
Be prepared to forget everything you have learnt about how to maximize AI productivity by maximizing token usage. In the new token economy less is more, and the new top skill for AI engineers in 2026 will be how to optimize token usage to save cost. When OpenAI launched GPT-5.5 last Thursday they doubled the prices, from $2.50 input / $15.00 output per 1M tokens to $5.00 input / $30.00 output. This matches the pricing for Anthropic Opus 4.7, which is $5.00 input / $25.00 output per 1M tokens.
Many companies I talk to are not aware of what token pricing means. Many do not even know what a token is (here’s a good explanation). Maybe your company rolled out GitHub Copilot Business for $19 or Enterprise for $39 to all developers and called it a day. If so, your world is about to change drastically in the next few months.
“It’s now common for a handful of requests to incur costs that exceed the plan price!” Joe Binder, VP of Product, GitHub
First off. Due to the increase in API prices and the adoption of agentic workflows, GitHub can no longer continue with their current pricing for GitHub Copilot at $19 / $39. They were losing money from it, so they have taken several steps the past two weeks to try to mitigate the increasing costs:
- Using Claude Opus in GitHub Copilot now consumes 7.5x of your “included” monthly requests to compensate for the pricing increase.
- Using GPT-5.5 in GitHub Copilot also consumes 7.5x more of your “included” monthly requests. This means that the 300 “included” premium requests are now just 40 requests. Per month.
- Because Copilot still includes access to older models at 1x rates, they also needed to reduce usage of these older models. So Microsoft added heavy rate limits that prevents users from sending too many questions to Copilot in one session. In practice it means you can use AI agents in GitHub Copilot for a limited time and then have to go back and write code by hand.
Now the interesting part here is that these limits didn’t solve it. So last week Microsoft announced that they have stopped all new signups for Copilot Pro, Copilot Pro+, and student plans. Why? Because the plans are likely going away.
In an internal document revealed last week, Microsoft plans to discontinue all Copilot plans starting in June. All companies will then have to pay full API costs for every single developer. What does that mean in practice? It means that if you have unskilled AI developers they can easily fill the entire memory (context window) of GPT-5.5 with 1 million tokens and ask it refactor a section of the code base. One simple request, but it will cost your company $30. For one prompt. The same you previously paid for the entire month.
My prediction for the next 6 months is that token optimization will be one of the most highly sought after skills for AI developers. Spending lots of tokens to be productive is easy, as long as you are not paying the bill yourself. As an example Uber is reported to have burnt through it’s entire 2026 AI budget in just four months.
If you run a company with developers using GitHub Copilot, ask your managers about their strategy for token optimization. Do they know how to prompt in a way to minimize context window usage but maximize the output quality? If they don’t, start investigating how you can achieve this. Also make sure you have setup projects (if you use OpenAI) and cost centers (if you use Copilot) properly so a single developer can not waste your entire company AI budget by themselves. While you cannot limit API use explicitly for each developer, there are ways around it for most services.
Finally. I often get the question “how much will it cost per month” once companies go pay-per-token. The answer is that it depends. Used the right way with skills, predefined prompts and a clear process, the cost will be reasonable and justifiable, especially considering the quality and productivity increase received from it. The same goes for properly configured agentic systems, those costs can be even more controlled. But the skill requirements have suddenly changed from being productive with AI to being cost effective with AI. Make sure your developers are aware.
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2026 Week 18 on Spotify
THIS WEEK’S NEWS:
- GitHub Pauses New Sign-ups for Copilot Pro, Pro+, and Student Plans
- Google Reaches 75% AI-Generated Code
- Google Releases Eighth-Generation TPUs: Two Specialized Chips for Training and Inference
- OpenAI GPT-5.5: New Model for Agentic and Knowledge Work
- OpenAI Adds Workspace Agents to ChatGPT
- OpenAI Releases ChatGPT Images 2.0 Powered by gpt-image-2
- DeepSeek Releases V4 Preview Models with 1M-Token Context and New Architecture
- Moonshot AI Releases Kimi K2.6 as Open-Weight Coding and Agent Model
- Claude Code Fixes Three Quality Bugs
- Anthropic Tests Removing Claude Code from Pro Plan
- Lovable’s 48-Day Exposure
- Meta Cuts 8,000 Jobs as AI Spending Reshapes Workforce
GitHub Pauses New Sign-ups for Copilot Pro, Pro+, and Student Plans
https://github.blog/news-insights/company-news/changes-to-github-copilot-individual-plans/

The News:
- GitHub restructured its individual Copilot plans on April 20, pausing new sign-ups for Pro, Pro+, and Student plans while tightening usage limits and adjusting model availability across tiers.
- New sign-ups for Copilot Pro, Pro+, and Student plans are suspended immediately; Copilot Free remains open to new users.
- Usage limits have been tightened across individual plans. Pro+ now offers more than 5x the quota of Pro, and existing Pro users who need higher limits must upgrade to Pro+.
- Opus models are no longer available in Pro plans. Claude Opus 4.7 is now restricted to the Pro+ plan ($39/month), and previous Opus models are being phased out across all individual plans, including Pro+.
- GitHub cites agentic workflows as the driver: long-running, parallelized agent sessions now regularly consume more compute than the original plan structure was designed to support.
- Existing subscribers retain their current plans. A refund window is open until May 20 for users who want to cancel.
- Usage limits are now displayed directly in VS Code and Copilot CLI so users can monitor consumption before hitting caps.
“Agentic workflows have fundamentally changed Copilot’s compute demands. Long-running, parallelized sessions now regularly consume far more resources than the original plan structure was built to support.”
My take: If you are subscribed to an individual GitHub Copilot plan, my advice is to cancel it right now. GitHub Copilot can no longer be used efficiently for agentic software development. Go with either the Anthropic Max 5x for $100 / month, or the OpenAI Pro 5x for $100 / month, this is the “new starting price point” for agentic software development. If you spend more than 2-3 hours per day with these tools you most probably need to jump to the $200 Anthropic Max 20x / $200 OpenAI Pro 20x subscriptions for full-day productivity. If you have never worked with Claude Code or Codex before you are in for a treat.
For companies, there are two clear ways forward. 1. If you mostly use Anthropic models I would recommend signing up for Premium seats at $125 per month and 6.25x usage compared to standard seats. This gives all developers a good chunk of free usage and after they hit the ceiling it will switch over to usage-based API pricing. 2. If you mostly use GPT-models go with OpenAI, and if you require EU data processing or DORA compliance, OpenAI will have you covered with their enterprise license.Or why not go with both, since you only pay for what you use.
At this point I do not consider staying with GitHub Copilot a viable option for anyone, especially after the leaked internal memo indicating that Microsoft will move towards 100% API-based pricing in June. The agentic harness built into GitHub Copilot performs worse than the optimized combination of Claude Code + Opus 4.7 or Codex + GPT-5.5. And now when pricing is the same there is simply no reason left to stay.
“It’s now common for a handful of requests to incur costs that exceed the plan price!” Joe Binder, VP of Product, GitHub.
Of course you can ignore all this and force your developers to continue to use GitHub Copilot just as it is. Just be aware that their AI productivity might go down the drain, held back by rate limits, poor agentic scaffolding and limited monthly usage.
Read more:
Google Reaches 75% AI-Generated Code

The News:
- At Google Cloud Next 2026, CEO Sundar Pichai announced that 75% of all new code written at Google is now AI-generated and reviewed by human engineers, up from 50% last fall and approximately 25% in late 2024.
- The 75% figure describes code that AI tools draft first, with engineers reviewing and approving before any commit ships to production — it does not mean autonomous code runs without human sign-off.
- Pichai cited a recent internal code migration completed six times faster than previously possible, crediting AI agents for the acceleration.
- Meta is tracking a similar trajectory: for the first half of 2026, the company set a target that 65% of engineers in its creation org should write more than 75% of committed code using AI.
- Google’s internal AI tooling includes test generators, code-review assistants, and AI assistants embedded across the engineering organization, rather than a single tool.
“Recently, a particularly complex code migration done by agents and engineers working together was completed six times faster than was possible a year ago with engineers alone.” blog.google.com
My take: It’s one thing to hear me talk about what we do at TokenTek, a small Göteborg-based AI consultancy company. In short we help Swedish companies integrate AI and agentic systems to achieve 10x productivity increase, increased source code quality, better tests, and finish migration projects in months instead of years. But it’s such a big jump in performance that it’s almost hard to believe when we tell it.
“We’re now shifting to truly agentic workflows. Our engineers are orchestrating fully autonomous digital task forces, firing off agents and accomplishing incredible things.”
Now believe these figures from Google. At least 75% of all code at Google is now AI-generated, up from 50% 6 months ago, and 25% 18 months ago. Google finishes complex migration projects 6x faster than what was technically possible just a year ago. I fully expect this figure to reach close to 100% by the end of 2026 for Google once all their development processes have been reworked. When used properly, today’s AI models write better source code quality than any human, writes it faster, better tested, and better documented.
Read more:
Google Releases Eighth-Generation TPUs: Two Specialized Chips for Training and Inference

The News:
- Google announced the TPU 8t and TPU 8i at Google Cloud Next 2026, the eighth generation of its custom Tensor Processing Units, split into two purpose-built architectures for training and inference respectively.
- TPU 8t targets large-scale model pre-training and embedding-heavy workloads, supporting clusters of up to 9,600 chips in a single superpod and scaling to over 1 million TPU chips in a single training run via JAX and Pathways.
- TPU 8t introduces native FP4 precision, which doubles MXU throughput, and a new Virgo Network fabric delivering up to 4x increased data center network bandwidth and up to 47 petabits/sec of non-blocking bi-sectional bandwidth across 134,000 chips.
- TPU 8i targets low-latency inference and agentic workloads, featuring 3x more on-chip SRAM than the previous generation, a new Collectives Acceleration Engine (CAE) reducing on-chip collective latency by 5x, and a Boardfly interconnect topology that cuts chip-to-chip network diameter from 16 hops to 7.
- Google reports TPU 8t delivers 2.7x performance-per-dollar over the previous generation (Ironwood, gen 7) for large-scale training, while TPU 8i delivers 80% better performance-per-dollar for inference on large MoE models at low-latency targets. Both deliver up to 2x better performance-per-watt.
- Both chips integrate Arm-based Axion CPU headers to handle data preprocessing, removing host bottlenecks. Software support includes JAX, PyTorch (now in preview for TPUs), Keras, and vLLM. Availability is listed as “coming soon.”
My take: Better performance is always welcome, but better performance-per-watt is what makes these chips the most interesting. Both chips deliver up to 2x better performance per watt than previous generation, while also providing up to 80% better performance per dollar for inference. I believe splitting the chips into separate TPUs for pre-training and inference is the way to go for the future, and I would be very surprised if NVIDIA didn’t also go all-in on this route for their next generation chips after Vera Rubin. NVIDIA already hinted at this direction with NVLink Switches and disaggregated rack designs.
OpenAI GPT-5.5: New Model for Agentic and Knowledge Work
https://openai.com/index/introducing-gpt-5-5
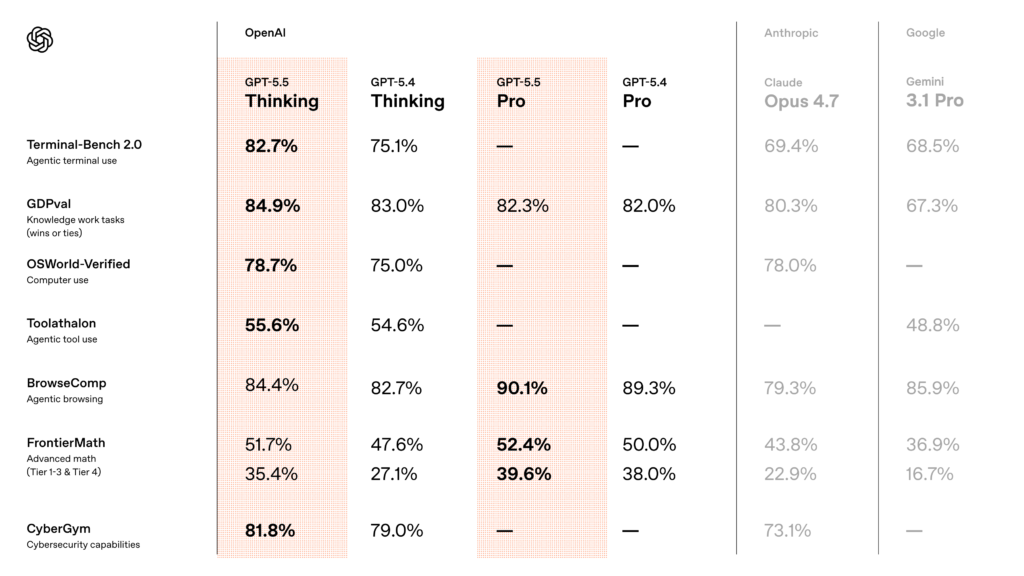
The News:
- OpenAI released GPT-5.5 on April 23, available in ChatGPT (Plus, Pro, Business, Enterprise), Codex, and the API, targeting complex multi-step workflows including coding, research, data analysis, document creation, and computer use.
- The model comes in two variants: a base model (gpt-5.5) and gpt-5.5 Pro. In the API, both run with a 1M token context window; in Codex, the context is 400K with an optional Fast mode that generates tokens 1.5x faster at 2.5x the cost.
- On Terminal-Bench 2.0, a benchmark for complex command-line agentic workflows, GPT-5.5 scores 82.7%, up 7.6 points from GPT-5.4 and 13.3 points above Claude Opus 4.7. On FrontierMath Tier 4 (advanced mathematics), it reaches 35.4%, versus 27.1% for GPT-5.4 and 22.9% for Claude Opus 4.7.
- OpenAI states that Codex running GPT-5.5 rewrote load balancing and partitioning heuristics in OpenAI’s own serving infrastructure, increasing token generation speeds by over 20%.
- The model requires less guidance to complete tasks: OpenAI’s system card describes it as understanding the task earlier, using tools more effectively, and continuing until completion without prompting.
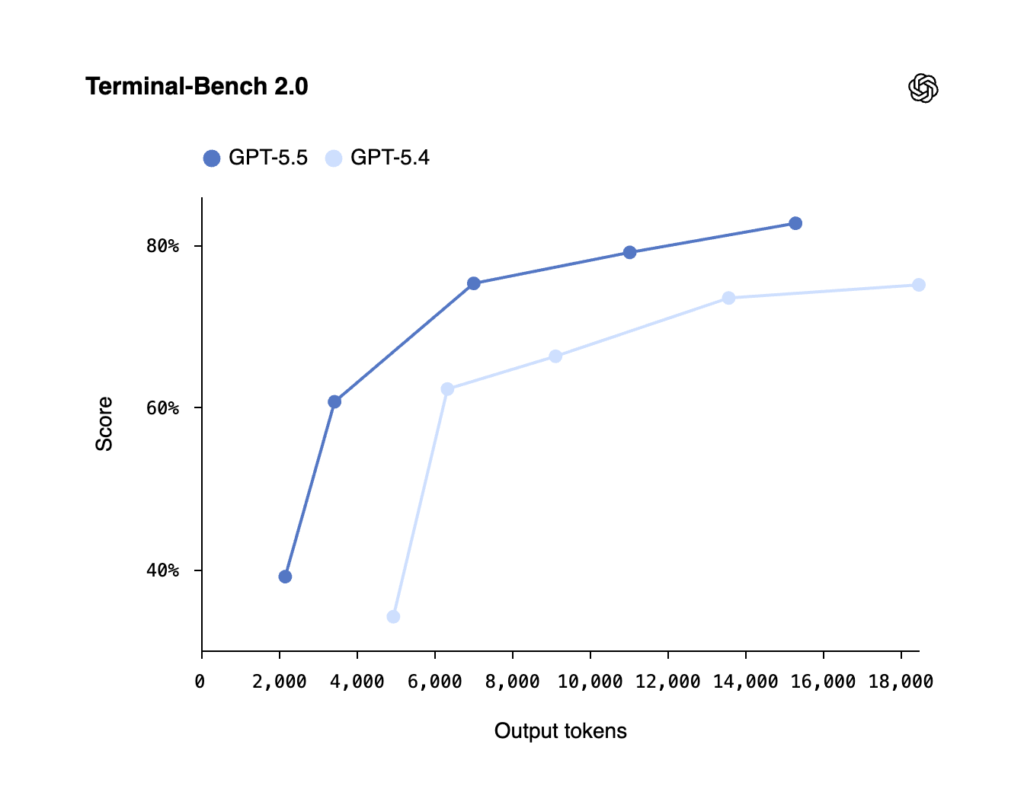
My take: GPT-5.5 is priced at $5.00 input / $30.00 output per 1M tokens, which is exactly double that of GPT-5.4 ($2.50/$15.00). This also matches the pricing model of Opus 4.7, which is priced at $5.00 input / $25.00 output (1M tokens).
What does this mean in practice? If you look at the graph above, you can see that GPT-5.5 achieves almost the same results in Medium mode as GPT-5.4 achieves in Extra High mode. GPT-5.5 does not need to think as much as GPT-5.4 to know what to do in different situations and still end up with the right decisions.
We have used GPT-5.5 extensively at TokenTek, and it’s an amazing model in everyday use. It’s smart, fast, and the generated code is often very good quality even in the first iteration. In Opus 4.7 or GPT-5.4 and previous models you always needed to iterate the code at least 2-3 times to improve quality, now very often I find the code generated by GPT-5.5 to be good enough to ship as generated. And this is a first for me.
To get a feeling just how good GPT-5.5 is at building things, check this thread on X. Also if you are curious about the work behind GPT-5.5 (code named “Spud”) checkout this interview with Greg Brockman.
Read more:
- Min Choi on X: “Ok GPT-5.5 is insane. 10 wild examples” / X
- Alex Kantrowitz on X: “OpenAI President @gdb on GPT 5.5 — a.k.a “Spud” — and what it means for the company’s direction, competitiveness, and the notion of a “compute-powered economy” / X
- Refactoring/Code Review got much better with 5.5 : r/codex
OpenAI Adds Workspace Agents to ChatGPT
https://openai.com/index/introducing-workspace-agents-in-chatgpt
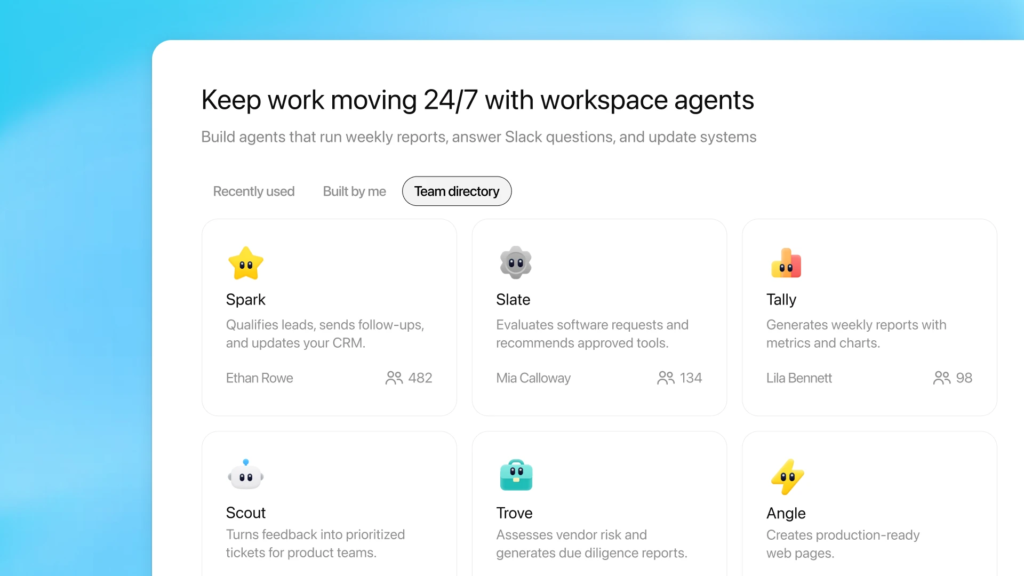
The News:
- OpenAI launched Workspace Agents in ChatGPT on April 22, as a research preview for Business, Enterprise, Edu, and Teachers plan subscribers, positioning them as a successor to GPTs for automating multi-step organizational workflows.
- The agents run in the cloud and are powered by the Codex model, enabling them to write and execute code, connect to external tools, retain memory across sessions, and continue running on a schedule even when users are offline.
- Users build agents through the ChatGPT sidebar by describing a recurring workflow in plain language or uploading a reference file; ChatGPT then defines the steps, connects tools, adds skills, and runs tests.
- Pre-built templates for finance, sales, marketing, and operations are available, each pre-configured with suggested tools and default skills.
- Agents can integrate with Slack and deliver outputs directly there; sensitive actions such as editing spreadsheets, sending emails, or adding calendar events require explicit user approval before execution.
- Access is free until May 6, 2026, after which billing switches to a credit-based model; Enterprise and Edu admins control access via role-based permissions.
My take: ChatGPT Workspace Agents are very similar to Copilot Agents. Configured in minutes, you can create new agents which you can connect to Sharepoint or Google Drive, set up tools like web search or code execution, and then expose them through Slack. For organizations that use Slack I think this will be very popular. It’s not available in the EU at launch, but should roll out here in a few weeks.
OpenAI Releases ChatGPT Images 2.0 Powered by gpt-image-2
https://openai.com/index/introducing-chatgpt-images-2-0

The News:
- OpenAI released ChatGPT Images 2.0 on April 21, powered by the new gpt-image-2 model, available in ChatGPT (including the free plan), Codex, and the API.
- The model adds a “Thinking” mode that, when activated, uses web search for real-time information, generates multiple images from a single prompt, and cross-checks outputs for accuracy and consistency.
- Text rendering is significantly improved, supporting multilingual content including Japanese, Korean, and other non-Latin scripts within images, with near-zero distortion compared to prior versions.
- The model supports flexible aspect ratios from 3:1 to 1:3, resolutions up to 4K (API beta), and can produce full infographics, multi-page educational visuals, magazine layouts, slides, and maps in a single generation.
- API pricing for gpt-image-2 is set at $8.00 per input, $2.00 for cached inputs, and $30.00 per output for images; text tokens are priced at $5.00 input, $1.25 cached, $10.00 output.
- OpenAI acknowledges the model still struggles with highly complex spatial arrangements and repetitive fine patterns, and recommends human review for technical diagrams.
- The model includes provenance tooling such as metadata tagging and watermarking at output.
My take: If you have a minute to spare, go to their web page and scroll down through all the examples of images generated with gpt-image-2. This is truly next-generation image generation, and it feels like a big step up from Google Nano Banana Pro. It’s more expensive than the previous model, but still cheap compared to stock photos. A high quality HD image will cost you $0.16 through API, and a 4K image $0.41. Of course if you use it through your ChatGPT subscription you can just keep generating images up to your weekly limit. Like programming, these image generators won’t replace designers, but it will make designers using them much more productive.
Read more:
- OpenAI’s ChatGPT Images 2.0 is here and it does multilingual text, full infographics, slides, maps, even manga — seemingly flawlessly | VentureBeat
- OpenAI API Pricing | OpenAI
- GPT Image 2 Pricing | Segmind
DeepSeek Releases V4 Preview Models with 1M-Token Context and New Architecture
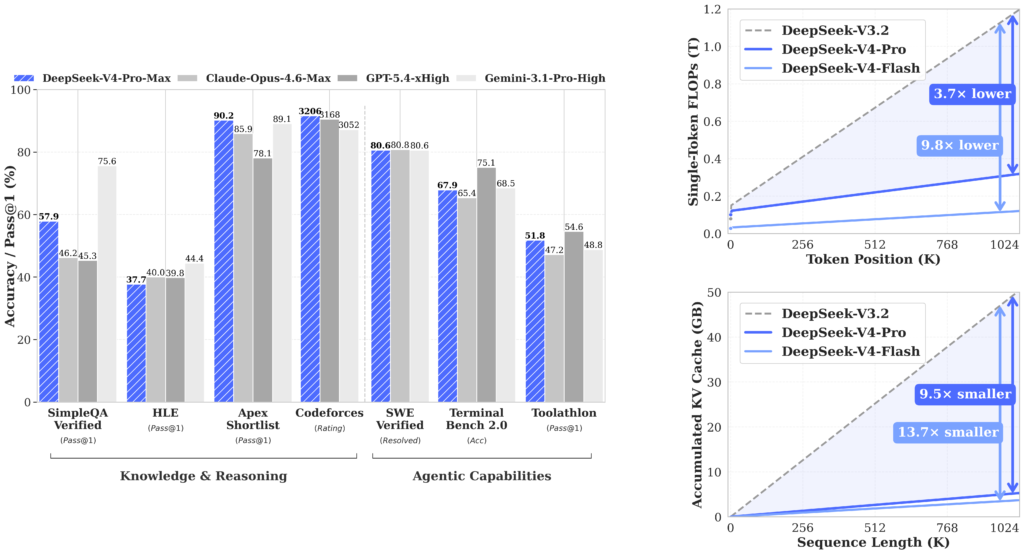
The News:
- DeepSeek released preview versions of DeepSeek V4 on April 24 in two variants: V4 Flash and V4 Pro. Both are open-source Mixture-of-Experts (MoE) models available via public API, with no finalization timeline announced.
- V4 Pro is a 1.6 trillion-parameter MoE model with 49 billion active parameters per token. V4 Flash is a 284 billion-parameter MoE with 13 billion active parameters per token. Both support a 1 million-token context window with up to 384K max output tokens.
- The company introduced a Hybrid Attention Architecture, which it states improves query recall across long conversations, and the Engram conditional memory architecture targeting 97% Needle-in-a-Haystack accuracy at million-token scale.
- V4 Pro-Max scores 80.6% on SWE-bench Verified and 93.5 on LiveCodeBench. API pricing is $0.14 per million input tokens for V4 Flash and $1.74 per million input tokens for V4 Pro.
- The existing API aliases deepseek-chat and deepseek-reasoner are marked for deprecation on July 24, 2026, and will map to V4 Flash modes for backward compatibility.
When you use our Services, we may collect your text input, prompt, uploaded files, feedback, chat history, or other content that you provide to our model and Services (“Prompts” or “Inputs”).
My take: When GPT-5.2 was launched in December 2025 it introduced a new architecture that allowed it to find and use 99% of the information stored in context memory, which made a huge difference in its ability to work reliably in complex agentic workflows. DeepSeek V4 now has a similar feature, a Hybrid Attention Architecture and a separate conditional memory mechanism called Engram which selectively stores and retrieves information based on relevance signals. Compared to GPT-5.4, Engram apparently keeps 97% accuracy all the way up to 1 million tokens, where GPT still sees a sharp drop in performance above 400k tokens.
Please be aware that our servers are located in the People’s Republic of China. When you access our services, your personal data may be processed and stored in our servers in the People’s Republic of China.
Compared to GPT-5.5 and Opus 4.7, DeepSeek V4 Pro is very cheap to use over API. Where GPT-5.5 charge $5.00 input / $30.00 output per 1M tokens, DeepSeek only charge $1.74 / $3.48 per 1M tokens, a huge difference in price. DeepSeek is however very clear that when you use their service over their API they collect “text input, prompt, uploaded files, feedback, chat history, or other content” and it is “stored in our servers in the People’s Republic of China”. Depending on what you use it for, maybe this is fine for your specific use case. For most it’s probably not something they want to run on a daily basis.
Read more:
- DeepSeek V4 Pro just dropped — is anyone actually using Chinese models in Copilot-style workflows? : r/GithubCopilot
- DeepSeek V4 (2026): 1T Parameters, 81% SWE-bench, $0.30/MTok — Full Specs | NxCode
- Models & Pricing | DeepSeek API Docs
Moonshot AI Releases Kimi K2.6 as Open-Weight Coding and Agent Model
https://www.kimi.com/blog/kimi-k2-6

The News:
- Moonshot AI released Kimi K2.6 on April 20, an open-weight, native multimodal model targeting long-horizon software engineering, agentic task execution, and front-end generation from natural language or visual prompts.
- The model uses a Mixture-of-Experts architecture with 1 trillion total parameters and 32 billion active parameters per token, a 256K token context window, 384 experts, and ships with INT4 quantization. It is released under a Modified MIT License.
- On the HLE-Full with tools benchmark, K2.6 scores 54.0, placing above GPT-5.4 (52.1), Claude Opus 4.6 (53.0), and Gemini 3.1 Pro (51.4). On SWE-Bench Pro it scores 58.6, and on SWE-bench Multilingual it scores 76.7.
- The agent swarm capability scales to 300 parallel sub-agents and 4,000 coordinated tool call steps per run, up from 100 sub-agents and 1,500 steps in K2.5. In a documented test, K2.6 ran autonomously for over 12 hours optimizing Zig inference code for an M3 Max chip, achieving a 185% medium throughput gain (0.43 to 1.24 MT/s) and a 133% performance throughput gain (1.23 to 2.86 MT/s).
- The model adds video input support absent in K2.5 and is available via API at $0.95 per million input tokens and $4.00 per million output tokens. Day-zero support is available through vLLM, OpenRouter, Cloudflare Workers AI, Baseten, MLX, and OpenCode.
My take: Like DeepSeek V4 Pro, Kimi K2.6 is very cheap at just $0.95 input / $4 output for 1 million tokens compared to the latest models from Anthropic and OpenAI. The INT4 quantized model is about ~594 GB and runs on 4x H100 80GB GPUs, but as of today there is no EU hosting exposing it. To run it today you can either run it directly through the official Moonshot AI API (Chinese infrastructure, not recommended) or a US provider like Fireworks.ai. Performance wise it looks superb, with performance on-par with or exceeding GPT-5.4 (xhigh) and Opus 4.6 (max effort).
Read more:
- Kimi K2.6 – API Pricing & Providers | OpenRouter
- Fireworks K2.6 is more than 2x faster than official Kimi K2.6 : r/kimi
- Fireworks AI: Kimi K2.6
Claude Code Fixes Three Quality Bugs
https://www.anthropic.com/engineering/april-23-postmortem
The News:
- Claude Code, Anthropic’s agentic coding tool, suffered degraded output quality for roughly six weeks due to three separate bugs introduced between March 4 and April 16. All three were marked resolved as of April 20 in v2.1.116+, and Anthropic reset usage limits for all subscribers on April 23.
- On March 4, Anthropic changed Claude Code’s default reasoning effort from high to medium to reduce UI-freezing latency. Users reported reduced intelligence, and the setting was reverted on April 7. Defaults are now xhigh for Opus 4.7 and high for all other models.
- On March 26, a caching optimization introduced a bug that cleared Claude’s reasoning history on every turn after a session went idle for over one hour, instead of just once. This caused forgetfulness, repetitive behavior, and unexpected token usage. Fixed April 10 in v2.1.101.
- On April 16, a system prompt instruction added to reduce verbosity (“keep text between tool calls to ≤25 words. Keep final responses to ≤100 words unless the task requires more detail.”) caused a measured 3% drop in benchmark scores for both Opus 4.6 and 4.7. It was reverted on April 20.
My take: Anthropic is trying everything they can to reduce GPU usage and have recent months experimented with things like changing the default reasoning level (from high to medium) or trying to force the model to produce less text trough the system prompt. They are also trying this in prod, which means it affects every user on their platform. If you have been following Reddit the past weeks you have read all the reports about Claude Code being “dumb” and Anthropic is now confirming that they are experimenting almost on a weekly basis.
The fixes Anthropic posted about in their April 23 blog post are the easy rollbacks. Boris Cherny confirmed later that day that they are aware of other issues related to Claude Code and Opus 4.7 that are yet not solved, so if you have been experiencing variations in quality you now know why. To compensate they reset all usage limits on April 23, but for issues that have been ongoing since March I’m not really sure how much one rate-limit reset will help.
It looks like Anthropic is trying everything they can do for easy wins to reduce GPU usage. It might even be that they are totally out of compute resources, and before that is solved you won’t see any new Mythos model being launched soon. This would also explain why Claude Design is still in preview with extremely limited weekly usage.
Read more:
- An update on recent Claude Code quality reports \ Anthropic
- Boris Cherny on X: “Separately, we’ve also heard reports of issues with Opus 4.7 in Claude Code. The team is working on those and we’ll share more as we roll out improvements over the coming days.” / X
Anthropic Tests Removing Claude Code from Pro Plan
https://twitter.com/TheAmolAvasare/status/2046724659039932830
The News:
- Anthropic ran a pricing test that, for a subset of new users, removed Claude Code access from the $20/month Pro plan and placed it exclusively in the Max tier, priced at around $100/month.
- The test affected approximately 2% of new prosumer signups. Existing Pro and Max subscribers were not included.
- Amol Avasare, Anthropic’s Head of Growth, stated on X: “For clarity, we’re running a small test on ~2% of new prosumer signups. Existing Pro and Max subscribers aren’t affected.”
- Avasare noted that engagement per subscriber has risen sharply as Claude Code adoption surged and users began running multi-hour, compute-heavy agentic workflows. He wrote: “Usage has changed a lot and our current plans weren’t built for this.”
- Anthropic has already introduced incremental usage controls, including weekly caps and tighter limits during peak hours, but those have not resolved the cost-to-usage mismatch.
- The test was reverted within roughly 24 hours after the post by user George Pu alleging the change reached an estimated 2.3 million views.
“Engagement per subscriber is way up. We’ve made small adjustments along the way (weekly caps, tighter limits at peak), but usage has changed a lot and our current plans weren’t built for this.” Amol Avasare, Anthropic
My take: Panic. You saw it last year at Cursor when they changed their pricing model repeated times over several weeks in an attempt to leverage the increased API costs from Anthropic with Opus 4.0 and Sonnet 3.7. And you see it this year when Anthropic suddenly stopped new signups for Claude Code. This “test” was reverted due to user critique in just 24 hours, but if you are an Anthropic and Claude Code user be prepared for more of these panic-driven initiatives in the coming months.
Lovable’s 48-Day Exposure
https://www.theregister.com/2026/04/20/lovable_denies_data_leak
The News:
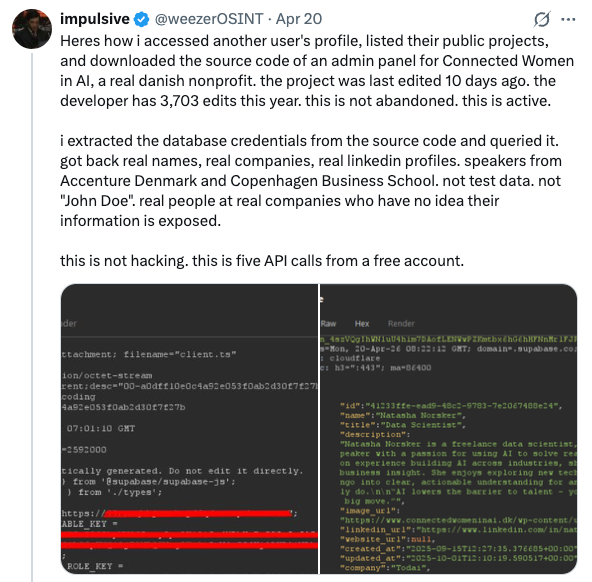
- On April 20, researcher @weezerOSINT posted on X that any authenticated Lovable account could access other users’ source code, database credentials, AI chat histories, and customer data, with the exposure affecting every project created before November 2025.
- The flaw is a Broken Object Level Authorization (BOLA) bug. Using five standard API calls from a free account, the researcher accessed another user’s profile, source code, and extracted database credentials, then queried real names, companies, and customer records. No offensive tooling was required.
- The researcher had filed the report on March 3 via HackerOne, 48 days before going public. HackerOne closed the ticket as a duplicate without escalating it to Lovable’s internal team. Lovable’s own postmortem confirms the first report actually arrived February 22, and multiple subsequent reports were also closed.
- The root cause was a February 2026 backend refactor that accidentally re-enabled access to public project chats and source code, undoing protections Lovable had deliberately built between March and November 2025.
- Lovable shipped a fix within two hours of the public post. The company is converting all historically public projects to private and conducting a review of which projects were accessed between February 3 and April 20, 2026.
My take: The first response by Lovable was posted 6.50 PM on April 20:
“We were made aware of concerns regarding the visibility of chat messages and code on Lovable projects with public visibility settings. To be clear: We did not suffer a data breach.”
Two hours later Lovable posted the following:
“We’re sorry our initial statement didn’t properly address our mistake. We retroactively patched our API so public project chats couldn’t be accessed, no matter what. Unfortunately, in February, while unifying permissions in our backend, we accidentally re-enabled access to chats on public projects.”
Two days later Lovable posted a clarification:
“We want to acknowledge and thank the researchers. They found a real issue, reported it through the proper channels, and were let down by our process.”
This is a significant issue in three ways. First off, the first bug report about this was submitted on February 22 but not escalated internally by Lovable due to their “vulnerability triage process”. Secondly when the bad news was published they immediately posted “we did not suffer a data breach” without even considering that this might be an actual data breach. And thirdly the bug affects all public projects created before November 2025 on non-enterprise accounts. If you have a Lovable project built this way, know that external parties might have gotten full access to every single chat message you sent to Lovable while building your product. Lovable are just now investigating which projects might have been leaked to external parties, and they are working on communicating these findings with the project owners.
Read more:
Meta Cuts 8,000 Jobs as AI Spending Reshapes Workforce
https://www.businessinsider.com/meta-plans-layoff-10-of-its-entire-staff-may-2026

The News:
- Meta announced on April 22 that it will cut approximately 10% of its global workforce, around 7,800 to 8,000 employees, effective May 20.
- The company is also closing roughly 6,000 open roles it had planned to fill.
- Chief People Officer Janelle Gale stated in an internal memo: “We’re doing this as part of our continued effort to run the company more efficiently and to allow us to offset the other investments we’re making.”
- Meta projects capital expenditures of $115 to $135 billion in AI-related infrastructure in 2026, including large-scale data centers and compensation for AI researchers.
- Affected employees in the US receive 16 weeks of base salary plus two additional weeks per year of service, and COBRA health coverage for 18 months.
- Reuters reports this is the first wave, with additional layoffs planned for the second half of 2026.
“While we have seen significant layoffs at companies like Block who laid off 40% of headcount ‘due to AI’, if Meta is willing to reduce headcount at this scale while ramping AI investment, we think it signals a broader shift: AI is increasingly driving productivity” cnbc
My take: Four weeks ago Oracle fired 30,000 employees via email due to increased AI spending, and last week Meta announced they will cut 10% of its global workforce due to increased AI spending. If you read my introduction to this newsletter you have a fairly good idea what’s happening, and these organizational changes are done in preparation for cost increases that are coming later this year. It is clear that AI infrastructure and systems will mostly be financed from the salary budget within most companies, and I think this is just the start. Meta is restructuring the entire company around AI productivity, and they have also introduced new titles like “AI builder”, “AI pod lead” and “AI org lead” to help drive this transition.
Read more: