Tech Insights 2026 Week 16
April 13, 2026
Last week I visited HumanX in San Fransisco, one of the largest AI conferences in 2026 with over 9,000 attendees, 500+ speakers and 400+ journalists. The conference is centered around deep-dive interviews with industry leaders and I visited 36 sessions over four days. It took the entire weekend to summarize all my notes.
From the conference the message was clear: the models are good enough, your organization isn’t. The change must be driven from CEO-level, and you must start with the people, not technology. May Habib, CEO at Writer, said this about AI transformational change:
“If they don’t have the authority to actually change workflows end-to-end, you’re not really going to get that large-scale transformation.”
This is exactly how we have been working at TokenTek over the past year, and it has proven very successful. We always work directly with the top management team, identify a few “easy win use cases”, then start rethinking the work processes before we start building out agentic solutions. You cannot just bolt AI onto your current processes and expect big productivity gains, you need to reimagine the way you work.
“Companies that try and do a thousand flowers blooming very often end up with a thousand dead flowers.” Francis deSouza, COO, Google Cloud
If you live in Göteborg we still have a few seats left for our seminar “Trends from HumanX” on April 17. Our first seminars on April 16 and April 22 was filled within hours (500 seats), so you need to be quick to grab a seat. In this seminar I will summarize lessons learnt from industry leaders at companies like AWS, Google, OpenAI, Anthropic, Databricks, NVIDIA, Visa, Mercedes-Benz, Capital One and Salesforce. Don’t miss this if you are working with AI transformation, it will not be available online.
Sign up here (it’s free): https://event.paloma.se/Event/vinnexplorehumanx-46848/
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2026 Week 16 on Spotify
THIS WEEK’S NEWS:
- AI Tool Predicts Heart Failure Five Years Before Onset
- Anthropic Crosses $30B ARR, Surpasses OpenAI in Revenue
- Anthropic Locks In 3.5GW of Compute With Google and Broadcom
- Anthropic Introduces the Advisor Tool for Claude Agents
- Claude for Word Brings Native AI Editing to Microsoft Word
- Claude Managed Agents: Anthropic’s Hosted Infrastructure for Agent Deployment
- Claude Code Adds Monitor Tool for Event-Driven Agent Workflows
- HeyGen Releases Avatar V, Their Latest Talking-Head Video Generation Model
- Perplexity Expands Plaid Integration to Cover Full Personal Finance Picture
- Lawsuit Alleges Perplexity’s Incognito Mode Shares User Chats With Google and Meta
- Meta Introduces Muse Spark and Meta Superintelligence Labs (MSL)
- Google Adds Notebooks to Gemini with NotebookLM Sync
- Neural Computers: A New Machine Where the Model Becomes the Computer
- Z.ai Launches GLM-5.1 for Long-Horizon Coding Tasks
AI Tool Predicts Heart Failure Five Years Before Onset

The News:
- Oxford researchers published a new AI tool in the Journal of the American College of Cardiology that predicts heart failure risk at least five years in advance using routine cardiac CT scans, without requiring human input.
- The tool detects textural changes in fat surrounding the heart that signal inflammation in the heart muscle below. These changes are not visible to the human eye through any standard imaging method.
- Trained and validated on over 70,000 patients across nine NHS Trusts, followed for a decade, the algorithm achieved 86% accuracy in predicting heart failure within five years.
- Patients in the highest risk group were 20 times more likely to develop heart failure than those in the lowest risk group, with roughly a 1-in-4 chance of developing the condition within five years.
- The team is now pursuing NHS regulatory approval and expects to extend the tool to general chest CT scans, including lung scans, within months, broadening the pool of patients who could be screened opportunistically.
My take: Until now heart failure was typically caught only after serious structural damage had already occurred. This tool changes that by reading a biological signal (pericardial fat texture) that wasn’t previously clinically usable. This is a true game changer for cardiac care, and I would love to see it launched in the EU too.
Read more:
Anthropic Crosses $30B ARR, Surpasses OpenAI in Revenue
https://www.the-ai-corner.com/p/anthropic-30b-arr-passed-openai-revenue-2026

The News:
- Anthropic’s annualized revenue run rate surpassed $30 billion in April 2026, exceeding OpenAI’s reported $25 billion ARR and marking a 3.3x increase from $9 billion at the end of 2025.
- Growth accelerated sharply in early 2026: $14B in February, $19B in March, $30B in April, a jump of $11 billion in a single month.
- Over 1,000 enterprise customers now spend more than $1 million annually with Anthropic, a figure that doubled in under two months from 500 customers at the time of the February Series G announcement.
- Claude is the only frontier AI model available across all three major cloud platforms: AWS Bedrock, Google Cloud Vertex AI, and Microsoft Azure Foundry.
- OpenAI projects $121 billion in annual compute spending and $14 billion in losses for 2026. Anthropic projects positive free cash flow by 2027, against OpenAI’s breakeven target pushed to 2030.
My take: If you look at the chart, you can clearly see that something happened in early 2026 that caused revenue to spike almost linearly upwards. If you have been using Claude Code yourself you might have experienced the model becoming “dumb” and started to miss things and stress to solutions.
In February 2026 Anthropic shipped updates to Claude Code that fundamentally changed how reasoning works. Claude Code switched to something called “adaptive thinking”, where the model dynamically decides how long to reason rather than using a fixed budget. The default effort level was also dropped to “medium”, framed as the “sweet spot on the intelligence-latency curve”. On April 2, Stella Laurenzo, Senior Director of AI at AMD, filed GitHub issue #42796 with data from 6,852 session JSONL files and 234,760 tool calls:

In parallel the thinking depth of Claude Code also dropped significantly::
- Late January (baseline): 100%
- Late February: −67%
- March 1–5: −75%
It’s clear that the free lunch is over, and that Anthropic chose to make the overall experience worse for everyone in order to meet the growing demand. The hardware deal with Google and Broadcom (see below) should help alleviate the issue somewhat, but that infrastructure is not due until 2027. OpenAI is roughly in the same situation with over 1 million new Codex users in just four weeks, it will be interesting to see if they can handle the pressure without making the models dumber. OpenAI did however significantly reduce the limits for the Plus accounts recently, making Codex almost unusable unless you pay at least $100 per month. Anthropic closed the issue posted by Stella on April 8 without further comments.
Read more:
- [MODEL] Claude Code is unusable for complex engineering tasks with the Feb updates · Issue #42796 · anthropics/claude-code · GitHub
- Tibo on X: “Three million people are now using Codex weekly - up from two million a little under a month ago. Incredible to see the growth.” / X
Anthropic Locks In 3.5GW of Compute With Google and Broadcom
https://www.anthropic.com/news/google-broadcom-partnership-compute

The News:
- Anthropic signed a new agreement with Google and Broadcom for approximately 3.5 gigawatts of next-generation TPU compute capacity, set to come online starting in 2027.
- The deal extends Broadcom’s supply agreement with Google through 2031, under which Broadcom develops and manufactures future TPU iterations for Google’s AI cluster architecture, including optical interconnects supporting up to 9,216 accelerators per cluster.
- The vast majority of the new capacity will be sited in the United States, as part of Anthropic’s November 2025 commitment to invest $50 billion in American computing infrastructure.
- Alongside the announcement, Anthropic disclosed its run-rate revenue has surpassed $30 billion, up from approximately $9 billion at end of 2025 and $14 billion in February 2026.
- The number of enterprise customers spending over $1 million annually on an annualized basis exceeded 1,000 as of early April, doubling from 500 in fewer than two months.
- CFO Krishna Rao described it as “our most significant compute commitment to date.”
My take: In October 2025 Anthropic and Google signed an agreement worth “tens of billions of dollars” for bringing one gigawatt of TPU capacity online in 2026, and this new 3.5 GW agreement is a substantial step up in scale from that. In just a few weeks we will all get the new models built on the latest Blackwell chip series, and next year it will be Vera rubin. Right now it looks like everything is on-track for a significant boost in model performance this year, and an even bigger boost next year.
Anthropic Introduces the Advisor Tool for Claude Agents
https://claude.com/blog/the-advisor-strategy
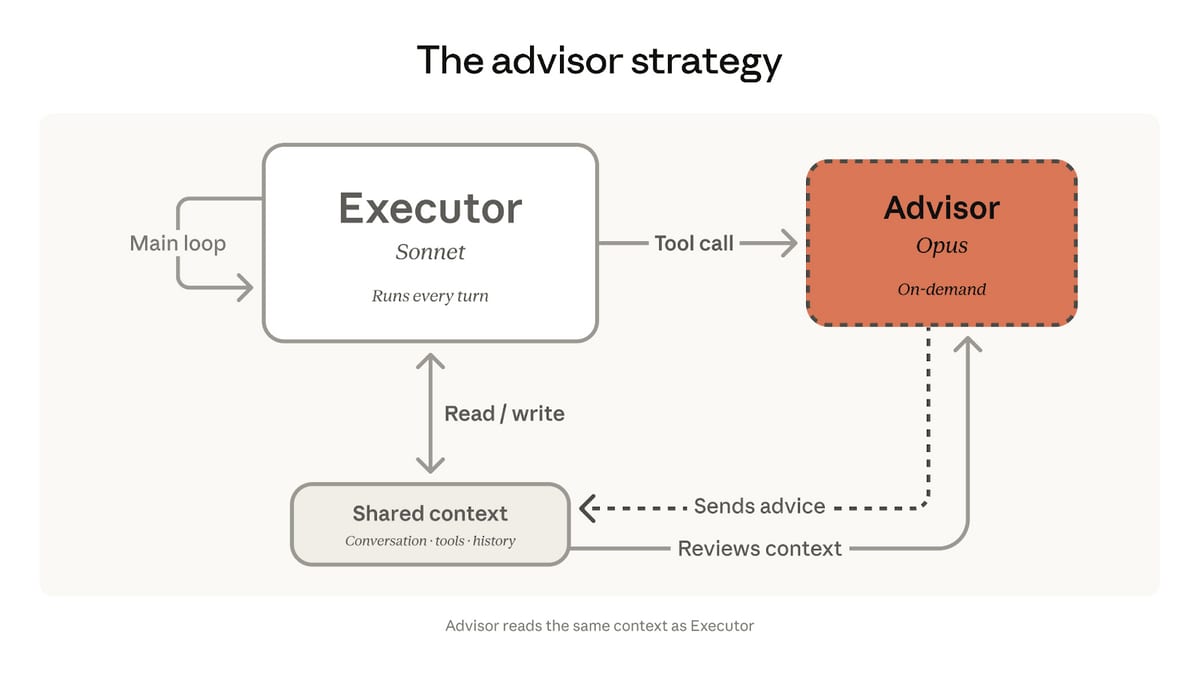
The News:
- Anthropic released the advisor tool on April 9 as a beta feature in the Claude Messages API, letting developers pair Claude Opus 4.6 as an on-demand advisor with Sonnet or Haiku as the task executor in a single API call.
- The executor model (Sonnet or Haiku) runs the full task end-to-end, calling tools and iterating toward a solution. When it hits a decision it cannot resolve, it invokes Opus, which reads the shared context and returns a short plan (typically 400-700 tokens) before the executor resumes. Opus never calls tools or produces user-facing output.
- In internal evaluations, Sonnet 4.6 with an Opus 4.6 advisor scored 2.7 percentage points higher on SWE-bench Multilingual than Sonnet alone, while reducing cost per agentic task by 11.9%.
- Haiku 4.5 with an Opus advisor scored 41.2% on BrowseComp, more than double Haiku’s solo score of 19.7%, and costs 85% less per task than Sonnet alone, though it trails Sonnet solo by 29% in score.
“In our evaluations, Sonnet with Opus as an advisor showed a 2.7 percentage point increase on SWE-bench Multilingual over Sonnet alone, while reducing cost per agentic task by 11.9%.”
My take: The “Advisor tool” is an interesting pattern as it inverts the standard “orchestrator architecture” where a large model decomposes work and routes subtasks to smaller models, to using a smaller model that drives execution and only escalates, removing the need for a worker pool or custom orchestration logic. User feedback is cautiously positive, with comments like “How does a smaller model, famous for confidently making stuff up, know when it’s facing a “hard decision”. You just have to try it yourself for your own tasks to see how well it works for you.
Read more:
Claude for Word Brings Native AI Editing to Microsoft Word
https://claude.com/claude-for-word
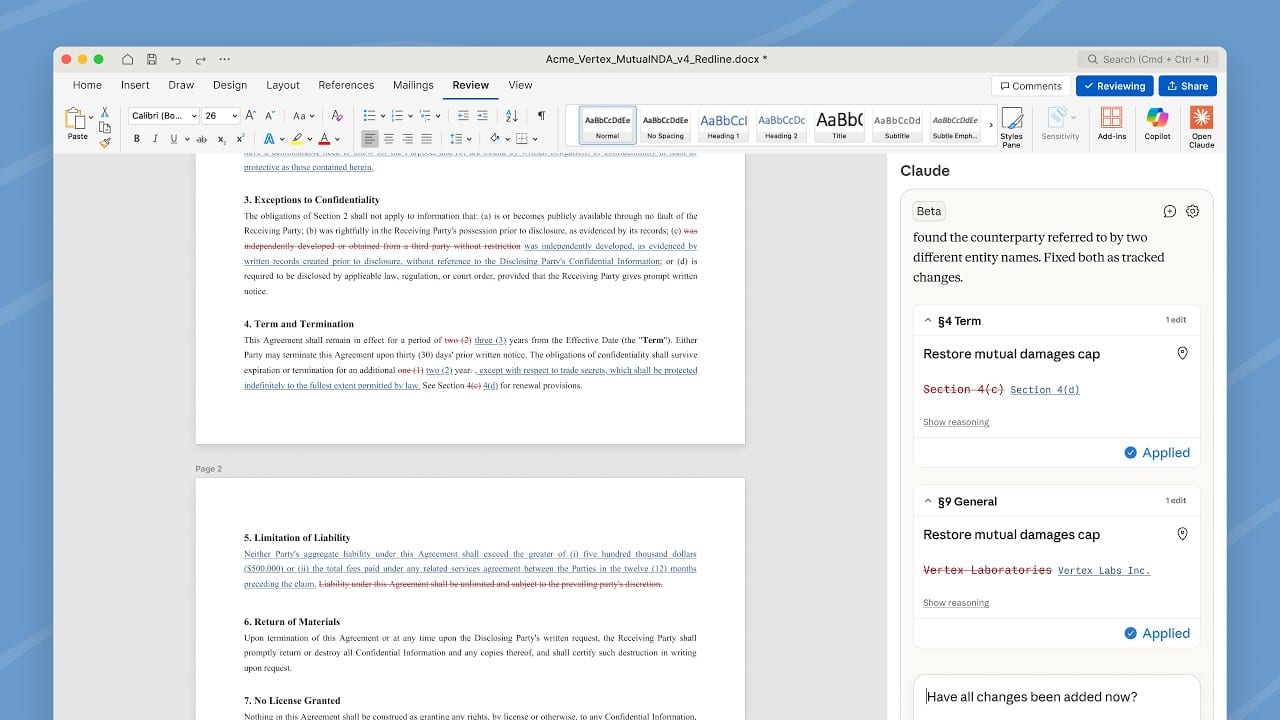
The News:
- Anthropic has released Claude for Word, a beta add-in for Microsoft Word, available to Claude Team and Enterprise plan subscribers. It runs inside the document rather than in a separate chat window, making edits visible as native Word tracked changes that users can accept or reject in Word’s review pane.
- Claude reads comment threads left by authors or collaborators, edits the anchored text in each comment as a tracked change, and replies in the thread with a description of what it changed.
- The add-in inherits the document’s existing heading styles, numbering schemes, bullet formatting, and defined terms, and limits edits to the targeted section without disturbing the rest of the document.
- Teams can save workflows as reusable “Skills,” so a contract review or status memo workflow can be run by any team member and produce a consistent result.
- Claude for Word shares context with the Claude for Excel and Claude for PowerPoint add-ins within a single conversation, allowing one session to span multiple Office applications.
- Supported file formats are .docx and .docm; older .doc or .rtf files must first be saved as .docx before the add-in will load.
My take: Claude now works natively inside Word, PowerPoint and Excel, with full access to the entire document. So why should you use Claude over Copilot? A few reasons. First, Claude has skills. This is extremely powerful, and very simple to use. Copilot support something called “custom agents” which is more or less the same thing, but is more complex and not as easy to share between team members.
Also, Claude can share the same session between Word, Excel and PowerPoint, where Copilot is siloed within each app. This runs over a WebSocket bridge that connects the three add-ins in real time. This means that you can:
- Pull numbers from an Excel model directly into a Word memo
- Summarize a Word document into PowerPoint slides
- All without copy-pasting between apps or re-explaining context in each
Both these features (skills and WebSocket bridge) arguably makes Claude the stronger choice for Microsoft document-focused workflows compared to Copilot.
Read more:
Claude Managed Agents: Anthropic’s Hosted Infrastructure for Agent Deployment
https://claude.com/blog/claude-managed-agents
The News:
- Anthropic launched Claude Managed Agents on April 8, a cloud-hosted suite of APIs for building and deploying AI agents without managing your own infrastructure.
- The platform handles sandboxed code execution, checkpointing, credential management, scoped permissions, and end-to-end tracing as built-in services.
- Sessions run autonomously for hours and persist across disconnections, supporting both single-task and multi-agent pipelines.
- In internal testing on structured file generation tasks, Managed Agents improved task success by up to 10 percentage points over a standard prompting loop, with the largest gains on the hardest tasks.
- Pricing is standard Claude Platform token rates plus $0.08 per session-hour for active runtime.
- Notion, Rakuten, Asana, Sentry, and Atlassian are listed as early adopters. Rakuten deployed specialist agents across engineering, sales, marketing, and finance within one week each.
My take: Four weeks ago OpenAI launched their updated “Responses API” which is more or less the same thing as Claude Managed Agents. Compared to Claude Managed Agents however, the Responses API environment is more open in its execution: a full shell versus Anthropic’s higher-level API abstractions. Claude Managed Agents emphasizes checkpointing, multi-agent pipelines, and credential management as first-class features, while OpenAI’s approach is closer to giving the model a raw terminal with safety guardrails bolted on. Both products address the same core pain point: teams spending engineering time building custom sandboxes, session state, and orchestration that is now handled by the provider.
Claude Code Adds Monitor Tool for Event-Driven Agent Workflows
https://x.com/alistaiir/status/2042345049980362819

The News:
- Anthropic shipped the Monitor tool in Claude Code on April 9, 2026, letting the agent create background scripts that watch external events and wake the session only when those events occur.
- Before Monitor, background observation required /loop or scheduled tasks, which fire a full API call on a fixed interval regardless of whether anything happened. A /loop checking a test suite every 2 minutes over a 10-minute run costs 5 full API calls; Monitor replaces all 4 idle calls with zero.
- Claude Code PM Noah Zweben described it as “a big token saver and great way to move away from polling in the agent loop”.
- Each monitor takes a shell command whose stdout becomes the event stream. Lines arriving within 200ms batch into a single notification. Stderr goes to a log file but does not trigger events.
- Monitors can be persistent for the full session or bounded with a timeout_ms up to 1 hour. Typical use cases include tailing dev server logs for errors, surfacing failing tests as they fail, watching CI/CD pipelines, and polling GitHub PRs for new review comments.
My take: Monitor sits along two existing Claude Code automation layers: Hooks (which fire on Claude’s own tool events) and Scheduled Tasks (which fire on a clock). Monitor fills the gap for reacting to real-time external output, making the three layers complementary. Here are a few use cases:
- Test-driven feedback loops. Monitor watches a running test suite and surfaces failures the moment they occur, so Claude fixes and re-runs without you triggering a new prompt cycle.
- PR review watcher. A shell script periodically checks GitHub for new review comments; Claude wakes only when a new comment is detected, drafts a response or fix, then goes quiet again.
- Deploy observability. Monitor tails server logs during a deployment and activates Claude the moment a 500 error spike appears, turning passive supervision into instant triage.
Claude Code is quickly growing from just an AI coding tool into an always-on development co-pilot, which can be used to supervise, triage, and act across your entire stack silently in the background until something actually needs attention.
Read more:
HeyGen Releases Avatar V, Their Latest Talking-Head Video Generation Model
https://www.heygen.com/research/avatar-v-model

The News:
- HeyGen just published the architecture and training methodology behind Avatar V, its latest avatar video generation model, which creates high-resolution talking-head videos of arbitrary length from a single reference video and a driving audio signal.
- The model uses a mechanism called Sparse Reference Attention, which conditions generation on the full token sequence of a reference video at every transformer layer, scaling nearly linearly with reference length and removing the need for identity-specific fine-tuning at inference time.
- Avatar V models both static identity features (dental structure, skin texture, facial geometry) and dynamic behavioral patterns (talking rhythm, micro-expressions, head gestures), so generated output is behaviorally consistent with the reference speaker, not just visually similar.
- Voice cloning runs on a separate LLM-based Audio Engine that requires as little as 10 seconds of reference audio and supports multilingual output with emotion control; the voice output feeds directly into a motion encoder, linking voice and facial movement.
- On a 70-case cross-scene benchmark, Avatar V achieves an LSE-C (lip sync confidence) score of 8.97 and Face Similarity of 0.840, outperforming Veo 3.1 (0.714 Face Similarity); in a six-dimension human evaluation using a 5-point Likert scale, Avatar V ranked first on all six dimensions and was preferred in pairwise comparisons at a rate of 68.9% to 85.7%.
My take: Avatar V generates the best looking talking heads I have seen so far, but you can still very easily see that the AI-output is AI-generated, typically due to the slower movements of moving eyes or raising eyebrows. But maybe that is a good thing? The visual quality and audio sync is very good, and maybe we all need it to be simple to detect when things are AI generated?
If you want to see just how far we have come with AI-generated talking heads you really should visit their web page.
Perplexity Expands Plaid Integration to Cover Full Personal Finance Picture
https://www.perplexity.ai/hub/blog/plaid-integration-provides-full-view-of-personal-finances

The News:
- Perplexity extended its existing Plaid integration beyond brokerage accounts to include bank accounts, credit cards, mortgages, auto loans, and student loans, giving US and Canada desktop users a single AI-driven view of their complete finances.
- Plaid connects to 12,000+ financial institutions, including Chase, Fidelity, Schwab, Vanguard, and Robinhood; the connection is read-only and user data does not pass through Perplexity’s servers.
- Users can ask freeform questions rather than relying on fixed dashboards; supported queries include building a net worth tracker across all accounts, creating a monthly budget by category, or generating a debt payoff plan using current balances and interest rates.
- Financial data in responses is sourced from FactSet, S&P Global, SEC filings, Coinbase, and Nasdaq; users can hover over any figure to see its source.
- Basic portfolio access is free for signed-in users; Computer-powered analysis, such as building interactive dashboards, Excel models, or full financial apps, requires a Pro or Max subscription.
My take: Would you feel comfortable letting an agentic system get full access to your personal banking account? While I definitely see the benefits here, right now I think that safety concerns will make this a hard-sell to most users in the US or Canada. Especially when Plaid, the service Perplexity is partnering with here, has a ranking of 1.2 / 5 on Trustpilot, with comments like “Trash system, invisible transaction limits, bot support that’s completely redundant and unhelpful. No support. No error codes”. This isn’t just user frustration, Plaid paid a $58 million class action settlement in 2022 over how it handled and communicated its data practices to users. This is not a company I would trust with any data.
Read more:
- Is Plaid safe? What it is and how it protects your financial data
- Plaid to Pay $58 Million to Settle Data Privacy Class Action
Lawsuit Alleges Perplexity’s Incognito Mode Shares User Chats With Google and Meta
https://arstechnica.com/tech-policy/2026/04/perplexitys-incognito-mode-is-a-sham-lawsuit-says/

The News:
- A class-action lawsuit filed April 1, 2026 in the US District Court for the Northern District of California (Doe v. Perplexity AI Inc., 3:26-cv-02803) alleges that Perplexity AI secretly forwards user conversations to Meta and Google, including sessions conducted in Perplexity’s “Incognito” mode.
- The 135-page complaint claims that third-party tracking scripts are downloaded onto users’ devices upon login, transmitting conversation data to Meta and Google infrastructure in real time, before Perplexity itself has processed the query.
- Non-subscribers are allegedly more exposed: their initial queries are transmitted via a URL structure that gives Meta and Google access to the full conversation thread.
- Paid subscribers using Incognito mode are also affected, with the complaint stating that email addresses and other identifiers are shared alongside conversation content.
- The plaintiff, identified as John Doe from Utah, states he used Perplexity to search topics related to taxes, family finances, and personal investments while believing those interactions were private.
- Perplexity spokesperson Jesse Dwyer responded: “We have not been served any lawsuit that matches this description so we are unable to verify its existence or claims,” without denying the underlying tracking practices.
Using developer tools, the lawsuit found that opening prompts are always shared, as are any follow-up questions the search engine asks that a user clicks on. Privacy concerns are seemingly worse for non-subscribed users, the complaint alleged. Their initial prompts are shared with “a URL through which the entire conversation may be accessed by third parties like Meta and Google.”
Disturbingly, the lawsuit alleged, chats are also shared with personally identifiable information (PII), even when users who want to stay anonymous opt to use Perplexity’s “Incognito Mode.” That mode, the lawsuit charged, is a “sham.”
My take: Perplexity is clearly challenged by the web search built-into ChatGPT, Claude and Copilot, but for some use cases it’s still the best for news aggregation. However with news like this it really makes you think twice about using Perplexity as a service. The lawsuit also names Google and Meta as co-defendants, alleging all three companies benefited from the undisclosed data sharing to increase ad targeting revenue. This news, together with the Plaid collaboration above, should make everyone think twice before signing up for the service.
Meta Introduces Muse Spark and Meta Superintelligence Labs (MSL)
https://ai.meta.com/blog/introducing-muse-spark-msl/

The News:
- Meta released Muse Spark on April 7, 2026, the first model from its newly formed Meta Superintelligence Labs (MSL). It is now available on the Meta AI app and meta.ai, with a rollout planned for WhatsApp, Instagram, Facebook, and Messenger in the coming weeks.
- The model is the first in a new “Muse” series, built from a ground-up reconstruction of Meta’s AI stack over nine months. Meta says the underlying architecture reaches Llama 4 Maverick capability levels using over 10x less compute during pretraining.
- Muse Spark ships with two modes: Instant (standard responses) and Thinking (extended reasoning), with a third mode called “Contemplating” planned. In Contemplating mode, multiple AI agents work in parallel on the same problem to reduce latency during extended reasoning.
- The model supports multimodal inputs including visual chain of thought and tool-use. A notable demonstration showed it extracting individual image assets from a UI screenshot rather than treating it as a flat image.
- Muse Spark scores first among all benchmarked models on HealthBench Hard (42.8) and CharXiv Reasoning Figure Understanding (86.4), and leads Gemini Deep Think and GPT-5.4 Pro on Humanity’s Last Exam (50.2%) and FrontierScience Research (38.3%).
- Access requires a Meta account (Facebook or Instagram login). An API is available in private preview for select partners.
My take: This new model from Meta ranks high amongst the top frontier models like Gemini, GPT and Opus, but it’s still behind in performance. While better than the old “Meta Llama” models, it still doesn’t have what it takes to move into a leading position. The new Muse Spark model is also closed source, which goes against Meta’s position like “Open Source AI is the Path Forward” Open Source AI is the Path Forward, which is particularly striking given that Yann LeCun, the architect of Meta’s open-source identity, left the company just months before this launch. I think going closed source is the right choice, it means they can put all the focus on the model and not on the packaging of it. They can always open it up in the future if they want to, like xAi.
Google Adds Notebooks to Gemini with NotebookLM Sync
https://blog.google/innovation-and-ai/products/gemini-app/notebooks-gemini-notebooklm/
The News:
- Google released a “Notebooks” feature in the Gemini app on April 8, 2026, giving paid subscribers a persistent project workspace that connects Gemini chats with NotebookLM sources.
- Users can move past chats into a notebook, attach files such as PDFs and Google Docs, and write custom instructions that stay active across sessions.
- Sources added in Gemini automatically appear in NotebookLM, and vice versa, giving access to NotebookLM-specific outputs like Video Overviews and Infographics from within a Gemini workflow.
- The number of sources a notebook can hold varies by subscription tier: Ultra, Pro, and Plus plans each have different limits.
- The rollout starts on the web for Google AI Ultra, Pro, and Plus subscribers, with mobile, free-tier access, and more European countries coming in the following weeks.
My take: Gemini was one of the last AI tools to get a “notebook” feature, arriving roughly 1–2 years after ChatGPT Projects, and while it seems to work just fine for single users, for multiple users the collaboration is asymmetric: team members can access shared notebooks via NotebookLM but not through the Gemini app itself. This will probably be addressed in the near future. Overall a very welcome feature for Gemini users.
Neural Computers: A New Machine Where the Model Becomes the Computer
https://metauto.ai/neuralcomputer/

The News:
- Researchers from Meta AI and KAUST published a paper on April 7, proposing Neural Computers (NCs), a machine form that folds computation, memory, and I/O into a single learned runtime state rather than running explicit programs through a traditional software stack.
- Unlike agents (which act over external execution environments) or world models (which predict environment dynamics), an NC aims to make the model itself the running computer, with capabilities installed directly into its runtime rather than assembled from external tools and workflows at execution time.
- The paper defines a target state called the Completely Neural Computer (CNC), requiring four conditions: Turing completeness, universal programmability (inputs install reusable routines, not just trigger one-off behavior), behavior consistency (changes only via explicit reprogramming), and machine-native semantics (the neural substrate forms its own programming interface).
- Two prototype implementations were built: NCCLIGen, a video model trained on roughly 1,100 hours of terminal footage that learns to render and step through CLI environments, and NCGUIWorld, trained on approximately 1,510 hours of Ubuntu desktop interaction data including 110 hours of goal-directed trajectories driven by Claude.
- In CLI tests, basic commands such as pwd, date, and whoami produced accurate input-output sequences. Two-digit arithmetic remained unstable, which the authors attribute partly to insufficient training data and partly to fundamental limits of current diffusion transformer architectures for symbolic reasoning.
My take: The CNC vision (Completely Neural Computer) is genuinely novel. Instead of bolting AI onto a traditional computer, the model itself becomes the computer, with skills and routines living inside it permanently. Right now however the prototypes can’t even do two-digit arithmetic reliably. The deeper problem is that neural models are probabilistic by nature, meaning they don’t produce the same output twice, while real computers need to be deterministic and predictable. Right now it’s an interesting research direction, I will follow it up in the coming years to see where it ends up.
Read more:
Z.ai Launches GLM-5.1 for Long-Horizon Coding Tasks

The News:
- Z.ai released GLM-5.1 on April 7, an open-weight model built for long-horizon agentic tasks, with a focus on sustained autonomous coding and engineering execution.
- The model runs continuously for up to 8 hours on a single task, completing a full loop from planning and execution to testing, bug fixing, and final delivery, described as the first Chinese model to reach this level of sustained execution.
- On the SWE-Bench Pro benchmark, GLM-5.1 scores 58.4, outperforming GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro.
- On KernelBench Level 3, GLM-5.1 achieves a 3.6x geometric mean speedup on real ML workloads across 50 problems, compared to 1.49x for torch.compile in max-autotune mode.
- In a documented test, the model built a complete Linux desktop system autonomously over 8 hours, executing over 1,200 steps, with preliminary results delivered within 20 minutes.
- The model is available via the GLM Coding Plan starting at $10/month and integrates with Claude Code, Cursor, Cline, and 20+ other AI coding tools. It has a 203K token context window, priced at $1.4 per million input tokens and $4.4 per million output tokens.
My take: This is a big model, in full BF16 precision it’s 1.65 TB in size, but with Unsloth’s Dynamic 2-bit quantization (UDIQ2M) the size goes down to 220 GB, an 86% reduction. As is typical with Z.ai they never say which version of the model was used for the benchmarks, but I am guessing it’s the full BF16 model. So don’t expect Opus 4.6 performance when running this locally on your stack of A100 cards. Early community reports flag a sharp performance drop past 100K tokens, despite the advertised 203K context window, worth keeping in mind for those long-horizon agentic runs.
Read more: