W19 · 2026 — May 4, 2026
Tech Insights 2026 Week 19.

GPT-5.5 is different. GPT-5.5 is the first model trained at OpenAI’s flagship Stargate site in Abilene, Texas, one of the supercomputing facilities funded by the $500 billion partnership between OpenAI, SoftBank, and Oracle. The site runs on Oracle Cloud Infrastructure, is powered by NVIDIA’s GB200 Blackwell systems, and is purpose-built to train frontier AI at a scale that simply wasn’t possible before. And it shows. GPT-5.5 keeps impressing me every single day.
GPT-5.5 is aware of how the content it produces looks and is structured, and it can reason, iterate, and adjust the content in meticulous detail before presenting it to you. A fantastic example of this is MineBench, where you send in the same prompt to different models to see how well they produce a 3D volumetric output. One example is “A cozy cottage” which generates the following structures:
 GPT-5.4 to the left, GPT-5.5 to the right.
GPT-5.4 to the left, GPT-5.5 to the right.
If you have a minute, go to this page and look at the differences between GPT-5.4 and GPT-5.5. GPT-5.5 is on a whole different level here. There’s just no comparison, the amount of spatial understanding and sense of detail in this model is beyond most humans.
Another use case that exploded in popularity the past week was sending in a photo to ChatGPT with this prompt: “Redraw the attached image in the most clumsy, scribbly, and utterly pathetic way possible. Use a white background, and make it look like it was drawn in MS Paint with a mouse. It should be vaguely similar but also not really, kind of matching but also off in a confusing, awkward way, with that low-quality pixel-by-pixel feel that really emphasizes how ridiculously bad it is. Actually, you know what, whatever, just draw it however you want.” Here’s one example of me speaking at a seminar:

What makes this prompt so good is that gpt-image-2 (which is based on GPT-5.5) “draws” the lines as if they had been drawn with a computer mouse. It understands not only what you ask of it, but also how the image would have been drawn if it was done by hand. I have not experienced anything like this from any AI model before. This is the first time an AI model has shown actual skill, not just drawing something based on its pre-training.
It’s the same with programming and documents. GPT-5.5 produces content with a quality that is better than almost any human. Where I previously had to iterate AI-generated source code 3-10 times with previous models, now I do just 1-2 on average.
So, what does all this mean for you and your company?
It means that we finally have an AI model that can do real tasks, do them by itself, and the end results will match or exceed those of the best humans. But the model cannot do this work by itself. Some tasks consist of dozens or hundreds of sub-tasks, so you need some kind of harness to use it, and this is why all AI companies are now rushing so quickly to provide all these workflow and agentic wrappers.
Last week OpenAI launched a new “/goal” feature in their productivity app Codex, which makes the model work continuously until it has reached its goal by splitting work into multiple subtasks and passing progress between them (here is how you enable it). This makes it possible for it to run for hours and even days solving tasks. Perplexity introduced Workflows to let models perform sequential tasks within their “Computer” environment, and Cursor released their SDK for autonomous programming agents. With the right instructions and proper harness, you can get GPT-5.5 to work for hours and actually solve tasks that would have taken humans 10x that time to finish.
But it will cost you. With agents running for hours, the cost of running just a single task can easily jump to $1,000 and beyond. This is why you need to approach these new models and their agentic harnesses from a top-down perspective. If one co-worker saves 20 hours every month by spending $500 on an AI agent, is it worth it? Does it scale? Is your organization built to leverage the cost by having the employee do other productive things? I believe very few organizations can afford opening up unlimited agentic use inside the company, and since tokens are shared in groups, who decides which initiative is the one worth investing in?
This is why I believe every single company should start building centrally managed agentic systems. Do a quick audit, identify tasks and processes that can be fully automated by GPT-5.5 and an efficient harness, calculate the ROI (how much time savings you get, development and running costs), then just go and build it. The first agentic system will be the most expensive, but over time you will be able to reuse components and build these systems yourself, and this is where the real bottom-line results will start to appear.
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2026 Week 19 on Spotify
Notable model releases last week:
- Xiaomi MiMo-V2.5-Pro. Open-source 1T parameter reasoning model.
- NVIDIA Nemotron 3 Nano Omni. Open-source 30B parameter model for vision, audio and language in agentic systems.
THIS WEEK’S NEWS:
- Stripe Launches Link Wallet for AI Agents
- Mayo Clinic AI Detects Pancreatic Cancer Up to 3 Years Before Diagnosis
- xAI Releases Grok 4.3 with Sandboxed Computer Access
- Mistral Launches Remote Coding Agents and Mistral Medium 3.5
- OpenAI Reports Stargate Surpasses 10GW Compute Goal Ahead of 2029 Target
- Cursor Releases TypeScript SDK for Programmatic Coding Agents
- Meta Ads AI Connectors Enter Open Beta
- Spotify Launches “Verified by Spotify” Badge to Mark Human Artists
- Google Brings Gemini to Android Auto
Stripe Launches Link Wallet for AI Agents
The News:
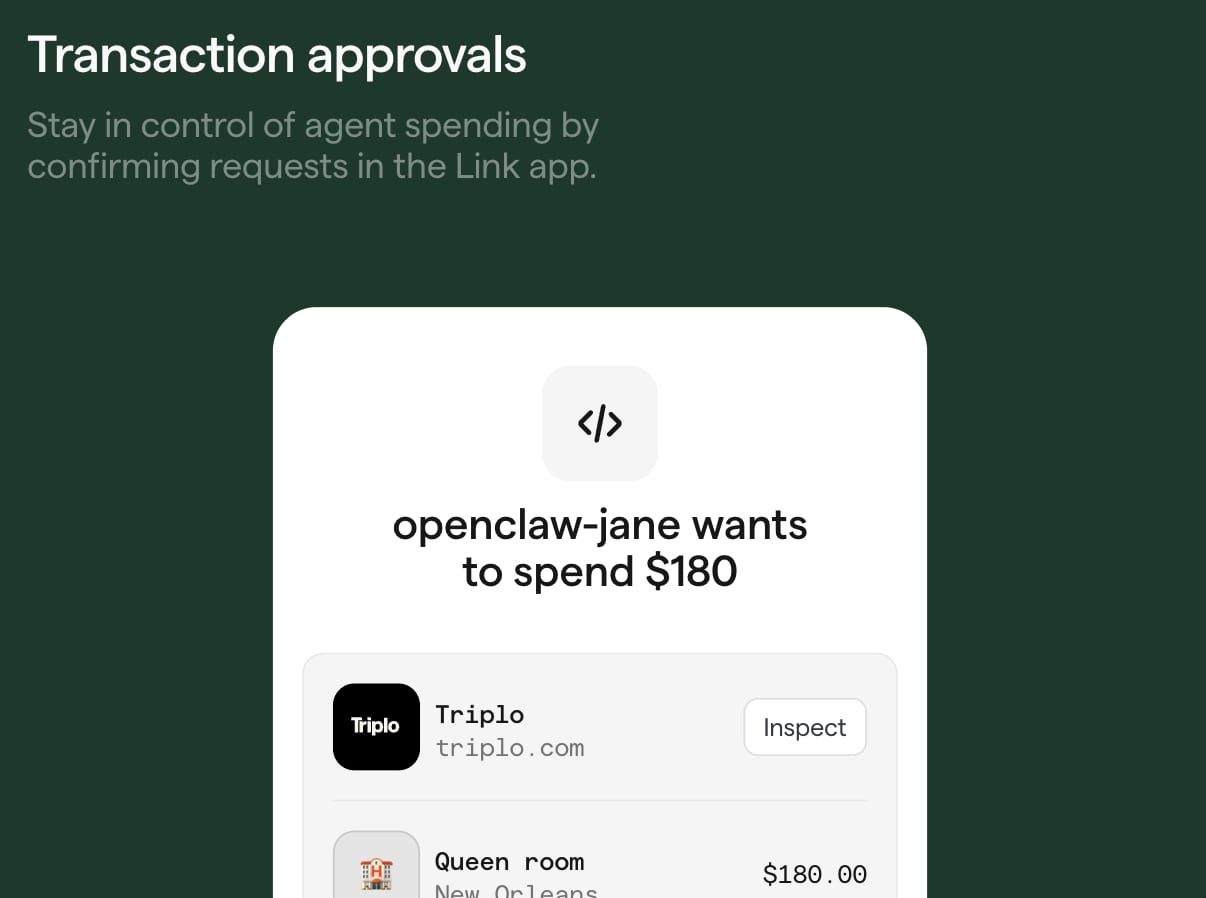
- Stripe has added agentic payment capabilities to Link, its existing digital wallet with over 250 million users globally, letting AI agents make purchases on behalf of users without ever accessing raw payment credentials.
- Agents connect to Link via a standard OAuth flow, then submit a spend request with transaction context; the user reviews and approves each request through the Link web interface or iOS/Android app before any payment is made.
- Two credential types are available: a one-time-use virtual card scoped by amount, currency, and merchant, and a Shared Payment Token (SPT) suited for merchants integrated with machine payment protocols.
- Real-time authorization via webhook has a 2-second default response window, with spend controls configurable at the card or cardholder level and updateable at any time.
- Stripe plans to expand controls to allow users to set spending limits and grant agents permission to act without per-transaction approval; support for agentic tokens and stablecoins is listed as coming soon.
- Developers can use Link’s wallet infrastructure directly instead of building a custom payment flow, with Stripe noting the launch is built on its new “Issuing for agents” product announced at Sessions 2026.
My take: If you give an agentic harness like OpenClaw the rights to purchase things for you, Link’s Consumer Terms of Service are very clear about who is responsible if something goes wrong:
“If you grant authority to someone to use your Link Account (by giving them your login information) and they exceed the authority you gave them. You are responsible for transactions made in this situation unless you have previously notified Stripe that you no longer authorise transactions by that individual.” Link Consumer Terms of Service
Simple summary: you are fully responsible if something goes wrong. Since language models are stochastic and can easily be influenced by external input, it means web sites might be able to convince your shopping agent to buy something you did not intentionally plan for. And while Stripe Link supports two-factor approval for all purchases, how do you know the seller is trustworthy?
When I purchase from new web sites I always check their details on Trustpilot. The average rating at Trustpilot is easy to game, and you often find web sites that have only 1 or 5 star ratings, where the top reviews are from employees or made up. The only way to detect fraudulent web sites is to actually read the reviews to identify scam content from real reviews. I do not believe AI agents can do this analysis yet, which means I would be very cautious about letting an AI agent buy from any web site, even with the two-factor approval system used in Stripe Link.
Read more:
Mayo Clinic AI Detects Pancreatic Cancer Up to 3 Years Before Diagnosis
The News:
- Mayo Clinic published validation results for REDMOD (Radiomics-based Early Detection Model), an AI that reads tissue texture and structural patterns on routine abdominal CT scans to flag pancreatic cancer before any visible tumor appears, with findings published in the journal Gut.
- REDMOD analyzed nearly 2,000 CT scans originally read as normal, identifying 73% of prediagnostic cases at a median of 475 days before clinical diagnosis, compared to 39% for specialist radiologists reviewing the same scans.
- At more than two years before diagnosis, REDMOD detected 68% of cases versus 23% for radiologists. The model showed 90-92% prediction concordance when patients were scanned months apart, and 81.3% specificity across a multi-institutional dataset.
- The model runs automatically on scans patients already receive for other reasons, targeting high-risk groups such as those with new-onset diabetes. Mayo Clinic is now running the prospective AI-PACED clinical study to evaluate integration into care for high-risk patients.
My take: The 5-year survival rate for pancreatic cancer is below 15%, which means the earlier it can be detected the higher the chances of survival. News like this really shows the impact generative AI can have in the medical domain, however I still have seen very few solutions being rolled out in actual production due to regulations. Let’s hope this changes soon.
xAI Releases Grok 4.3 with Sandboxed Computer Access
https://grok.com/release-notes/apr-17-2026

The News:
- xAI launched Grok 4.3 on April 17, rolling it out to SuperGrok and Premium+ subscribers as an improved pre-trained model replacing Grok 4.20.
- Grok 4.3 matches the scale of Grok 4.20 with an improved architecture and a December 2025 knowledge cutoff, two months later than its predecessor.
- The model ships with access to a sandboxed computer environment where it can write and execute code, install packages, and produce real downloadable files including presentations, documents, and spreadsheets.
- xAI states this is the beginning of a broader access roadmap, with planned additions including full internet access, user files, email, calendar, and third-party service connections.
- The model is recommended by xAI for all chat, coding, and general tasks, with separate dedicated models for audio, image, and video generation.
My take: Grok 4 is still in beta, and many features users have come to expect like MCP integration and persistent memory are still missing. X is really doing everything they can to catch up with OpenAI and Claude here, like adding agentic workflows within a sandboxed environment. xAI is also working on “giving Grok full access to the Internet, your files, your email, your calendar, and any service you can connect to” meaning they are like most other companies evolving from a chat provider to an agentic interconnected super-tool provider.
Mistral Launches Remote Coding Agents and Mistral Medium 3.5
https://mistral.ai/news/vibe-remote-agents-mistral-medium-3-5

The News:
- Mistral released Mistral Medium 3.5 on April 28, a 128B dense model with a 256k context window, now the default model in both Mistral Vibe and Le Chat.
- Vibe coding agents move to the cloud, running asynchronously in parallel sessions. Agents integrate with GitHub, Linear, Jira, Sentry, and Slack, and can be launched from the Vibe CLI or directly from Le Chat without switching context.
- Mistral Medium 3.5 scores 77.6% on SWE-Bench Verified, placing it ahead of Devstral 2 and models like Qwen3.5 397B A17B in that benchmark. It also scores 91.4 on the agentic benchmark τ³-Telecom.
- The model is available via API at $1.50 per million input tokens and $7.50 per million output tokens, and as open weights on Hugging Face under a modified MIT license. At Q4 quantization, it runs in approximately 70GB of VRAM.
- A new Work mode in Le Chat (Preview) enables multi-step agentic tasks. Connectors to email, calendar, Jira, Slack, and document sources are enabled by default, and sessions persist across many turns until task completion.
My take: I am genuinely curious if there is anyone actually using Mistral models for production source code development. Based on virtually every feedback thread you can find on [Reddit](What are we supposed to do with Mistral Medium 3.5? : r/MistralAI) or Hacker News the output of Mistral models is simply not good. It’s like you see the all these releases from Mistral, where they describe various theoretical scenarios on how their models can be used, but there is literally no-one using them since they perform worse than the models from all the other AI companies.
Read more:
OpenAI Reports Stargate Surpasses 10GW Compute Goal Ahead of 2029 Target
https://openai.com/index/building-the-compute-infrastructure-for-the-intelligence-age/

The News:
- OpenAI announced on April 29 that its Stargate initiative has already surpassed the original 10GW U.S. compute capacity goal set for 2029, adding more than 3GW in the last 90 days alone.
- Stargate is described as an umbrella strategy for OpenAI’s compute infrastructure, bringing together partners across cloud, chips, energy, construction, finance, and public sector to scale AI data center capacity.
- GPT-5.5, OpenAI’s latest model, was trained at the flagship Stargate site in Abilene, Texas, which runs on Oracle Cloud Infrastructure and NVIDIA GB200 systems.
- The Abilene site uses closed-loop cooling; after the initial fill, annual water consumption for the entire facility at full buildout is expected to be comparable to a medium-sized office building, or about four average households.
- OpenAI launched a community engagement program, starting with a donation to the Port Washington-Saukville Education Foundation in Wisconsin, alongside Vantage Data Centers and Oracle, to fund local education and workforce readiness.
My take: While this article reads like a domestic U.S. infrastructure success story, the broader picture is a bit more complicated. According to Financial Times OpenAI has “in practice abandoned the joint venture” model of directly owning infrastructure alongside SoftBank and Oracle, and now prefers long-term leasing arrangements. OpenAI also pulled out of Stargate expansion deals in the UK and Norway in April 2026, citing high energy costs and regulatory conditions in the UK. Still, this is a massive achievement, and it’s one of the main reasons OpenAI has so few scaling issues despite skyrocketing demand.
Read more:
Cursor Releases TypeScript SDK for Programmatic Coding Agents
https://cursor.com/blog/typescript-sdk

The News:
- Cursor released a public beta of @cursor/sdk on April 28, 2026, giving developers API access to the same agent runtime that powers the Cursor desktop app, CLI, and web app.
- The SDK has three execution modes: local (runs in a Node process against files on disk), Cursor-hosted cloud (dedicated sandboxed VM with repo cloned in), and self-hosted cloud (your own VMs, code never leaves your network, model inference still routes through Cursor).
- Cloud agents persist across disconnects; on completion they can push branches, open pull requests, or attach screenshots as artifacts.
- The full Cursor toolchain is available: codebase indexing, semantic search, MCP servers, subagents, skills from .cursor/skills/, and hooks via .cursor/hooks.json.
- Billing is token-based consumption rather than per-seat; Cursor published a cookbook with four starter projects (quickstart, prototyping tool, kanban board, terminal CLI).
My take: This is an interesting proposition from Cursor. This SDK sits closer to OpenAI Agents SDK and Agno than Devin or GitHub Copilot Workspace. The agentic interface in the Cursor 3 IDE which I reported about earlier was the first step, now with this release they are shifting from an “editor developers use” to “infrastructure running coding automations”. The main reason? Token consumption. Billing from CI pipelines and embedded products scale differently than per-seat editor licenses. It also lets Cursor capture revenue from organizations that would never buy editor seats at all.
Read more:
Meta Ads AI Connectors Enter Open Beta
https://www.facebook.com/business/news/meta-ads-ai-connectors
The News:
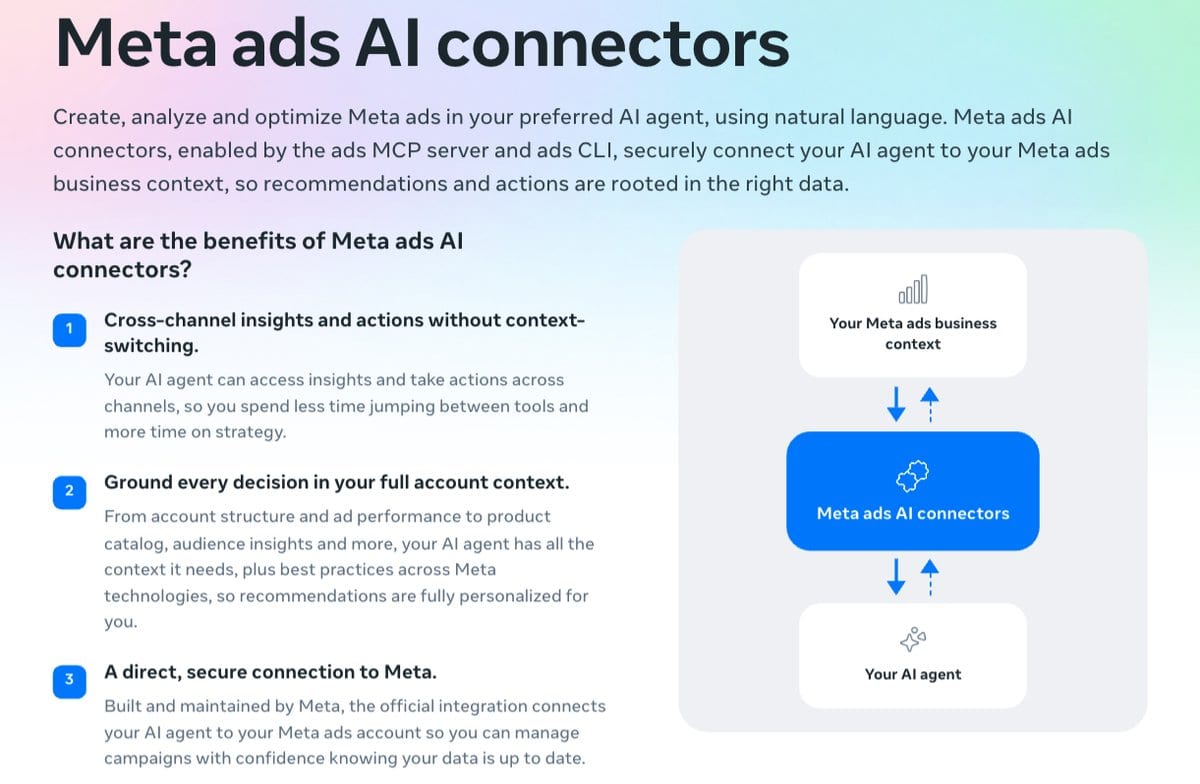
- Meta launched Meta Ads AI Connectors in open beta on April 29, giving advertisers and agencies the ability to create, manage, and analyze Meta ad campaigns directly inside external AI tools such as Claude, ChatGPT, and Cursor, without requiring developer credentials, API setup, or coding.
- The connectors consist of two components: a Model Context Protocol (MCP) server and a command-line interface (CLI), both authenticated through Meta’s own account system rather than third-party developer keys.
- Supported capabilities include campaign creation and editing via natural language, performance reporting, product catalog management, and signal diagnostics for ad tracking health.
- The MCP server bridges AI agents to Meta’s Marketing API in real time, meaning data returned reflects live campaign figures rather than cached exports or generic model responses.
- The tool targets cross-channel workflows, where an advertiser might combine Meta campaign data with insights from other platforms inside a single AI session.
“We ran 75 benchmark runs comparing CLI and MCP for AI agent tasks. CLI won on every efficiency metric: 10 to 32x cheaper, 100% reliable versus MCP’s 72%.” scalekit
My take: Connectors that enable AI agents to operate autonomously are being launched on a wide scale now, and these AI connectors from Meta allows you to automate most things related to ads. Bringing out both MCP and CLI support is something you will see many companies doing during 2026. MCP is still the platform to use when connecting desktop apps like Copilot or ChatGPT to external services, where CLI is the preferred choice from Codex or Claude Code. Many reports like this one consistently proves that CLI is way more efficient than MCP, so if you have the option go ahead and use CLI instead of MCP. I wrote about the Google Workspace CLI tool back in week 11, and the more CLI tools we get the more we will be able to reliably automate.
Read more:
Spotify Launches “Verified by Spotify” Badge to Mark Human Artists
https://newsroom.spotify.com/2026-04-30/verified-by-spotify-badge-artist-details/
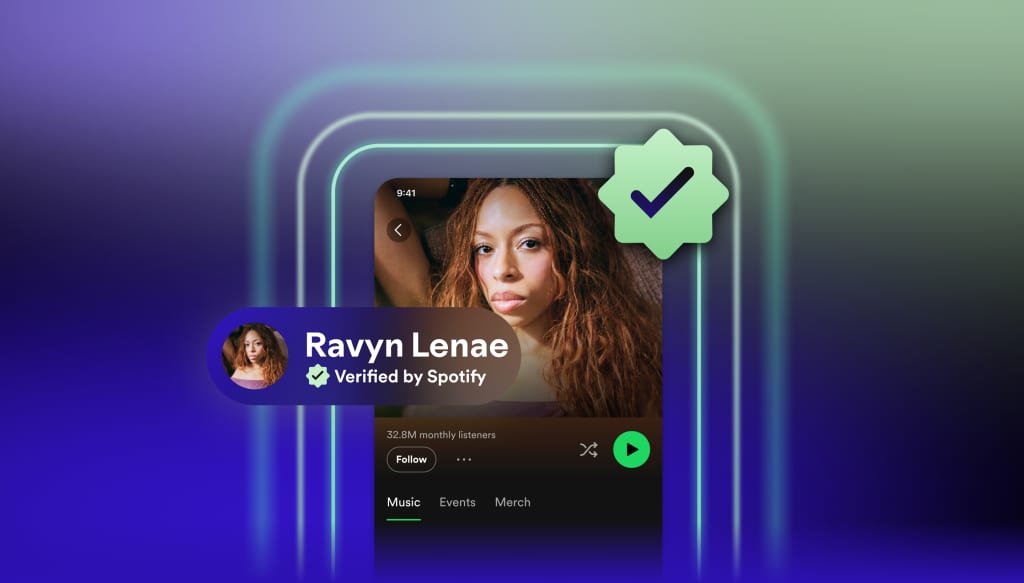
The News:
- Spotify introduced “Verified by Spotify” on April 30, a green checkmark badge displayed on artist profiles confirmed to represent human artists, not AI-generated personas.
- Profiles that “appear to primarily represent AI-generated or AI-persona artists are not eligible for verification” at launch.
- To qualify, artists must meet three criteria: consistent listener engagement over a sustained period (not just one-time spikes), compliance with Spotify’s platform policies, and an identifiable off-platform presence such as concert dates, merchandise, or linked social accounts.
- Spotify says more than 99% of artists that listeners actively search for will be verified at launch, spanning hundreds of thousands of independent creators.
- Alongside the badge, Spotify is rolling out a beta “Artist Details” section on all artist profiles, regardless of verification status, showing career milestones, release patterns, and live performance history. The company compares this to nutritional labeling for food.
- The badge uses a light green checkmark and “Verified by Spotify” text; it will appear on artist profile pages and next to artist names in search results, rolling out over the coming weeks.
My take: The Spotify competitor Deezer recently announced that AI-generated music now accounts for nearly 44% of all daily uploads. Spotify hasn’t announced how much uploaded content is AI-generated but it’s probably a lot. Still, I wonder what effect this badge really has. If you have a shared playlist with 50 songs, do you care if 50% of them are AI-generated if they sound as good or better than the other tracks? Maybe today, but in a year I’m willing to bet that most people don’t.
Read more:
Google Brings Gemini to Android Auto
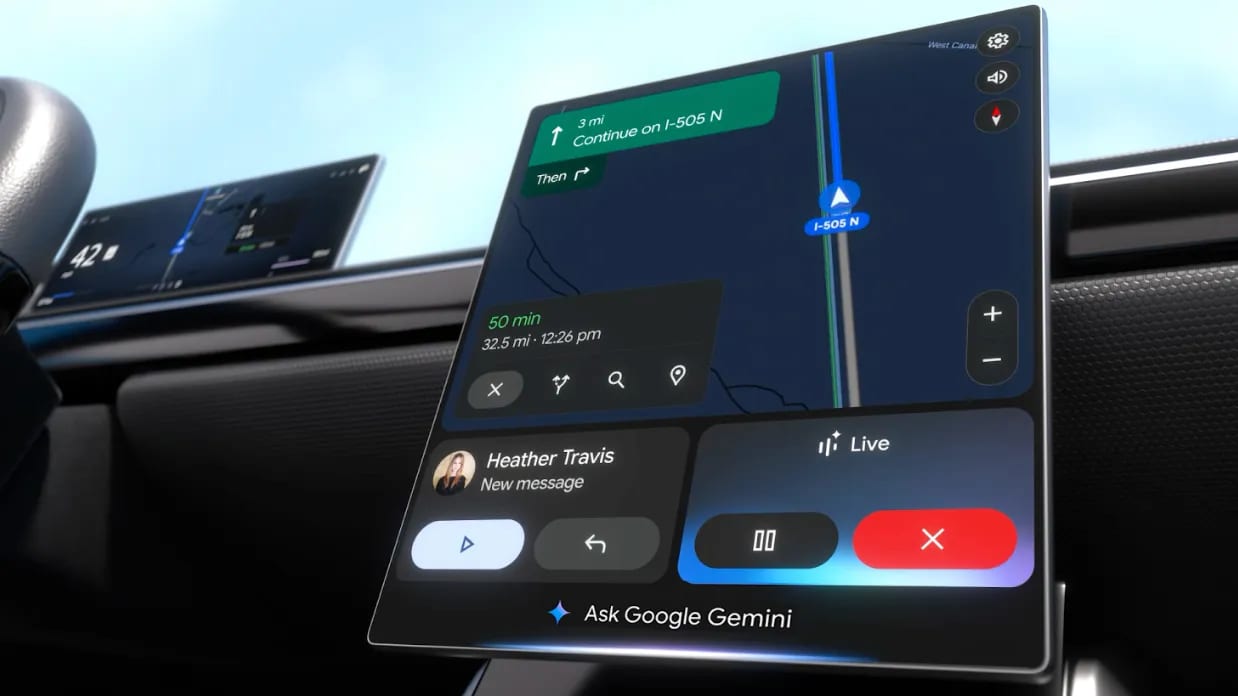
The News:
- Google is replacing Google Assistant with Gemini in cars with Google built-in, starting April 30, with an OTA software rollout to both new and existing vehicles, beginning with English-language users in the United States.
- Gemini accepts multi-part, conversational requests without requiring rigid command syntax. For example, drivers can say “I need to grab lunch, find some highly rated sit-down restaurants along the way. I’m not in a rush, oh, and I’d like to eat outside,” and follow up with questions like “What’s the parking like?”
- Gemini answers vehicle-specific questions by drawing directly from manufacturer-provided owner’s manuals. Example queries include “My garage ceiling is low and the trunk is hitting it. How do I program the trunk so it doesn’t open all the way?” Availability varies by brand and model.
- Gemini can interpret ambient cues and adjust settings: saying “It’s foggy and freezing in here” will trigger the heat and defroster simultaneously, without the driver specifying individual controls.
- GM confirmed an OTA rollout to approximately 4 million eligible model year 2022 and newer Cadillac, Chevrolet, Buick, and GMC vehicles with Google built-in.
- Gemini Live, currently in beta, supports free-flowing conversations unrelated to navigation. Drivers activate it by saying “Hey Google, let’s talk.” Future updates will add access to Gmail, Calendar, and Google Home.
My take: This is a big deal. Getting Gemini into the car means you can ask it things like “Find coffee shops on my route”, followed by “How late is the second one open?”. Apple CarPlay still only has Siri which requires specific app-intentions, so this is a major step forward for Android Auto. Volvo Cars also announced on April 30 that they are rolling out Gemini to all the models with Google built in dating back to 2020: C40, EC40, EX40, XC40, S60, V60, V60CC, XC60, V90, V90CC, S90, XC90, EX90, ES90, EX30, EX60, starting in the US.
Read more: