W50 · 2025 — December 8, 2025
Tech Insights 2025 Week 50.

In fall 2001 I got my first Apple computer, the Titanium PowerBook G4, and I have since then owned and used many Mac computers and PCs throughout the years. Even if I have not always felt aligned with the design decisions Apple were making, at least you could feel that there was a strong design direction and Apple was always the company that boldly dared to go where few other companies had the capacity and courage to venture. What made Apple so interesting is however that no matter what direction they went - create a new type of phone without keyboard powered by a GPU, or a laptop so thin it was close to useless in the first edition, they always had the skills to somehow steer even the rockiest of launches in the right way over a few years.
The last couple of years I have not felt that. Apple UX has started to become sloppy, and what was once the leading company when it comes to UX design is now laughed upon in many areas. The new icons in the latest OS release Tahoe are “objectively bad”, and to make the new Liquid glass work in all legacy MacOS-apps, Apple did last-minute “skinning” to many of the built-in apps like Contacts, which now flickers every time you use the mouse pointer. It feels sloppy and amateurish, and this is something I have never experienced from Apple previously.
Last week two senior executives left Apple: John Giannandrea, Apple’s senior vice president for Machine Learning and AI Strategy, “retired”. And Alan Dye, Apple’s head of UI Design, left for a job at Meta (!). Tim Cook and most of the team at Apple has always looked down at the way Meta does its business, with Tim Cook in an interview in 2018 slamming Facebook, saying privacy ‘is a human right, it’s a civil liberty’. Meta is unpopular among Apple executives, and the fact that Alan Dye left for a job at Meta makes it clear that not only was he unfit for the job to steer Apple’s design interface forward, his moral compass was also unaligned with the rest of Apple. I am not saying it’s immoral to work at Meta, I am just saying that I cannot see any other executive at Apple even considering that as an option.
That said, as an Apple Mac user I am now looking forward to 2026 with great hope, and I am looking forward to see what Amar Subramanya can do with Siri. Amar was recently head of engineering for Google’s Gemini Assistant where he worked for 16 years. And taking over head of UI is Stephen Lemay, a long-term designer at Apple. Things can only improve from here.

Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2025 Week 50 on Spotify
THIS WEEK’S NEWS:
- Google Workspace Studio launches no-code AI agent builder
- Mistral Releases Open Models from 3 Billion to 675 Billion Parameters
- Amazon Announces Nova 2 Model Family and Nova Forge Training Service
- DeepSeek Releases V3.2 and V3.2-Speciale: Agent-Focused Reasoning Models
- Hugging Face Skills Brings Conversational LLM Fine Tuning To Cloud GPUs
- LangChain launches LangSmith Agent Builder for no-code AI agents
- Anthropic Launches AI-Powered Research Tool to Study Professional AI Usage
- Cursor Partners with OpenAI to Optimize GPT-5.1-Codex-Max Inside the Editor
- OpenAI Releases GPT-5.1-Codex-Max Prompting Guide
- Runway Releases Gen-4.5 Video Model, Tops Independent Leaderboard
- Kling Video 2.6 Launches Native Audio Generation
- Kling Releases Video O1, Image O1, and Avatar 2.0
- ByteDance Releases Seedream 4.5 Image Generation Model
- Nvidia Releases Open Reasoning Model for Autonomous VehiclesNews
Google Workspace Studio launches no-code AI agent builder
The News:
- Google Workspace Studio went live on December 3, 2025, bringing no-code AI agent creation to business, enterprise, and education customers across Gmail, Docs, Sheets, Drive, and Chat.
- Users describe tasks in plain language, like “label emails containing questions as ‘To respond’ and ping me in Chat”, and Gemini 3 builds the agent without requiring syntax knowledge or programming skills.
- Early testers executed over 20 million automated tasks during the past 30 days of alpha testing, covering workflows from simple reminders to complex processes like legal document triage and travel request management.
- The platform offers pre-built templates such as “auto-label priority email” and connects to third-party apps including Asana, Jira, Mailchimp, and Salesforce through pre-configured connectors.
- Kärcher, working with partner Zoi, built a chain of agents that evaluate new product features by reviewing concepts, checking technical feasibility, drafting user flows, and generating user stories, cutting their drafting time by 90 percent from hours to two minutes.
For example, you can prompt, “If an email contains a question for me, label the email as ‘To respond’ and ping me in Chat.”
My take: These AI agents are acting directly within your own Google cloud, and they can respond, react and act upon your content. With these agents you can automate daily tasks related to email, document processing, collaboration, and the proposal is very similar to the latest Agent Builder from Microsoft. I find these tools interesting, but I also see risks with them. The more complex agentic chains each coworker sets up, the bigger the risk something breaks along the way and makes them unproductive. I am a strong believer in AI agents for productivity increases, but I also believe that AI agents should be rolled out in a coordinated centralized way. Otherwise you risk having as many IT departments as you have employees in the company.
Mistral Releases Open Models from 3 Billion to 675 Billion Parameters
https://mistral.ai/news/mistral-3

The News:
- Mistral released Mistral 3, a family of open-weight models under Apache 2.0 license that includes three dense models (3B, 8B, 14B parameters) called Ministral 3 and a flagship sparse mixture-of-experts model, Mistral Large 3, with 41 billion active and 675 billion total parameters.
- All models support multimodal capabilities including text and image processing, with Mistral Large 3 incorporating a 2.5 billion parameter vision encoder and handling context windows up to 256,000 tokens.
- Mistral Large 3 was trained on 3,000 NVIDIA H200 GPUs and ranks number two on the LMArena leaderboard for open-source non-reasoning models, while ranking number six among all open-source models.
- The model runs on a single 8×A100 or 8×H100 node using vLLM and demonstrates strong performance on coding benchmarks, currently holding the top position for open-source coding models on LMArena.
- The Ministral 3 14B reasoning variant achieves 85 percent accuracy on AIME 2025 while generating fewer tokens than comparable models, and all models are available on Mistral AI Studio, Amazon Bedrock, Azure Foundry, Hugging Face, and other platforms.
My take: I think these figures highlight well the vast differences in investments and infrastructures between the EU and the US. I think Mistral has done an amazing job with Mistral Large 3, considering they only used 3,000 NVIDIA GPUs for it. Now compare this to a company like Anthropic that has access to 1 million TPUs, and you begin to understand the difference. At this rate of development there is no chance Europe will ever catch up to China and the US when it comes to AI development, so while the EU-developed models might be decent compared to some open source models, they are miles away from models like OPUS 4.5 or GPT 5.1 PRO. Mistral announce it as a “state-of-the-art open model” but also does not compare it to thinking models, only non-thinking.
Read more:
- Mistral 3 Blog post : r/LocalLLaMA
- Does Mistral 3 Perform Poorly on Tool Calling for anyone else? : r/LocalLLaMA
Amazon Announces Nova 2 Model Family and Nova Forge Training Service
https://www.aboutamazon.com/news/aws/aws-agentic-ai-amazon-bedrock-nova-models

The News:
- Amazon released Nova 2, consisting of four AI models with adjusted price-performance characteristics. The models include Nova 2 Lite, Nova 2 Pro, Nova 2 Sonic, and Nova 2 Omni.
- Nova 2 Lite serves everyday tasks such as customer service chatbots, document processing, and business automation. The model beats Claude Haiku 4.5 on 13 of 15 benchmarks and GPT-5 Mini on 11 of 17 benchmarks at approximately 50% of the latter’s cost.
- Nova 2 Pro handles complex tasks including multi-document analysis, video reasoning, and software migrations. The model matches or exceeds Claude Sonnet 4.5 on 10 of 16 evaluations and Gemini 2.5 Pro on 15 of 19 tests.
- Nova 2 Sonic provides speech-to-speech conversational AI with real-time latency below 600 milliseconds and 1.39 seconds time-to-first-audio. Nova 2 Omni processes text, images, video, and speech while generating both text and images within a single model.
- Both Lite and Pro models include extended thinking capabilities with three intensity levels, built-in code interpreter and web grounding tools, remote MCP tool support, and a one-million-token context window.
- Amazon also introduced Nova Forge, a training service that provides access to pre-trained, mid-trained, and post-trained model checkpoints. Organizations can inject proprietary data at any training stage to create custom model variants called Novellas.
My take: When Amazon launched their previous model Nova 1 a year ago, they wrote “Amazon Nova Pro outperformed GPT-4o in efficiency, operating 97% faster while being 65.26% more cost-effective”. If you have not heard of the Nova models before it’s perfectly fine, these models are specifically targeted at AI companies, creating agentic AI solutions. If you work at such a company however you most probably have heard of Nova before, maybe even used it, and Nova 2 really promises to shake things up a lot, especially Nova 2 Lite - better performance than Haiku 4.5 and GPT-5 Mini but 50% cheaper? That’s an amazing offer!
It’s still not easy to access these models from chat interfaces or coding clients, which means these models will continue to stay exclusive for API users. But Amazon is clearly showing strong performance here with their own models, and it’s very interesting to see how most of these top-tier US based companies really seem to drive at the same speed forward, almost improving their models at the same pace.
DeepSeek Releases V3.2 and V3.2-Speciale: Agent-Focused Reasoning Models
https://api-docs.deepseek.com/news/news251201

The News:
- DeepSeek released two reasoning models: V3.2 as the official successor to V3.2-Exp for daily use and V3.2-Speciale for complex reasoning tasks requiring extended computation.
- V3.2 achieves performance comparable to GPT-5 across reasoning benchmarks, while V3.2-Speciale matches Gemini-3.0-Pro and attains gold medal performance in IMO 2025, CMO 2025, IOI 2025, and ICPC World Finals 2025 without competition-specific training.
- V3.2 introduces tool use integration within thinking mode, synthesized from 1,800 environments and 85,000 complex instructions, and supports both thinking and non-thinking modes.
- The models use DeepSeek Sparse Attention (DSA), a fine-grained attention mechanism that reduces computational costs by approximately 50% in long-context scenarios while supporting 128,000-token contexts.
- V3.2 scored 96.0% on AIME 2025 (exceeding GPT-5 High’s 94.6%), 99.2% on HMMT 2025 (exceeding Gemini 3 Pro’s 97.5%), and achieved a 2701 Codeforces Grandmaster rating.
- V3.2-Speciale operates as API-only through a temporary endpoint until December 15, 2025, requires higher token usage than V3.2, and does not support tool calls during the evaluation period.
My take: “Speciale” is probably my favorite model name yet! And it truly is. Gold medal performance in IMO 2025, CMO 2025, IOI 2025, and ICPC World Finals 2025 without any competition-specific training! It looks like DeepSeek is going the same route as OpenAI here with two distinct categories of models: one for for math and programming, and one for general use. V3.2 is their general daily use model, and Speciale is their math and programming model model. Compared to V3.2, the Speciale model uses up to 5x more output tokens for reasoning. During the test period it does not support tool use, which temporarily lowers its Intelligence Index score. We are quickly approaching a breakpoint where these models will be good enough for most use cases at most companies, and it is at that point the DeepSeek models will start to shine for real with its amazing cost / performance ratio. We are not there yet, but maybe next year.
Hugging Face Skills Brings Conversational LLM Fine Tuning To Cloud GPUs
https://huggingface.co/blog/hf-skills-training

The News:
- Hugging Face released a Skills package that lets Claude Code, OpenAI Codex, and Gemini CLI submit LLM fine tuning jobs to Hugging Face cloud GPUs and publish models to the Hugging Face Hub.
- The hf-llm-trainer skill selects GPUs, configures authentication, generates training scripts, and applies training configurations from natural language instructions.
- Supported methods include supervised fine tuning, direct preference optimization, and reinforcement learning, on models from about 500 million up to 70 billion parameters.
- Example workflows include fine tuning a 0.6 billion parameter model on an instruction following dataset, with the skill choosing a t4-small GPU tier as the lowest cost option for that size.
- Training costs range from under 1 dollar for small test runs to about 15 to 40 dollars for production runs on models in the 3 to 7 billion parameter range, with usage gated behind a Hugging Face Pro or Team subscription.
- Current integrations cover Claude Code, Codex, and Gemini CLI, with announced support for editor agents such as Cursor, Windsurf, and Continue planned for later.
“We gave Claude the ability to fine-tune language models using a new tool called Hugging Face Skills. Not just write training scripts, but to actually submit jobs to cloud GPUs, monitor progress, and push finished models to the Hugging Face Hub.”
My take: This has the potential to revolutionize how we all fine tune our AI models in the near future! Let’s say you wanted to build a specialized customer support agent, a fine tuned model based on something like Llama. Traditionally you would have to prepare a specialized dataset with input-output pairs showing the model exactly how to respond to your specific task, write Python scripts using libraries like Transformers and TRL, select GPU hardware and allocate memory, and submit the training job through command line tools and monitor logs manually.
Now you instead say something like “Fine tune Llama 3.2 on my customer support dataset, use LoRA, keep cost under 20 dollars, publish the result privately”, and the assistant handles all the technical steps above automatically. It picks appropriate GPU hardware based on your model size and budget, generates the training code, submits the job, monitors progress, and answers questions like “How is training going?” by reading metrics. When you want to adjust something, you just tell the assistant in conversation rather than editing config files. If you know what you are doing and have fine-tuned models before, maybe this is not your thing at all. But if you are new to this, this will be like having an expert next to you guiding you in the process.
LangChain launches LangSmith Agent Builder for no-code AI agents
https://blog.langchain.com/langsmith-agent-builder-now-in-public-beta/

The News:
- LangChain released LangSmith Agent Builder, a no-code tool for creating production-oriented AI agents through chat, aimed at teams that want agent workflows without manual orchestration.
- Agents use multi-step reasoning, can call tools, and can delegate work to subagents that run separate tasks such as data gathering or drafting outputs.
- The public beta connects to external APIs and internal systems via MCP servers, with configuration handled at the workspace level in LangSmith.
- Teams can share, browse, copy, and modify agents across a workspace, and adjust behavior later by editing instructions in natural language instead of rebuilding flows.
- The beta supports multiple model providers, including OpenAI and Anthropic, and exposes an API so applications can invoke agents programmatically from existing systems.
- Early examples include agents for sales research, ticket creation from bug reports, email triage, and recruiting workflows, typically configured in a few minutes of guided chat setup.
“Today, we’re expanding who can build agents. Now, anyone can create production ready agents without writing code using LangSmith Agent Builder.”
My take: LangSmith Agent Builder targets many of the same scenarios that Microsoft Copilot Studio and other enterprise agent builders do, but keeps orchestration within the LangChain and LangGraph ecosystem. If you want to know more about this, the official YouTube launch video is 7 minutes short and to the point, and gives you a good overview. I think it looks really good, and will try to use it in my own agentic workshops going forward.
Read more:
Anthropic Launches AI-Powered Research Tool to Study Professional AI Usage
https://www.anthropic.com/research/anthropic-interviewer

The News:
- Anthropic released Anthropic Interviewer, an AI system that conducts automated qualitative research interviews at scale. The tool interviewed 1,250 professionals in an initial test and publicly released all anonymized transcripts for external researchers.
- The system operates in three stages. Planning stage creates interview rubrics with human researcher oversight. Interviewing stage conducts 10-15 minute real-time adaptive conversations on Claude.ai. Analysis stage identifies emergent themes and quantifies their prevalence across participants.
- The initial study surveyed 1,000 general workforce professionals, 125 creatives, and 125 scientists about AI integration in their work. 86% of general workforce participants reported AI saves them time and 65% said they were satisfied with AI’s role in their work.
- Key findings reveal 69% of professionals mentioned social stigma around AI use at work, with one fact-checker stating “A colleague recently said they hate AI and I just said nothing. I don’t tell anyone my process because I know how a lot of people feel about AI”. 79% of scientists cited trust and reliability concerns as the primary barrier to using AI for core research tasks.
- 97.6% of participants rated their satisfaction with the interview experience as 5 or higher on a 7-point scale, and 99.12% said they would recommend the interview format to others. The tool is now available to existing Claude.ai Free, Pro, and Max users for a public pilot study.
“Starting today, you might notice a pop-up in Claude.ai asking you to participate in interviews. By doing so, you can take part in the next phase of the research described in this post.”
My take: The findings from this anonymized study are quite interesting. 86% of participants said that they save time from using AI, but 69% of them hide their AI-use from their colleagues due to social stigma. AI has become this thing everyone uses but no-one talks about. This also makes it extremely difficult to measure AI ROI for chatbot rollouts at companies. If everyone is already secretly using AI, then the productivity improvements from rolling out paid tools to employees will be quite low - the improvements are already there since everyone is already using them. How is it at your workplace? Do people say they work with AI, or is everyone doing their thing without discussing if AI tools is involved in the process or not?
Cursor Partners with OpenAI to Optimize GPT-5.1-Codex-Max Inside the Editor
https://cursor.com/blog/codex-model-harness

The News:
- Cursor and OpenAI integrated the GPT-5.1-Codex-Max coding model into the Cursor editor and tuned it for in-editor automation. The work focuses on making the model better at reading, editing, and refactoring code directly inside projects.
- Codex is trained to work heavily with the command line. Cursor renamed and aligned its editor tools with common shell commands, such as ripgrep-style search, so the model can more easily use project-aware tools instead of running raw shell commands.
- Cursor found that keeping the model’s internal plan between steps is important for multi-step coding tasks. When that planning context was removed, Codex success on Cursor’s internal evaluations dropped by about 30 percent.
- The team asked Codex to show only short status updates while it works. Instead of long intermediate messages, it now uses brief one-line summaries so users can follow progress without a stream of chatter.
- Cursor added clear instructions for when Codex should run lint checks after making edits. The model now checks edited files with a linting tool and then fixes straightforward issues that appear.
- Cursor also told the model to default to taking action on code, not just suggesting changes. Unless a user specifically asks for a plan or explanation, Codex is prompted to make edits, run tools, and attempt to resolve issues directly.
My take: Initial response for GPT-5 CODEX MAX within Cursor was quite bad, and after these updates the response is mixed. For some use cases the results is really good, and for others not so. It’s clear that the model was built for use with OpenAI Codex, and I find it interesting that it needs so much adjustment to run well within the Cursor environment through API. The amount of work spent by both companies is quite significant, and it makes you think about GitHub Copilot and VSCode - who will do the same job there? Probably no-one, so if you have been getting poor results with of GPT-5.1-Codex-Max in GitHub Copilot now you know why.
OpenAI Releases GPT-5.1-Codex-Max Prompting Guide
https://cookbook.openai.com/examples/gpt-5/gpt-5-1-codex-max_prompting_guide

The News:
- OpenAI published a prompting guide for developers building IDE integrations and coding agents using GPT-5.1-Codex-Max through the API.
- API implementers should set “medium” reasoning effort as the default and remove all prompts requesting upfront plans, preambles, or status updates, as these cause premature task termination.
- System prompts must explicitly instruct the model to act autonomously as a “senior engineer” who gathers context, plans, implements, tests, and refines without waiting for additional prompts between steps.
- The guide recommends using OpenAI’s apply_patch tool implementation, available through the Responses API, since the model was specifically trained on this diff format rather than standard unified diffs.
- Tool call parallelization through multi_tool_use.parallel produces significant performance gains by batching file reads, searches, and list operations together instead of sequential execution.
My take: As these models get more complex, making them perform well in different environments also become more difficult. This guide exemplifies this in a great way, it goes through roles, system prompts, tools uses and much more. Hopefully this will also help the GitHub team improve performance in GitHub Copilot with this model.
The collaboration between OpenAI and Cursor team just shows how much work is required to make these models perform well, which becomes even more difficult the more capable the models become. This is just another dependency the model creators have over the tool vendors, and I can just guess that the team behind Microsofts own AI Model MAI-1 does not take many days for Christmas leave this year in order for Microsoft to catch up with the rest of the AI model companies.
Runway Releases Gen-4.5 Video Model, Tops Independent Leaderboard
https://runwayml.com/research/introducing-runway-gen-4.5
The News:
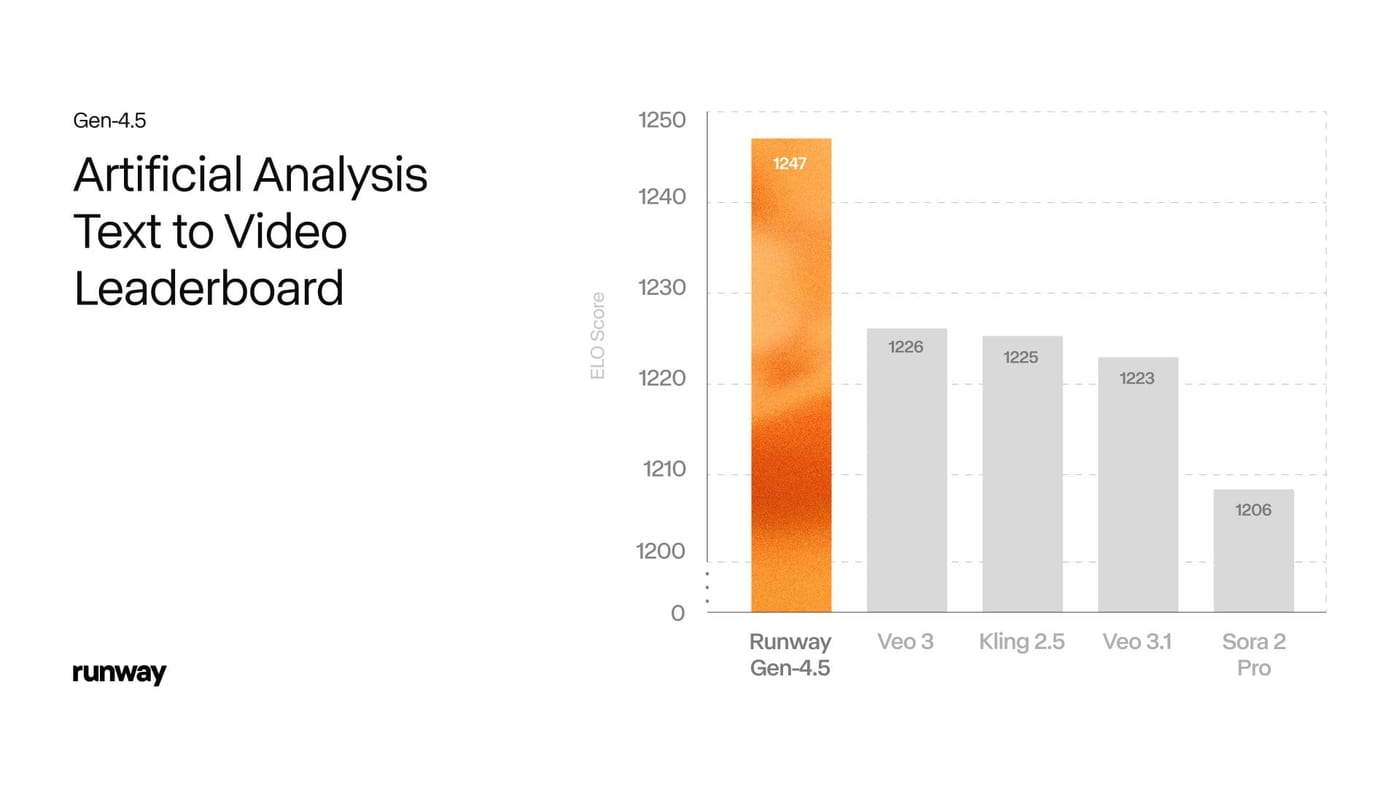
- Runway launched Gen-4.5, a text-to-video generation model previously tested anonymously as “Whisper Thunder” and “David.” The model scored 1,247 Elo points on the Artificial Analysis Text-to-Video leaderboard, ranking first among 23 models based on 103,163 blind user votes.
- Gen-4.5 handles complex, sequenced instructions in a single prompt, including detailed camera choreography, scene compositions, precise event timing, and atmospheric changes. Objects exhibit realistic weight and momentum, with surfaces responding accurately to interactions.
- The model outputs HD video up to 20 seconds with extension options at 24 FPS. Creators can selectively ignore physics constraints for artistic effects. Upcoming integrations include Image-to-Video, Keyframes, and Video-to-Video modes.
- Gen-4.5 offers three style presets: photorealistic, cinematic with depth of field and film grain, and “slice of life”, which degrades quality intentionally to resemble iPhone footage.
- The model does not generate audio. Pricing starts at $15 per month for 625 credits on the Standard plan.
My take: If you want the best AI-generated video today, this is it. With one drawback. It does not produce audio. A year ago I wrote about the news that Runway has partnered with Lionsgate to produce AI video for future blockbuster movies, and this news is the result of that collaboration. Top movie producers don’t want the AI to generate sound, they want all focus on the visuals. But for everyone else I think we already have gotten too used to AI video with audio in models like Google Veo 3.1 that it’s difficult to go back. The only way to get an AI character say something with Runway 4.5 is to generate video and then use their Lip Sync tool to move the mouth of the person to match spoken dialogue. As you can expect it does not work well with facial or body expressions, and if this is something you want then Runway 4.5 is not the tool for you. This is something you use for B-roll, something you mix into your other video material, and for that I think it’s excellent.
Read more:
Kling Video 2.6 Launches Native Audio Generation
https://app.klingai.com/global/quickstart/klingai-video-26-audio-user-guide

The News:
- Kling AI released Video 2.6, introducing simultaneous audio and video generation in one workflow. The model produces voiceovers, sound effects, and ambient sounds alongside 1080p visuals, removing the need for separate audio post-production.
- The model supports multiple audio types including human speech, dialogue, singing, rap, environmental sounds like breaking glass and ocean waves, and layered background ambience. Audio generation features deep semantic alignment between visual motion and corresponding sounds.
- “Audio quality meets professional creator standards” with clean sound output, multi-layered mixing, and detail preservation that mirrors real-world audio post-production.
- The platform supports customizable duration and aspect ratio settings with professional-grade output suitable for various distribution platforms.
- The unified workflow replaces the traditional five-step process of generating silent video, recording voiceovers, sourcing sound effects, mixing audio, and post-production editing.
My take: Ok I take it back, after seeing these examples I am fine with not being able to generate audio with AI video. “HELLO I AM AN AI AVATAR AND THE WAY I SPEAK DOES NOT SOUND NATURAL”. This is how your characters will appear if you ask them to say anything with Kling Video 2.6. So even if it (unlike Runway 4.5) does support audio, the actual audio it produces is nearly useless. As for video quality - if you search YouTube or the Internet you will come across hundreds or thousands of videos saying Kling + Z-image or Seedream is the future of cinema. This model has strong appeal to the home-tinkerers and DYI community, and I believe much of it is due to it’s lack of censorship. Just take that into consideration when you read all the user raves about it.
Kling Releases Video O1, Image O1, and Avatar 2.0
https://app.klingai.com/global/release-notes/vaxrndo66h

The News:
- Kling AI released three models last week: Video O1 (unified multimodal video model), Image O1 (image generation and editing), and Avatar 2.0 (digital human video creation).
- Video O1 unifies text-to-video, image-to-video, video editing, style transformation, and shot extension into a single model. The model processes text, multiple reference images, and video clips simultaneously within one prompt to generate or modify video outputs up to 10 seconds.
- The model uses a Chain of Thought reasoning approach that analyzes prompts before generating video content, which improves motion accuracy and reduces the need for multiple regeneration attempts. Video O1 supports multi-element editing including swapping, adding, deleting, or restyling objects within existing footage.
- Image O1 accepts up to 10 reference images per prompt to maintain consistent character appearance and style across multiple outputs while preserving lighting and texture properties.
- Avatar 2.0 generates videos up to 5 minutes from a single photo and audio input at 48fps and 1080p resolution. The model includes a multimodal director module that extracts speech and emotional data from audio to control facial expressions, body gestures, and camera angles. Platform data showed a 300% increase in generated videos on the first day of Avatar 2.0 launch.
My take: These models are pretty good. Add text, images or video clips and tell the models what image you want to generate (Image O1) or what video clip you want it to generate (Video O1) and you will be able to control in great detail the resulting video clip. Both these models generate output that I definitely can see uses for, with the exception of Avatar 2.0 which is just as bad as the Kling Video 2.6 above for creating human-like avatars.
Read more:
- Kling Image O1 model is now released! New Engine, Full Commands, Total Control.
- Kling VIDEO O1 Model Officially Launched! Input anything. Understand everything. Generate any vision.
- Kling AI Avatar 2.0 is available! Max Expressions, Real Characters!
ByteDance Releases Seedream 4.5 Image Generation Model
https://seed.bytedance.com/en/seedream4_5

The News:
- ByteDance released Seedream 4.5 on December 3, 2025, an upgraded image generation model that maintains subject consistency across multiple images, renders dense text with improved clarity, and produces 4K resolution outputs.
- The model uses a cross-image consistency module that preserves character identity, clothing details, scene lighting, and artistic style when generating multiple related images in the same batch.
- Multi-image editing identifies main subjects across reference images and preserves facial characteristics, proportional accuracy, and lighting behavior without identity drift.
- Typography capabilities support bilingual text rendering in professional layouts including e-commerce displays, poster design, and wedding invitations with complex formatting.
- Performance benchmarks on MagicBench show improvements across prompt adherence, alignment, and aesthetic dimensions compared to Seedream 4.0.
My take: Right now this model is ranked #7 on LMArena, which is ok but not great. But people are raving about it in social media as the next big thing. Like Z-image, this model is mostly uncensored, which means that depending on the types of content people want to create this model might be their best and only choice. It does not have anything close to the text consistency of Nano Banana Pro, and most of the images it generates have that soft artificial look. But if you experience that the content you want to generated cannot be done with Nano Banana Pro you might want to check it out.
Read more:
Nvidia Releases Open Reasoning Model for Autonomous VehiclesNews
https://blogs.nvidia.com/blog/neurips-open-source-digital-physical-ai/

The News:
- Nvidia released DRIVE Alpamayo-R1 (AR1), an open vision-language-action model (VLA) for autonomous vehicle research that integrates chain-of-thought reasoning with trajectory planning. The model addresses safety challenges in long-tail driving scenarios where supervision is sparse and causal understanding is limited.
- AR1 processes visual sensor data, translates observations into natural language descriptions, and generates trajectory decisions with explanations for each action. In testing on difficult long-tail scenarios, AR1 increased planning accuracy by 12% compared to baseline models with trajectory prediction only.
- Closed-loop simulation tests showed AR1 reduced off-road accident rates by 35% and dangerous close encounters with vehicles or pedestrians by 25%. The model maintains low end-to-end latency despite its reasoning capabilities.
- Built on Nvidia Cosmos Reason, AR1 uses reinforcement learning during post-training to improve reasoning quality compared to the pretrained version. The model was trained on 20,000 hours of real driving videos and includes a Chain-of-Causation dataset where each action is annotated with structured explanations.
- AR1 is available through GitHub and Hugging Face for non-commercial use, including benchmarking and experimental development. Nvidia released accompanying tools including the AlpaSim evaluation framework and the Cosmos Cookbook for training and fine-tuning.
My take: This is the first industry-scale open reasoning VLA model specifically designed for autonomous driving research, and NVIDIA hopes that this type of reasoning model will give autonomous vehicles the “common sense” to better approach driving decisions like humans do. Examples include pedestrian-heavy intersections, upcoming lane closures or a double-parked vehicle in a bike lane. In these situations AR1 breaks down each scenario and reasoning into steps, considers all possible trajectories, then uses contextual data to choose the best route.
By tapping into the chain-of-thought reasoning enabled by AR1, an AV driving in a pedestrian-heavy area next to a bike lane could take in data from its path, incorporate reasoning traces, and use that information to plan its future trajectory, such as moving away from the bike lane or stopping for potential jaywalkers. I think the approach is interesting, but after having spent way too long sitting and waiting for GPT-5.1 thinking mode to answer even the simplest of questions I’m not really sure how applicable it will be in real world scenarios.
Read more: