’s definitely good enough for hobby productions.
Last week Anthropic further tightened the usage limits of Claude Opus 4.1, their top model. So now, even with the top tier $200 per month Max20 subscription, most users will max out their weekly limit in just a few hours. If you still want to continue using Claude Opus 4.1 after that point Anthropic has now opened up so you can purchase extra usage if you’re subscribed to the Max 20x plan. The benefits of using AI for software development are enormous, and having to shift between providers will probably be the norm for a few years when technology improves at the pace it’s doing now. You can choose to not go AI first, but you will miss out in quality and productivity. For now, OpenAI Codex with a Pro subscription is what I recommend everyone to use, but I wouldn’t be surprised if that recommendation changed next month already.
So how do you navigate in this wild archipelago of AI tools and services? First of all, partner up with a company that (1) knows everything that happens in AI and the effects recent changes might have on your business, (2) knows how to build real AI solutions for production use, not just talks about it, and (3) have a history of working on a strategic level with EMTs and know how to present information in a way so your company can use it. Right now in my company TokenTek we spend almost equal time doing strategic work as we do building things, which just shows the massive demand for these kinds of services. Secondly, you need to start building something so you can build these skills internally. Build an agentic system in your service department, a multi-agent system for requirements analysis, or design a process to autonomously go from test specifications to test code to test results. But just do something, because the longer you wait the harder it will be to catch up, this train is accelerating quite fast.
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2025 Week 41 on Spotify
THIS WEEK’S NEWS:
- OpenAI Sora 2 Launches with Synchronized Audio and Social Video App
- Microsoft Launches Open Source Agent Framework for Azure AI Foundry
- Anthropic Launches Claude Sonnet 4.5 and Reduces Opus 4.1 Usage for Max Subscribers
- Google DeepMind Develops AI Agent That Learns Through Mental Simulation
- Microsoft Introduces Agent Mode in Excel and Word with Office Agent
- Lovable Launches Integrated Cloud and AI Platform
- Google Introduces Command-Line Tools for Jules Coding Agent
- IBM Releases Granite 4.0 Models with Hybrid Mamba-Transformer Architecture
- Thinking Machines Launches Tinker API for Language Model Fine-Tuning
- DeepSeek Releases V3.2-Exp with Sparse Attention
OpenAI Sora 2 Launches with Synchronized Audio and Social Video App
https://openai.com/index/sora-2

The News:
- OpenAI released Sora 2, a video and audio generation model that creates videos up to 20 seconds with synchronized dialogue, sound effects, and ambient soundscapes.
- The model demonstrates improved physical accuracy, including realistic object physics such as a basketball rebounding off a backboard after a missed shot instead of teleporting to the hoop.
- A new iOS app named Sora accompanies the release, featuring a social feed where users create, remix, and share AI-generated videos with an algorithmic ranking system that users can customize through natural language instructions.
- The “cameos” feature allows users to insert themselves or others into AI-generated scenes after recording a one-time video and audio clip for identity verification and likeness capture.
- The model follows complex multi-shot instructions while maintaining consistent world state across sequential scenes, with the ability to generate Olympic gymnastics routines, backflips on paddleboards, and triple axels.
- Sora 2 is available free in the U.S. and Canada with usage limits, while ChatGPT Pro subscribers gain access to the higher-quality Sora 2 Pro model on sora.com, with an API release planned.
- OpenAI compares Sora 2 to GPT-3.5, describing it as a major leap from the original Sora model released in February 2024, which the company likens to the GPT-1 moment for video.
My take: I think OpenAI is spot on when they say that Sora 2 is their “GPT‑3.5 moment for video”. It’s not perfect, and you still see clearly that the videos are AI-generated. Maybe you need to look twice on some videos, but for most it’s pretty obvious. But what makes this great is that it’s so fun to use. You can use it on the go in the mobile app, you can embed yourself in the video, and videos come with full sound effects. I think we will see an explosion of AI-generated small movies in the next few months. Some will hate it, but most people will just have fun with it.
Read more:
Microsoft Launches Open Source Agent Framework for Azure AI Foundry
https://azure.microsoft.com/en-us/blog/introducing-microsoft-agent-framework/

The News:
- Microsoft Agent Framework is an open source SDK and runtime that simplifies orchestration of multi-agent systems by converging AutoGen and Semantic Kernel into one framework.
- The framework addresses inefficiencies where “50% of developers lose more than 10 hours per week” due to fragmented tooling and context-switching across platforms.
- Developers can integrate any API via OpenAPI, enable agent-to-agent collaboration with A2A protocol, and connect to tools dynamically using Model Context Protocol.
- The framework includes built-in observability through OpenTelemetry instrumentation, durability for long-running workflows with pause/resume capabilities, and human-in-the-loop approval mechanisms.
- Multi-agent orchestration patterns include sequential, concurrent, group chat, handoff, and Magentic One coordination where a manager agent builds dynamic task ledgers.
- Python and .NET support is available, with pluggable memory modules supporting Redis, Pinecone, Qdrant, Weaviate, Elasticsearch, and Postgres.
- Enterprise connectors integrate Azure AI Foundry, Microsoft Graph, Microsoft Fabric, SharePoint, Oracle, Amazon Bedrock, MongoDB, and Azure Logic Apps.
- KPMG uses the framework for Clara AI audit automation, BMW analyzes vehicle telemetry, and Commerzbank pilots avatar-driven customer support with MCP integration.
My take: This is a big one if you work in AI. Microsoft Semantic Kernel is a lightweight middleware for AI models that is built for enterprise use, focusing on integrating AI into existing C#, Python, and Java applications through a plugin architecture using OpenAPI specifications. AutoGen is a multi-agent orchestration framework built on an actor model runtime, specializing in creating AI agents that collaborate, form teams, and execute distributed workflows. Today both AutoGen and Semantic Kernel has entered maintenance mode, receiving only bug fixes and security updates without new features. All code has been merged into one code base: The Agent Framework, which combines Semantic Kernel’s enterprise features with AutoGen’s multi-agent orchestration into one SDK and runtime. This is big, and it’s Microsoft’s single path forward.
Anthropic Launches Claude Sonnet 4.5 and Reduces Opus 4.1 Usage for Max Subscribers
https://www.anthropic.com/news/claude-sonnet-4-5
The News:
- Anthropic released Claude Sonnet 4.5 as its most capable coding model, maintaining the same API pricing as Claude Sonnet 4.0 at $3 per million input tokens and $15 per million output tokens.
- According to Anthropic the model can operate autonomously “for more than 30 hours on complex, multi-step tasks”, a substantial increase from the seven hours achieved by Claude Opus 4 during internal testing.
- Claude Sonnet 4.5 scores approximately 60% on operating system proficiency benchmarks, compared to around 40% for earlier models, and demonstrates improvements in financial analysis, scientific reasoning, and cybersecurity tasks.
- The release includes new developer tools: a terminal interface with checkpoint functionality, code execution and file creation within conversations, a Chrome browser extension in beta, and a Claude Agent SDK with access to virtual machines and memory management components.
- Anthropic also reduced weekly usage limits across all paid subscription tiers starting September 30, 2025, with Max 20x ($200/month) subscribers reporting Opus 4.1 usage limits decreased by approximately 75%.
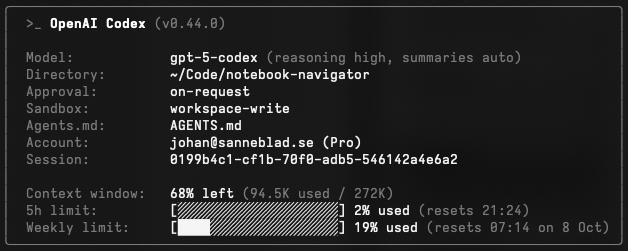
My take: When I created my plugin Notebook Navigator with Claude Code between April and July, I could work non-stop with Claude 4 Opus nearly 24/7 without hitting the limit and I used billions of tokens. Only when I ran heavy debug sessions when I sent in thousands of logs lines for debugging did I get close to the limit, but other than that it was just an amazing experience. Then in August I can only guess that Anthropic started quantizing their models, which basically translates to they became stupid. They also modified their tool Claude Code, and in the latest version it doesn’t even reveal it’s thinking process. Every week that passed made it even more stupid, mainly because they did everything in their power to reduce the amount of data sent to Anthropic servers to reduce cost.
This week I worked with Claude 4.1 Opus for 30 minutes and already 30% of my weekly limit was spent. And I have the $200 Max20 subscription. It’s clear that Anthropic does not want you to use their Opus model anymore, they are basically phasing it out by switching to a dumbed down Claude Code experience and minuscule usage limits.
What’s left from Anthropic is Claude Sonnet 4.5. It’s ok, but it’s not the magical experience of having a completely “unlocked” version of Claude Opus just blasting through tokens without limit. But that experience is still available with OpenAI Codex. I have used their most expensive model GPT5-CODEX-HIGH a lot the past week, and I have still not yet passed 20% of my weekly usage. This is the nearly same experience that I had with Claude 4 Opus before Anthropic dumbed it down, and I am so happy that this option is still available.
If you still pay for a Max20 account at Anthropic I highly recommend that you at least try OpenAI Codex. It’s an amazing experience when you use it with the best model.
Read more:
- Update on Usage Limits : r/ClaudeAI
- Usage Limits Discussion Megathread – beginning Sep 30, 2025 : r/ClaudeAI
Google DeepMind Develops AI Agent That Learns Through Mental Simulation
https://danijar.com/project/dreamer4
The News:
- Dreamer 4 is an AI agent that learns to complete tasks by training inside its own simulated world model, collecting diamonds in Minecraft using only offline data without interacting with the actual game.
- The system processes over 20,000 sequential mouse and keyboard actions from visual input, training through three stages: learning game mechanics from videos, developing decision-making capabilities, and refining skills through simulated practice.
- The world model runs at 21 frames per second on a single GPU with a 9.6-second context window, using a shortcut forcing objective that requires only 4 sampling steps compared to 64 in traditional diffusion models.
- In controlled tests, human players completed 14 of 16 complex tasks inside Dreamer 4’s simulation, such as placing blocks in specific patterns and interacting with crafting systems, compared to 5 tasks in rival model Oasis and 0 tasks in Lucid-v1.
- Dreamer 4 achieved a 0.7% success rate in obtaining diamonds, with 99% success for basic items like wooden pickaxes and 29% for iron pickaxes, completing intermediate milestones 17-24 minutes faster than behavioral cloning methods.
My take: Maybe you also read this news last week and didn’t understand at all what it was about. “Learns through a mental simulation”? The approach used by Dreamer 4 demonstrates how world models are maturing to handle much more complex tasks with improved accuracy. The Dreamer series is not new, DayDreamer has been training real robots in 2022. The new thing here is the scale and accuracy. Dreamer 4 handles complex, long-horizon tasks like collecting diamonds in Minecraft (requiring 20,000+ sequential actions).
Dreamer 4 works by watching videos of Minecraft gameplay and learns the rules – click on a tree and wood appears, if you walk forward the landscape changes, if you craft items in a certain order, you get tools, and so on. Based on what it sees it builds a neural network that can predict what will happen next in Minecraft given any action. Once this internal “Minecraft simulator” is built by the model, it can practice inside it. It tries different sequences of actions (moving, mining, crafting) and sees what happens in its predicted version of the game. The AI ran through 20,000+ actions entirely in this imagined world, never touching the real game.
What makes this approach so interesting is when training models for real-works scenarios. Just like a human who knows how cars, pedestrians and bikes moves can design training simulators for it, this allows an AI to build its own training simulator for various real-life situations and then learn from it. This approach is already being used in robotics research, where earlier Dreamer versions train physical robots (quadrupeds, robotic arms) in hours instead of days, avoiding the cost and safety risks of extensive real-world testing.
Read more:
Microsoft Introduces Agent Mode in Excel and Word with Office Agent
The News:
- Microsoft released Agent Mode in Excel and Word alongside Office Agent in Copilot chat.
- Agent Mode in Excel analyzes data sets, generates formulas, creates new sheets, and builds data visualizations in a single prompt. The system evaluates its own outputs, fixes errors, and iterates until results are verified.
- Example capabilities include creating financial monthly close reports with year-over-year growth analysis, loan calculators with payment schedules, and household budget trackers with conditional formatting and charts.
- Agent Mode in Word handles document drafting through conversational interaction, asking clarifying questions and applying native Word styles. Users can prompt tasks like “update this monthly report with latest numbers from the /Sept Data Pull email” and Copilot retrieves referenced data and updates tables.
- Office Agent in Copilot chat clarifies user intent, conducts web research with visible chain of thought reasoning, and generates PowerPoint presentations or Word documents. The system runs quality checks during code generation and produces editable output files.
My take: So when you read this, did you also wonder why they released two things at the same time – Agent mode in Excel and Word and the new Office agent in Copilot chat? The reason is that Microsoft is going two different routes here. The agent mode in Excel and Word is using OpenAI’s latest reasoning model GPT5, where the Office Agent in Copilot chat use Claude Sonnet. This also makes it even more complex if your company have not yet approved API access to Anthropic’s servers, since Claude through M365 Copilot uses Anthropic’s licensing terms.
I recommend all companies I work with to start their AI journey by investigating API access approval to Anthropic, OpenAI and if possible Mistral. Data is not stored permanently on their servers, and no data is used to train further models. Allowing these three also do not limit your company in the future. For example like in this case – maybe your employees would like to use the new Office agent, but since it uses Claude and Anthropic’s license agreement you can’t enable it. Having all three enabled (Anthropic, OpenAI, Mistral) also opens up for a world of possibilities when it comes to multi-agent AI systems.
Lovable Launches Integrated Cloud and AI Platform
The News:
- Last week Lovable introduced Lovable Cloud and AI, combining backend infrastructure and AI capabilities into a single prompt-based platform. Users can build full-stack applications without managing databases, authentication, file storage, or API keys.
- Lovable Cloud provides built-in user authentication, row-level security, file storage, and database management. The system scales automatically during traffic spikes and includes a free tier covering up to $25 per month of usage.
- Lovable AI integrates Google Gemini models and OpenAI without requiring separate API keys or billing configuration. The platform launched with free access from September 29 to October 6, 2025.
- The company provides usage-based billing consolidated within Lovable, eliminating separate tracking across multiple AI providers. Users can request specific models during development.
- Examples include social platforms with user profiles, inventory systems with stock tracking, learning apps with progress monitoring, and collaboration tools. The company raised $200 million in Series A funding at a $1.8 billion valuation in July 2025.
My take: After having spent hundreds of hours with the best AI models there is, including Claude 4.1 Opus and GPT-5-CODEX-HIGH, I can safely say that I would never ever in my life trust a system that was build by an AI that was controlled by someone with zero skills in software architecture and programming. With the absolute best model today GPT5-CODEX-HIGH (which Lovable doesn’t even use) you can get pretty far, but it too makes mistakes and those mistakes have a tendency to grow like cracks in a dam. Without rigorous code reviews, testing frameworks, and a deep understanding of architectural principles, the end result will always be a ticking time bomb.
Google Introduces Command-Line Tools for Jules Coding Agent
https://blog.google/technology/google-labs/jules-tools-jules-api
The News:
- Google launched Jules Tools, a command-line interface that brings its autonomous coding agent directly into developer terminals, eliminating the need to switch between browser windows and GitHub.
- Jules executes tasks in remote virtual machines and returns pull requests, with the CLI installable via npm using npm install -g @google/jules.
- Google also previewed the Jules API, which integrates the agent into CI/CD pipelines, Slack, and custom workflows through programmatic triggers.
- Jules includes memory that stores developer preferences and applies them to future tasks, environment variable management for credentials, and file selectors to focus context on specific files.
- The agent uses Gemini 2.5 Pro and operates asynchronously, processing tasks on Google’s servers while developers continue other work.
My take: Well it has been very quiet around Google Jules the past year, and there’s a good reason for it. Gemini 2.5 Pro is not so good at agentic workflows, so it doesn’t really matter how good the front-end is if the model can’t do something useful. That said, I have very high hopes for Google Gemini 3 Pro, which should be due out next month if we are lucky.
IBM Releases Granite 4.0 Models with Hybrid Mamba-Transformer Architecture
https://www.ibm.com/new/announcements/ibm-granite-4-0-hyper-efficient-high-performance-hybrid-models
The News:
- IBM released Granite 4.0, an open-source language model family that uses a hybrid Mamba-2/transformer architecture to reduce memory requirements by up to 70 percent
- The family includes four variants. Granite-4.0-H-Small has 32 billion total parameters with 9 billion active, Granite-4.0-H-Tiny has 7 billion total parameters with 1 billion active, Granite-4.0-H-Micro contains 3 billion dense parameters, and Granite-4.0-Micro uses 3 billion parameters with conventional transformer architecture.
- H-Small and H-Tiny incorporate fine-grained mixture of experts (MoE) blocks with shared experts that remain always active. The smallest Granite 4.0 models outperform Granite 3.3 8B despite using less than half the parameters.
- The models deploy on watsonx.ai, Hugging Face, NVIDIA NIM, Ollama, Docker Hub, LM Studio, Replicate, Dell Pro AI Studio, and Kaggle. Azure AI Foundry and Amazon SageMaker support arrives soon. All models carry Apache 2.0 licensing. IBM plans reasoning variants and a Medium-sized model by end of 2025.
My take: I first wrote about the hybrid-mamba-transformer architecture in Tech Insights 2025 Week 14, when Hunyuan-T1 was launched. A while later NVIDIA released their Nemotron Nano 2 that used the same Mamba-2 layers used in Granite 4.0. Mamba-2 is an architecture that uses less memory and runs faster than transformers, especially with longer text. Where transformers must store every previous word in memory (which means memory usage grows constantly throughout a conversation), Mamba-2 keeps memory usage fixed no matter how long the conversation gets. This means a chat with 1,000 words uses the same memory as one with 10,000 words. It’s both faster and more efficient than transformers. Performance of the new Granite 4.0 models are above average for mid-tier models, but strong with RAG tasks. So if you need a mid-tier model but with maximum performance, Granite 4.0 might be just the models for you.
Thinking Machines Launches Tinker API for Language Model Fine-Tuning
https://thinkingmachines.ai/blog/announcing-tinker
The News:
- Thinking Machines released Tinker, a managed API service that handles fine-tuning of language models while developers control algorithms and data. The platform removes the need to manage distributed training infrastructure, scheduling, or GPU allocation.
- The service supports models ranging from small to large open-weight architectures, including mixture-of-experts models like Qwen-235B-A22B with 235 billion total parameters and 22 billion activated per inference. Switching between model sizes requires changing one line of Python code.
- Tinker provides low-level API primitives such as forward_backward and sample functions, giving researchers granular control over loss functions, training loops, and data workflows in standard Python. The platform uses LoRA-based tuning to share compute resources across multiple training jobs.
- Research teams from Princeton trained mathematical theorem provers, Stanford’s Rotskoff Chemistry group fine-tuned models for chemistry reasoning tasks, Berkeley’s SkyRL group ran multi-agent reinforcement learning experiments, and Redwood Research applied the platform to AI control tasks.
- The platform operates in private beta with free initial access. Usage-based pricing will be introduced in the following weeks. Thinking Machines raised $2 billion in funding earlier this year from investors including a16z, NVIDIA, AMD, Accel, ServiceNow, Cisco, and Jane Street.
My take: If you read the news about Mira Muratis new product Tinker and didn’t understand at all what it is they launched, I can summarize it for you. For some specific use cases AI developers sometimes need to create custom models trained on specific tasks or data sets. Most companies already use services like Azure AI or HuggingFace for that, but for some needs (especially in MedTech) you need more control than they offer. For example medical diagnostics models may penalize false negatives more heavily than false positives, since missing a positive diagnosis carries greater consequences. So researchers need custom loss functions when standard options like cross-entropy or mean squared error do not match their optimization goals.
This is where Tinker makes sense. Tinker offers low-level API primitives (forward_backward, sample functions) in Python rather than GUI-based configurations. This means you can control things like custom loss functions, training loops, and reinforcement learning workflows while Tinker handles distributed training infrastructure. For many companies Tinker might even mean they do not have to invest in their own AI infrastructure for custom model training.
DeepSeek Releases V3.2-Exp with Sparse Attention
https://api-docs.deepseek.com/news/news250929
The News:
- DeepSeek released V3.2-Exp on September 29, 2025, an experimental model built on V3.1-Terminus that introduces DeepSeek Sparse Attention. The system addresses inference cost bottlenecks in long-context operations, offering potential savings of up to 50 percent on API calls.
- The sparse attention mechanism uses a “lightning indexer” to identify relevant context excerpts, followed by fine-grained token selection that loads only chosen tokens into the attention window. This reduces attention complexity from O(L²) to O(Lk), where k is substantially smaller than L.
- The model maintains 671B parameters and performs on par with V3.1-Terminus across public benchmarks. On MMLU-Pro both models scored 85.0, while V3.2-Exp achieved 89.3 on AIME 2025 compared to V3.1’s 88.4.
- The model is available as open-weight under MIT license on Hugging Face with technical documentation on GitHub. API pricing dropped to $0.28 per million input tokens and $0.42 per million output tokens, representing over 50 percent reduction from previous rates.
- SGLang and vLLM provided day-zero support with optimized sparse attention backends, implementing FlashMLA kernels and dynamic cache management with page size 64 for the indexer and page size 1 for token-level sparse operations.
My take: It all sounded pretty good until I read that DeepSeek V3.2-Exp tries to “identify relevant context excerpts” and only loads “chosen tokens into the attention window”. I’m quite sure OpenAI has similar systems in place for GPT5, and I think these indexers are one of the key differences why GPT5 and Copilot gives so vastly different results on same content. The key here is that DeepSeek is not OpenAI, so how good DeepSeek V3.2-Exp will work on actual documents for actual work tasks remains to be seen. The benchmarks tell very little in this case.