Tech Insights 2026 Week 17
April 20, 2026

Two years ago in the summer of 2024 OpenAI launched their first ChatGPT desktop app for macOS. Back then we didn’t have agentic engineering, so the entire app was hand coded using the Apple Swift framework. It took five additional months for OpenAI to ship the ChatGPT desktop app for Windows, but that app was written in React and Typescript and had several limitations compared to the macOS app. They shared no logic internally.
Fast forward to 2026, and AI now writes all the code at OpenAI. At the speed things are moving now it’s even more difficult than before to have two code bases to maintain. With separate code bases you need separate teams working on each platform, and they need to sync regularly to avoid code drift. And that scales very poorly with autonomous agentic AI.
Two months ago, in February, OpenAI launched their new Codex desktop app, which was built from the ground up in React and Typescript for both macOS and Windows. One code base, two platforms. The first version was more like a basic wrapper for Codex CLI and built in weeks, not months. But the benefits of building with React is that AI models are very efficient producing high quality source code for it, and it’s extremely easy to set up test pipelines with high accuracy.
Fast forward to last week where OpenAI launched Codex for (almost) everything. This new version has a web browser, computer-use, image generation, tasks, basically every feature the regular ChatGPT desktop app has and much more. And all this was added in just two months for 3 million users. This gives you an idea of the true power of agentic engineering when you have well-trained teams using it.
So think about this in the context of your own company. Do you have custom software running on multiple platforms with separate code bases supported by separate teams? Or do you have old legacy systems where every change is high-risk and slow due to the lack of unit or system tests? Or maybe you use a simple but expensive SaaS subscription you pay for every month. There has never been a better time than now to do something about it.
Today at the conference GAIA 2026 - Göteborg Artificial Intelligence Alliance I will present my own development process with agentic engineering: how to create complex applications with hundreds of thousands of users with very high quality source code and no critical bugs. Please come by and say hi if you are visiting the conference (I will be in the TokenTek booth), otherwise all talks will be published for free online so I will add a link to it in a future newsletter once it’s available.
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2026 Week 17 on Spotify
Notable model releases last week:
- HY-World 2.0. Tencent-Hunyuan’s new multimodal world model that generates, reconstructs, and simulates interactive 3D environments from text, images, or video inputs, with direct export to Unity and Unreal Engine 5.
THIS WEEK’S NEWS:
- OpenAI Expands Desktop Codex Into a General-Purpose Agent
- OpenAI Introduces GPT-Rosalind for Life Sciences Research
- OpenAI Releases GPT-5.4-Cyber
- OpenAI Agents SDK Gets Sandboxed Execution, Native Memory, and Filesystem Tools
- Anthropic Releases Claude Opus 4.7 With Coding and Vision Gains
- Anthropic Launches Claude Design, a Conversational AI Design Tool
- Canva AI 2.0 Turns the Design Platform Into an Agentic Work Suite
- Google Launches Gemini 3.1 Flash TTS With Granular Audio Tags
- Cursor Adds Canvas: Agents Now Generate Interactive Interfaces Inside the IDE
- Cursor and NVIDIA use AI Agents to Automate GPU Optimizations
- Kepler Communications Opens Orbital Compute Cluster for Commercial Use
- Lovable Launches Built-In Payment Processing
- Windsurf 2.0 Adds Cloud Agent Delegation and Multi-Agent Management
- GitHub Copilot CLI Introduces “Rubber Duck” Cross-Model Review
OpenAI Expands Desktop Codex Into a General-Purpose Agent
https://openai.com/index/codex-for-almost-everything/

The News:
- OpenAI released a major Codex update on April 16, adding computer use, an in-app browser, image generation, persistent memory, scheduling, and over 90 plugins, extending Codex from a coding assistant into a broader desktop agent.
- Background Computer Use runs with its own cursor and context on macOS, separate from the user’s active session, so multiple Codex agents can operate in parallel without conflicting with each other or with the user’s mouse.
- An in-app browser lets users annotate live web pages directly to issue instructions, for example marking a tagline and typing “make the font smaller and shorten the text,” with Codex handling the change automatically.
- Image generation via gpt-image-1.5 is now built into workflows, so users can prompt Codex to “generate and embed an image at the top” of a page without leaving the tool.
- A scheduling feature allows automations to run on recurring intervals spanning days or weeks, with example prompts like “Check Slack, Gmail, Google Calendar, and Notion every hour and flag what seems important.”
- A memory preview lets Codex retain preferences and context across sessions, and a proactive suggestions feature can propose work items at the start of a session based on open pull requests, Slack threads, and Notion documents.
“Personalization features including context-aware suggestions and memory will roll out to Enterprise, Edu, and EU and UK users soon. Computer use is initially available on macOS, and will roll out to EU and UK users soon.”
My take: It looks like this new Codex app will be the main app for most OpenAI users going forward, and I would not be surprised if they slowly started to phase out the ChatGPT and Atlas desktop applications. Codex now includes a web browser, has memory like the ChatGPT app, can run multiple tasks in parallel, can produce images, can control your computer, run scheduled tasks, and run over 90 plugins. OpenAI is really pushing Codex as the do-everything-application that will be your main interface to everything you want to do at your computer.
My only concern with this approach is that if you do indeed go all-in on this approach: let Codex control your computer, run your applications, run your scheduled tasks, and so on, it’s getting difficult to keep track of exactly what the AI is doing, and since it’s running with your credentials it can do everything you can do at your computer, including accessing all files on both your computer and your local network. In practice Codex is very quickly approaching OpenClaw in functionality, and I am not 100% sure I believe this is the right way to go for most users.
OpenAI Introduces GPT-Rosalind for Life Sciences Research
https://openai.com/index/introducing-gpt-rosalind/

The News:
- On April 16 OpenAI released GPT-Rosalind, a reasoning model built for life sciences research, covering drug discovery, genomics, protein engineering, and translational medicine.
- The model is named after Rosalind Franklin, the British scientist whose work contributed to the discovery of the DNA double helix structure.
- It supports multi-step research tasks including evidence synthesis, hypothesis generation, experimental planning, sequence analysis, and literature search.
- GPT-Rosalind outperformed GPT-5, GPT-5.2, and GPT-5.4 on internal benchmarks for chemistry, protein understanding, genomics, and experimental design, with the largest gains in experimental design and chemistry.
- On BixBench, which simulates real-world bioinformatics and data analysis, GPT-Rosalind achieved a Pass@1 score of 0.751, the highest reported among publicly available models at launch.
- On LABBench2, which tests literature search, database use, sequence manipulation, and protocol design, GPT-Rosalind scored above GPT-5.4 on 6 of 11 task categories, with the largest improvement in CloningQA, a benchmark for end-to-end design of DNA and enzyme reagents for molecular cloning.
- A free Life Sciences Research Plugin for Codex connects to over 50 public multi-omics databases, literature sources, and biological tools; existing credits and tokens are not consumed during the research preview period.
- Access is currently limited to qualified enterprise customers in the United States conducting legitimate scientific research with a public interest mandate, including Amgen, Moderna, the Allen Institute, and Thermo Fisher Scientific.
- OpenAI describes GPT-Rosalind as the first release in a planned life sciences model series, with future work targeting improvements to biochemical reasoning and longer-term, tool-dependent research workflows.
“We view it as the beginning of a long-term commitment to building AI that can accelerate scientific discovery in areas that matter deeply to society, from human health to broader biological research.”
My take: The areas where GPT-Rosalind excel are complex domains such as chemistry, protein understanding and genomics, and making a general foundation model like the regular GPT-5.4 a true expert in those areas would probably just make it too large for very few use cases for the general public. I don’t think this initiative would have been possible 2 years ago but now when Reinforcement Learning with Verifiable Rewards (RLVR) works as well as it does, I think it’s technically feasible to maintain a separate branch like GPT-Rosalind as a high-priority side project inside OpenAI going forward.
OpenAI Releases GPT-5.4-Cyber
https://openai.com/index/scaling-trusted-access-for-cyber-defense/

The News:
- OpenAI expanded its Trusted Access for Cyber (TAC) program on April 14, scaling it to thousands of verified individual defenders and hundreds of security teams, and released GPT-5.4-Cyber, a fine-tuned variant of GPT-5.4 for defensive cybersecurity tasks.
- GPT-5.4-Cyber has a lower refusal threshold for dual-use security prompts deemed to serve a legitimate defensive purpose, including binary reverse engineering of compiled software without access to source code.
- Access is tiered: individuals verify identity at chatgpt.com/cyber, enterprises apply through an OpenAI account representative, and a further invite-only tier exists for teams requiring broader capabilities.
- GPT-5.4-Cyber is not available in zero-data-retention environments, as OpenAI cites reduced visibility into user context as a necessary control.
- OpenAI’s Codex Security agent, in research preview, has fixed over 3,000 critical and high-severity vulnerabilities across codebases since launch.
- OpenAI’s Cybersecurity Grant Program commits $10 million in API credits, targeting teams with track records in vulnerability discovery and remediation in open-source software and critical infrastructure.
“Since the recent launch, Codex Security has contributed to over 3,000 critical and high fixed vulnerabilities, along with many more lower-severity fixed findings across the ecosystem.”
My take: If you are working full time with cyber security you can apply for access at chatgpt.com/cyber . This grants baseline TAC access, not GPT-5.4-Cyber. To get access to GPT-5.4-Cyber you need the highest TAC tier. Eligible categories include security vendors, security researchers, and organizations securing critical software. U.S. government agencies are not yet eligible. The main difference between 5.4-Cyber and 5.4 is it’s lower refusal threshold for dual-use cyber tasks, which means that areas 5.4 would not allow use is allowed in 5.4-Cyber, for tasks like penetration testing or reverse-engineering compiled software.
Read more:
OpenAI Agents SDK Gets Sandboxed Execution, Native Memory, and Filesystem Tools
https://openai.com/index/the-next-evolution-of-the-agents-sdk/

The News:
- OpenAI released a major update to its open-source Agents SDK on April 15, extending the framework with native sandbox execution, configurable memory, and a model-native harness for managing files, shell commands, and long-running tasks.
- The update includes a model-native harness that manages tool execution, file inspection, apply-patch style file edits, retries, timeouts, and logging, replacing infrastructure most teams were previously building themselves.
- Native sandbox execution isolates shell commands and file operations inside controlled environments with restricted network egress and resource limits, making shell access viable in regulated enterprise settings.
- Configurable memory lets developers define what gets stored, for how long, at what granularity, and with what retrieval behavior, separating task memory, project memory, and policy constraints.
- MCP (Model Context Protocol) integrations are included for connecting agents to external tools like CRMs, ticketing systems, and internal knowledge bases via standardized interfaces.
- Python is supported at launch; TypeScript support is planned for a later release.
My take: Great news if you are developing your own agentic solutions with a source code framework. If you do that, you are using OpenAI models exclusively, and you would like to use features like sandbox execution and full GPT-5.4 feature access, then go investigate the new OpenAI Agents SDK and see if it would be a good fit for you. However if you are using a mixture of models from different providers, you need to continue with whatever framework you are already using since the Agents SDK only supports OpenAI models.
Anthropic Releases Claude Opus 4.7 With Coding and Vision Gains
https://www.anthropic.com/news/claude-opus-4-7
The News:
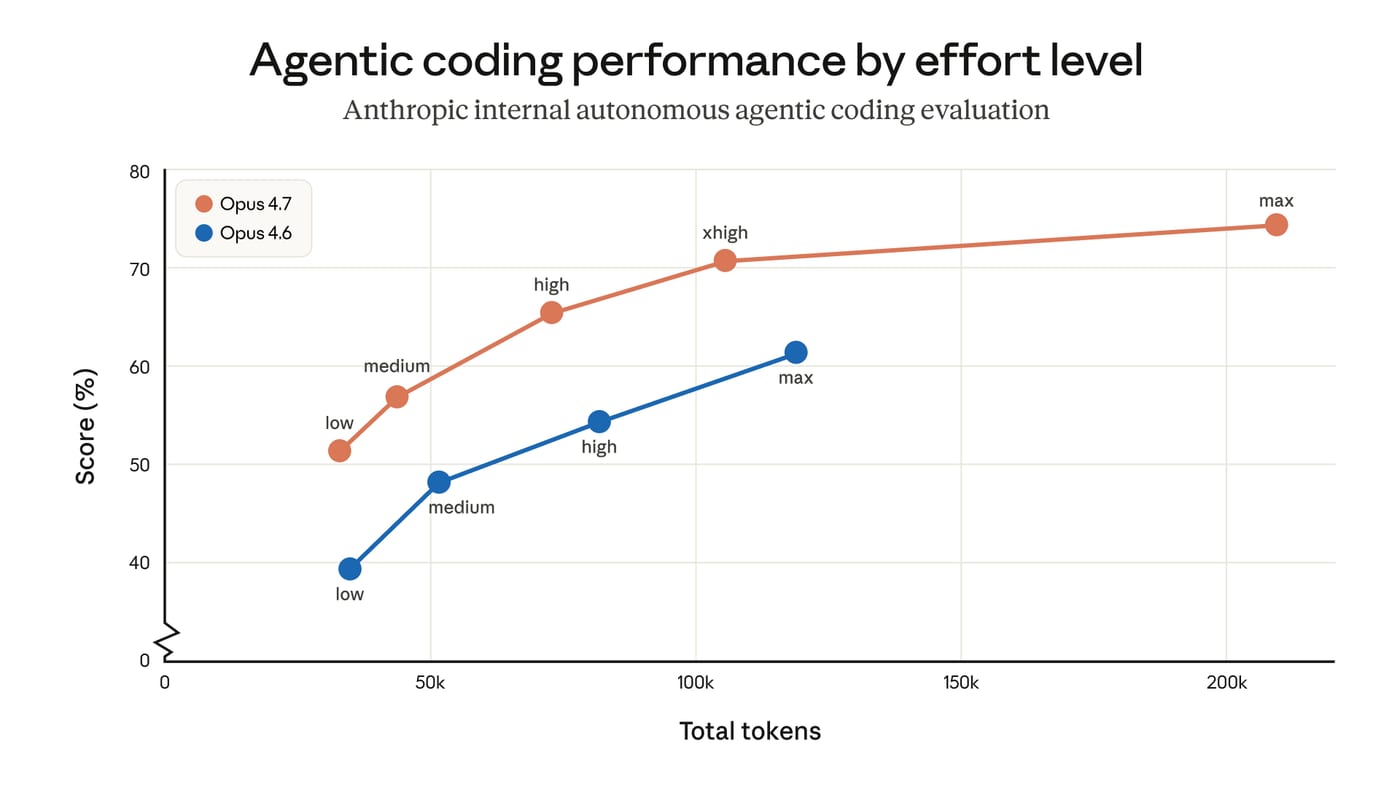
- Anthropic released Claude Opus 4.7 on April 16, a hybrid reasoning model positioned as the most capable generally available model in the Claude lineup, below the restricted Claude Mythos Preview.
- On a 93-task coding benchmark run by one early-access partner, Opus 4.7 resolved 13% more tasks than Opus 4.6, including four tasks neither Opus 4.6 nor Sonnet 4.6 could solve. Cursor reports 70% task clearance on CursorBench versus 58% for Opus 4.6.
- Maximum image resolution support has increased to 2,576px on the long edge (3.75 megapixels), more than three times the prior limit, which affects use cases like computer-use agents reading dense screenshots and extraction from complex technical diagrams.
- A new “xhigh” effort level sits between the existing “high” and “max” settings; Claude Code now defaults to xhigh for all plans. A new “/ultrareview” command in Claude Code runs a dedicated review session to surface bugs and design issues.
- Pricing stays at $5 per million input tokens and $25 per million output tokens, identical to Opus 4.6. The model is available via the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
- Cybersecurity capabilities were deliberately constrained compared to Mythos Preview during training, and automatic safeguards now detect and block high-risk cybersecurity requests. Legitimate security professionals can apply to a new Cyber Verification Program for access.
“Our entire team is hitting these limits. Not in a single prompt, but can’t get through a full session. The only solution we’ve come up with is multiple accounts to let the others cool down.”
My take: On paper Opus 4.7 seems to be a good solid upgrade over Opus 4.6, especially in agentic use, and the new expanded image resolution support is very welcome. However, while Anthropic literally says “pricing remains the same as Opus 4.6”, they also say that “the same input can map to 1.35× tokens depending on the content type”. And this seems consistent with early user reports.
This means that costs of running this over API will be more expensive than running Opus 4.6 for the same task. And for those of you running Claude Opus 4.6 in GitHub Copilot you are in for a small chock. First of all - Microsoft is phasing out Opus 4.5 and 4.6 for Pro+ users and will only provide the new 4.7. Secondly, the new 4.7 will consume 7.5x premium requests when used in GitHub Copilot until April 30 as a “promotional pricing”. After that it will consume even more premium requests. How much more? No-one knows.
Secondly, to keep up with the increased API prices, especially with Anthropic models, Microsoft GitHub Copilot has also introduced new rate limits. If you previously could work with agentic development for hours in GitHub Copilot, now you might hit the limit in minutes. The reason for this is that all Anthropic models are served from Anthropic’s infrastructure in the US, not Microsoft, and their capacity is nearly full. This means that those who pay the least (GitHub Copilot that charge users per request) will now have to wait the longest.
At the time writing this newsletter there have been 110 threads on Reddit about Opus 4.7 where 37% has been explicitly negative (e.g. “dogshit”, “unusable”, “legendarily bad”). I browsed through a dozen or so of them, and almost every single negative feedback was from users using it at low or no reasoning. Apparently Opus 4.5 and 4.6 worked quite fine with low to no reasoning, but 4.7 fails for even simple tasks here. I guess the main reason people used it at these settings was to work around the rate limits and improve speed. So before you start your work this week - do a quick check so you use xhigh reasoning and you should be all set.
Read more:
- Opus 4.7: 110 threads, 2,187 comments. Unbiased analysis : r/ClaudeCode
- Copilot Pro+ is a joke: Rate limited after one prompt, even after an overnight cooldown. : r/GithubCopilot
- Claude Opus 4.7 is generally available - GitHub Changelog
- Enforcing new limits and retiring Opus 4.6 Fast from Copilot Pro+ - GitHub Changelog
- Differences Between Opus 4.6 and Opus 4.7 on MineBench : r/ClaudeAI
Anthropic Launches Claude Design, a Conversational AI Design Tool
https://www.anthropic.com/news/claude-design-anthropic-labs

The News:
- Claude Design is a new Anthropic Labs product, released April 17, in research preview for Pro, Max, Team, and Enterprise subscribers, that converts text prompts into prototypes, slide decks, one-pagers, wireframes, and marketing materials.
- It runs on Claude Opus 4.7, Anthropic’s latest vision model, which processes images at higher resolution than prior versions.
- Users refine output through conversation, inline comments, direct edits, or custom sliders that Claude generates on demand.
- During onboarding, Claude reads a team’s codebase and design files to build a design system automatically, then applies that system’s colors, typography, and components to every subsequent project.
- Projects can include voice, video, 3D, and shader elements, and export to Canva, PDF, PPTX, and HTML, with a direct handoff path to Claude Code for production-ready development.
“When a design is ready to build, Claude packages everything into a handoff bundle that you can pass to Claude Code with a single instruction.”
My take: Now this was an interesting week. For over a year Anthropic and Figma had a strong and cooperative collaboration together. Mike Krieger, one of the co-founders of Instagram, joined Anthropic as CPO in 2024 and has been on the Figma’s board of directors for around a year.
Last Monday on April 14, The Information published an exclusive briefing called “Anthropic Preps Opus 4.7 Model, AI Design Tool”, citing a person with internal knowledge of both products. Figma’s stock dropped 6% immediately on the news about the new design tool. Later that day Mike Krieger resigned from the Figma board of directors, and three days later Anthropic launches Claude Design.
If you have a few minutes, I really recommend that you checkout these 10 Claude Design examples, or why not this 18-min tutorial how to build animated, award-winning websites with Claude Design + Opus 4.7. This is impressive stuff.
I am really impressed by Claude Design, and it clearly shows where we are heading. Anthropic and OpenAI are both pushing for one-tool-does-everything, and the only way SaaS companies like Canva, Figma and Lovable will be able to compete is to offer things like prebuilt integrations and templates. The challenge for these services is that this is a low-cost offering, the thing that customers are willing to pay for is creation, not integration. And speaking of integration, when you are done with your design in Claude Design you just tell it to send it to Claude Code and it will package everything with a single instruction. This is something no other design service offers today, and I think this combination will be very tough to beat.
Read more:
- Min Choi on X: “It’s over. Claude Design is generating insane UI, designs & animations from just text.” / X
- Viktor Oddy on X: “Claude Design is insane. ❤️🔥Just recorded a 18-min tutorial on how to build animated, award-winning websites with Claude Design + Opus 4.7!” / X
- R.I.P. Figma and Canva? Inside Anthropic’s 24-Hour Assassination of a $60B Market - Kingy AI
- Anthropic launches Claude Design, a new product for creating quick visuals | TechCrunch
Canva AI 2.0 Turns the Design Platform Into an Agentic Work Suite
https://www.canva.com/newsroom/news/canva-create-2026-ai/
The News:
- Canva AI 2.0 launched on April 16 as a research preview at the company’s annual Create event in Los Angeles, rolling out to the first one million users who access the Canva homepage, with broader availability to follow.
- The update replaces point-and-click tool access with a conversational, agentic layer: users describe an outcome in text or voice, and the AI selects the relevant tools and builds a finished design from start to finish.
- Canva built the update around nine distinct capabilities, including: a memory library that stores style and brand preferences across sessions; Brand Intelligence that applies those settings to new designs automatically; Layered Object Intelligence that keeps every text box, image, and graphic individually editable after generation; and a Scheduling feature that runs design tasks offline and overnight.
- Canva AI Connectors pulls live context from Gmail, Slack, Google Drive, Outlook, and Calendar to generate content without manual input. A Web Research function retrieves source material directly into the canvas.
- Canva Code 2.0 accepts HTML or code files and converts them into fully editable Canva designs. Users can add interactive elements such as polls, countdown timers, and forms through natural language prompts.
- COO Cliff Obrecht tied the launch to a broader platform shift: the company intends to move from feature-based subscription tiers to an AI credits model before its planned IPO, now deferred to 2027. Canva currently reports 265 million monthly users and $4 billion in annual revenue.
My take: Ok, so how does Canva AI 2.0 compare to Claude Design? First of all, Canva AI 2.0 does not use Claude, it uses Canvas’ own proprietary foundation models Proteus, Lucid Origin, and I2V which according to Canva are “up to 7x faster and 30x cheaper than comparable frontier alternatives”. They don’t say anything about quality though. Secondly, designs created in Canva are stored in a proprietary format and you cannot export the designs directly to code like you can with Claude Design. You need to use an AI agent to build the source code based on the design, but when it comes to Claude Design the code is already built. The design is the code. This is a huge difference.
If you only work with product design and have no intention of ever going directly from design to code, then Canva AI 2.0 provides a compelling alternative. Going forward however I think this market is becoming smaller and smaller, and this is probably one of the reasons Canva pushed their IPO at least until 2027.
Read more:
Google Launches Gemini 3.1 Flash TTS With Granular Audio Tags
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-tts/
The News:
- Google released Gemini 3.1 Flash TTS on April 15, a text-to-speech model available in preview via the Gemini API, Google AI Studio, Vertex AI, and Google Vids for Workspace subscribers.
- The model introduces over 200 audio tags, such as [whispers], [determination], and [enthusiasm], embedded directly into input text to control vocal style, tone, tempo, and accent without separate configuration.
- It supports native multi-speaker dialogue without requiring separate model calls per speaker, and covers 70+ languages with regional accent options, including multiple American and British English variants.
- Pricing is set at $1.00 per million input tokens and $20.00 per million audio output tokens, with a 50% discount available through batch mode.
- All audio output is watermarked using Google’s SynthID technology, embedding an imperceptible signal for AI-generated content detection.
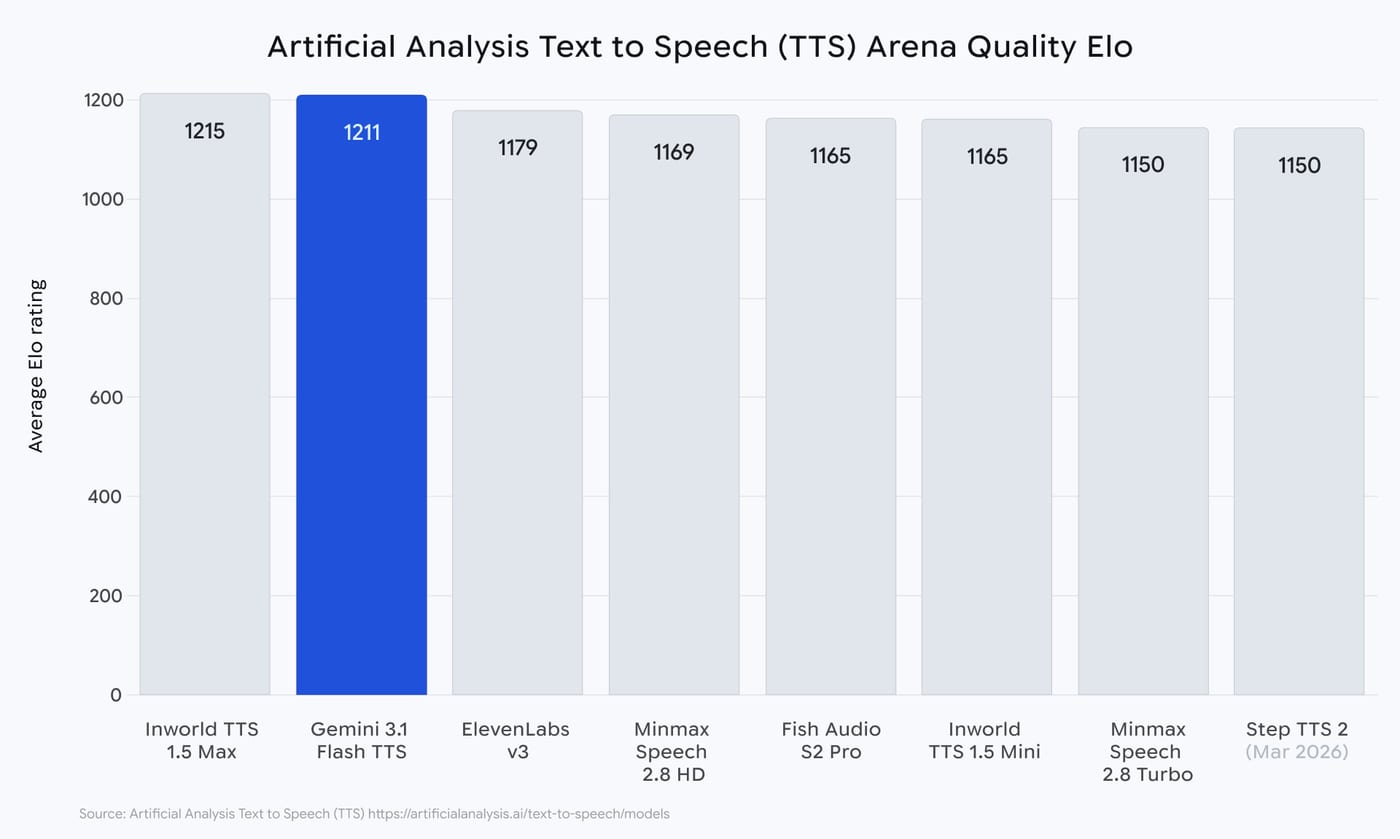
- On the Artificial Analysis TTS leaderboard, the model achieved an Elo score of 1,211, placing it second overall, ahead of ElevenLabs v3.
My take: 200 audio tags, 70+ languages, and multi-speaker dialog. And it sounds great! If you have a few minutes, go to their launch page, scroll down to “New audio tags for more expressive speech generation” and listen do the demos. I really liked this.
Be aware however that some users have reported issues with running it longer than 60 seconds, so if you are planning to use it for audiobooks, walking tours or training modules you need to try it first before shifting from 2.5 Pro.
Read more:
Cursor Adds Canvas: Agents Now Generate Interactive Interfaces Inside the IDE
https://cursor.com/blog/canvas

The News:
- Cursor 3.1 released on April 15 introduces Canvas, a feature that lets AI agents generate persistent, interactive React interfaces directly in the Agents Window, replacing text-heavy chat outputs with visual dashboards, tables, diff views, and diagrams.
- Canvases are built using a React-based UI library with first-party components including tables, boxes, diagrams, and charts, as well as existing Cursor components such as diffs and to-do lists.
- Canvases are durable artifacts that live in the side panel alongside the terminal, browser, and source control in the Agents Window.
- For PR reviews, agents can group changes by importance and present a structured interface for navigating the change set, rather than displaying all diffs in a flat list.
- Users can define custom “Skills” to control how agents generate canvases. The Docs Canvas Skill, available on the Cursor Marketplace, generates interactive architecture diagrams for any code repository.
- The Cursor team used Canvas internally for eval analysis during model rollouts: agents ingest rollout data, categorize failure causes, and generate an interactive analytical interface, reducing the need to build a separate web app for troubleshooting.
My take: It makes sense, that when code takes no effort to write, then why wouldn’t an AI create unique visual representations of each pull request or issue that makes it easier for the reader to get a quick overview of the problem at hand, rather than having to scroll through hundreds of lines of text? I was very impressed with this new feature, and it clearly gives you a view into a future where user interfaces are created ad hoc based on not only the task at hand but also the person using it.
Cursor and NVIDIA use AI Agents to Automate GPU Optimizations
https://cursor.com/blog/multi-agent-kernels

The News:
- Cursor’s multi-agent system, built in collaboration with NVIDIA, autonomously optimized 235 real GPU workloads in three weeks, achieving performance gains that would typically require months of work from specialized hardware engineers.
- GPU optimization directly affects the cost and speed of running AI models. Faster GPU software means lower cost per AI inference, reduced energy consumption, and the ability to run larger models on existing hardware.
- The system ran without developer intervention. A coordinator agent distributed 235 tasks across worker agents, which independently tested, debugged, and iterated on solutions, with the entire orchestration defined in a single text file.
- Across 235 real workloads drawn from production models including DeepSeek, Qwen, Gemma, and Stable Diffusion, the system outperformed existing software on 149 of them (63%), with an average 38% speedup. On 45 of the 235 tasks (19%), it delivered more than 2x improvement.
- On one specific workload used in Llama 3.1 8B inference, the system matched 97% of theoretical hardware limits and delivered an 84% speedup over an existing human-optimized library. When deployed in a real serving stack, this translated to a 3% faster response time.
- On matrix multiplication, historically reserved for the most experienced GPU engineers, the system reached 86% of NVIDIA’s own hand-tuned library, and on certain inference workloads it outperformed that library by up to 9%.
“The multi-agent system independently learned to call the benchmarking pipeline during its runs, creating a loop where the system continuously tested, debugged, and optimized kernels without any developer intervention.”
My take: What makes this news special is that it is a very good example of a broader trend right now: multi-agent systems operating autonomously on problems where no known correct answer exists upfront. The median score across all 235 tasks was 0.56 out of 1.0, meaning the system left meaningful room for further optimization, constrained primarily by having only 27 GPUs available across hundreds of parallel tasks. It’s no longer a question if the future belongs to agents running in iterative loops, it’s just a question of compute access.
Kepler Communications Opens Orbital Compute Cluster for Commercial Use
https://techcrunch.com/2026/04/13/the-largest-orbital-compute-cluster-is-open-for-business/

The News:
- Kepler Communications, a Toronto-based satellite operator, opened its orbital compute cluster for commercial use last week, offering space-based GPU processing as an alternative to terrestrial data center capacity.
- The cluster consists of approximately 40 Nvidia Orin edge processors distributed across 10 satellites, linked by laser communication links. It launched in January 2026.
- Kepler now serves 18 customers. Its newest customer, Sophia Space, will upload its operating system to one of Kepler’s satellites and attempt to configure it across six GPUs on two spacecraft.
- Kepler CEO Mina Mitry positions the company as infrastructure rather than a data center operator: “Because we have the belief it’s more inference than training, we want more distributed GPUs that do inference, rather than one superpower GPU that has the training workload capacity.” He adds: “Our GPUs are running 100% of the time.”
- The U.S. military is among the customers, using Kepler’s edge processing for missile defense work that requires satellites to detect and track threats. Kepler has already demonstrated a space-to-air laser link in a government demo.
My take: Kepler has deployed 10 satellites with Nvidia Orin edge processors, with the goal of processing data before it’s being transmitted down to earth. The main benefit is processing on edge and avoiding sending large data volumes down to earth for processing. The idea is that when other sensor satellites come within range of this data center they can send their data using a laser link to be processed in space, with results downlinked to earth via Kepler’s ground network.
In practice however, these 10 satellites orbit at around 575 km with laser links that have a practical range of about 2,000 km. Considering the satellites orbit earth at ~7.5km/s, this only gives a few minutes for satellites to transfer their data to this orbital data center. The only way to get this to work is if this data center and the satellites share orbit planes and use the same SDA-standard laser terminals. This means that I wouldn’t rate this high as a “general use commercial space orbit data center”, but more a niche launch for missile defense systems used by the Department of War.
Read more:
Lovable Launches Built-In Payment Processing
https://docs.lovable.dev/features/payments

The News:
- Lovable launched Lovable Payments on April 13, adding native monetization directly into the platform via Stripe, Paddle, or Shopify, without requiring users to set up external payment accounts beforehand.
- Lovable creates the merchant account, connects it to the project, and manages webhooks through Lovable Cloud, which must be enabled; users initiate the entire setup via a chat prompt, such as “Add a pricing page with a $29/month subscription.”
- Paddle acts as Merchant of Record, automatically handling VAT and sales tax collection and remittance across 200+ countries; Stripe shifts tax and legal responsibility to the developer.
- Paddle charges 5% + $0.50 per transaction with a flat 10% cap for items under $10; Stripe uses standard pay-as-you-go rates with reduced micro-transaction pricing available on request.
- A built-in Payments tab in the project toolbar displays revenue analytics over 7, 30, or 90-day ranges, transaction history, refunds, chargebacks, and a go-live checklist for switching from test to production mode.
- The feature requires a Pro plan or higher; each project supports only one payment provider and cannot be remixed after payments are enabled.
My take: Before Lovable Payments, developers using Lovable had to manually configure Stripe API keys, set up webhooks, and handle all tax compliance independently. The new native layer eliminates those steps by embedding the setup straight into the chat interface. This is why Lovable is so great, it’s that they manage to simplify even complex things like payments using a well-defined and simple to use interface.
Windsurf 2.0 Adds Cloud Agent Delegation and Multi-Agent Management
https://windsurf.com/blog/windsurf-2-0

The News:
- Windsurf 2.0, announced on April 15, adds the Agent Command Center and native Devin integration, letting developers manage local and cloud agents from within the IDE.
- The Agent Command Center is a Kanban-style interface showing all agent sessions, both local Cascade sessions and cloud Devin sessions, grouped by status in one view.
- Spaces bundle agent sessions, pull requests, files, and project context around a single task. Switching between Spaces switches the full task context, so work can be resumed without re-establishing state.
- Devin is Cognition’s autonomous cloud agent, previously sold as a standalone product. It runs on its own VM with a desktop and browser, and can continue executing after the local machine is closed.
- A developer can draft a plan with a local Cascade session, send it to Devin with one click, and review the resulting pull request, run tests, or hand it back to a local agent, all without leaving the editor.
- Devin is included with Pro, Max, and Teams plans and consumes from the shared Windsurf quota. New users who connect GitHub receive up to $50 in extra usage credits. Enterprise access requires admin enablement.
My take: Much like the new agentic interface of Cursor 3.0, the new Agent Command Center in Windsurf is a separate workspace dedicated to working exclusively with agent sessions. Both Windsurf and Cursor still keep the “old” IDE way of working, but I think it’s just a matter of time before all tools become agentic-first and the IDE will be a legacy mode that people start once in a while for nostalgic reasons. But I am genuinely curious - do you use Windsurf? Why? Tell me in comments on LinkedIn.
GitHub Copilot CLI Introduces “Rubber Duck” Cross-Model Review

The News:
- GitHub Copilot CLI adds a feature called Rubber Duck, now in experimental mode, that assigns a second AI model from a different model family to independently review the primary agent’s plans and work.
- When a Claude model (Opus, Sonnet, or Haiku) is selected as the orchestrator, Rubber Duck runs on GPT-5.4, and GitHub states it is exploring additional model-family pairings for future configurations.
- GitHub’s internal benchmarks show that Claude Sonnet with Rubber Duck active makes up 74.7% of the performance gap between Sonnet and Opus alone on difficult multi-file and long-running tasks.
- On a set of hard benchmark problems, Sonnet with Rubber Duck scores 3.8% higher than the Sonnet baseline overall, and 4.8% higher on the hardest identified problems across three trials.
- Rubber Duck is triggered automatically at specific checkpoints (after planning, after complex implementations, and after writing tests) and can also be triggered manually on demand.
- Access requires the /experimental slash command in GitHub Copilot CLI, a Claude model selected in the model picker, and access to GPT-5.4.
My take: The only benchmark for Rubber Duck GitHub posted is for using Claude Sonnet, not Opus. Who even uses Sonnet for agentic development today? This rubber duck review process is an interesting approach, but my own experience is that it’s enough to clear the context window and run again with the same model. Bias formed by training data and techniques is not the main problem with agentic programming, the limited context window is. And the more times you review a piece of code with different things in the context window the more things you will find to improve.
If you use GitHub Copilot CLI then you should definitely try it and see if it makes a difference for you. I don’t think it will make a difference for the more complex models, except that GPT-5.4 always seems to find issues with code written by Opus, and Opus always thinks the code written by GPT-5.4 is better.