W23 · 2026 — June 1, 2026
Tech Insights 2026 Week 23.

Last week Cursor published the report Developer Habits, which aggregates data from their entire user base. The reports highlight two important matters that you must consider if you are working at C-level in a company with a software development department.
The first one is that the top 10% of all developers (p90) have been pulling away from median developers in absolute number of lines added per week. Median developers have seen a marginal improvement the past year, where the top 10% of all developers have been improving their output performance consistently and now produce on average 10x more lines of code than the median user. The top 1% users, the p99, now produce 46x more than the median user. This is what happens if you roll out AI tools without clear guidance on how to use them and without a clear plan how to get everyone on board with them.
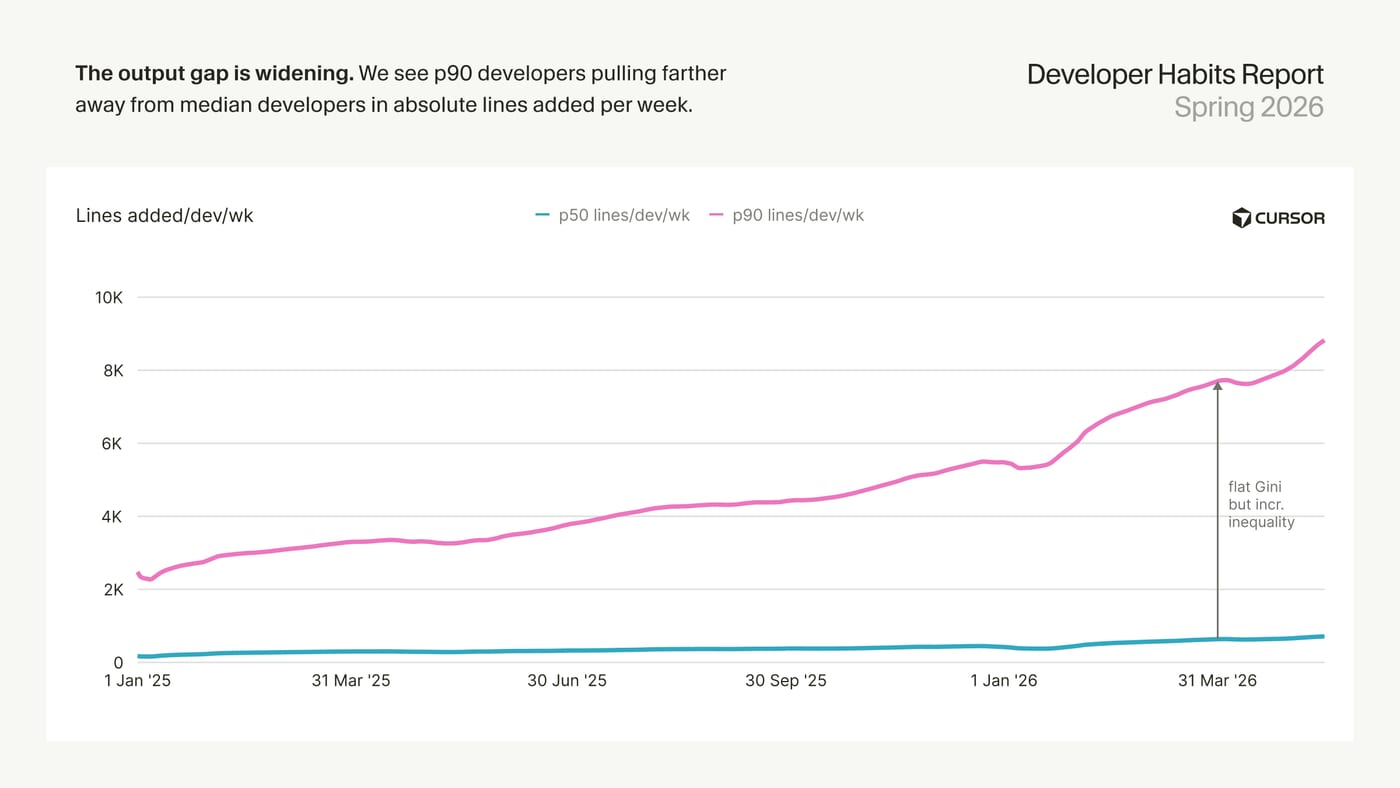
The second one is that this is not just about number of rows produced, the top developers were more productive overall. The p99 developers (top 1%) merge 15x more PRs per developer and week compared to median users, where the p90 (top 10%) produce 4x more PRs per developer and week compared to median users.

I have been teaching agentic software development for a year now, and to me it’s clear that most people have absolutely no idea on what it takes to become a successful and productive agentic AI engineer. Some developers get stuck experimenting with autonomous agents, some explore skills and MCP servers, some deep dive into custom frameworks and agentic harnesses, evaluating local models. Let them roam free and you will have 100 people doing 100 different things with AI, with few people getting actually productive with AI.
In my newsletter below you can read about BCGs latest bet on outcome-based pricing models for AI projects. I think this business model will further deepen the differences between top AI developers and median users. For this model to work, where projects are partly staffed with company employees, consultancy companies will always aim for new projects to be staffed with at least p90 developers from the company, preferably the p99 developers. This means a select few will be the one driving all new development, and since the pricing model is outcome-based there will be almost no time left to teach and coach coworkers at the same time.
I think the classic time and material business model is more suitable for this point in time, especially when it comes to AI projects. The way we work at TokenTek is that we build all new systems together with our clients, we teach them how to do it the right way, and our goal is always to leave as soon as they have the skills to continue the work on their own. I am a strong advocate on every company owning their AI strategy and in-house AI competence, because otherwise you will soon have another company controlling every single critical function in your company.
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2026 Week 23 on Spotify
Notable model releases last week:
- Dubbing v2 by ElevenLabs. High quality dubbing across 90 languages, used by over 1 million creators.
- MAI-Image-2.5, Microsoft’s strongest image model yet.
- Music v2 by ElevenLabs. Better vocals, instrumentation, and arrangement across every genre, with improved multilingual support and a set of new capabilities
- Paris 2.0 by BagelLABS. Decentralized Diffusion Model (DDM) for Video Generation.
THIS WEEK’S NEWS:
- Enterprise AI Bills Are Coming Due
- BCG CEO Says AI Is Shifting Consulting Away From Billable Hours
- Stanford Study Finds AI Hiring Tools Produce Racial Disparities
- DeepSWE: New Benchmark Exposes Wide Gaps Between AI Coding Agents
- Anthropic Raises $65 Billion at $965 Billion Valuation
- Anthropic Releases Claude Opus 4.8 With Dynamic Workflows and Improved Honesty
- Anthropic Details How It Contains Claude Agents Across Products
- NVIDIA LocateAnything: Parallel Box Decoding for Visual Grounding
- Cursor’s Developer Habits Report: Code Output Doubles, but Gains Are Uneven
- MCP 2026-07-28 Specification Release Candidate
- Nvidia Bets $150B Annually on Taiwan as US AI Hub Plans Stall
- Cognition Raises $1 Billion at $26 Billion Valuation
- CNN Sues Perplexity Over Verbatim Content Copying
Cursor’s Developer Habits Report: Code Output Doubles, but Gains Are Uneven

The News:
- Cursor published its inaugural Developer Habits Report (Spring 2026), drawing from aggregated product and engineering data to show how AI-assisted development is shifting across output, cost, and automation metrics.
- Lines of code added per developer per week have roughly doubled year over year, with growth accelerating since the start of 2026. Lines added per pull request are up approximately 2.5x year over year.
- “Mega PRs,” defined as PRs with at least 1,000 lines changed, became notably more common starting in January 2026, when many developers began testing the latest improvements in coding agents and models.
- Agent tool calls per session increased roughly 30% in just two months. Since the start of 2026, more than 5x as many agent-generated changes are reaching commits without a separate manual diff acceptance step.
- The share of accepted AI-generated lines still present after 60 minutes has risen from roughly 76% to 81% since January 2026.
- Cost per agent request varies by nearly 9x across model families benchmarked on CursorBench. Cost per accepted line narrows the gap to roughly 7x, suggesting higher-cost models produce more accepted code per request.
- Productivity gains are heavily concentrated: p99 developers produce 46x more lines than the median active user and merge 15x more PRs than the median active PR author. Gini coefficients for AI lines, spend, and token consumption are 0.77, 0.75, and 0.72 respectively.
My take: The main takeaway from this report is that the top 1% of developers produce on average 46x more lines than the median user. And this matches my experience fairly well too. You might argue that quality might be worse with that kind of speed, but you would be wrong. Using a process like the one I presented at the AI-conference GAIA in April, it’s actually possible to be 46x faster while at the same time also producing code with higher quality than the median active user.
So how do you get all your developers 46x faster? Unfortunately you can’t. At least not in the short-term. How many expert programmers do you know that also love spending hours every day writing requirements, or spend hours every day reviewing source code structure produced by AI agents? If you do find these people, I would be surprised if they are not already in your top percentage list. If you don’t, then just accept it will take some time for most people to get up to speed with this. Months, and in many cases years.
Read more:
Enterprise AI Bills Are Coming Due
https://www.axios.com/2026/05/28/ai-spending-roi-enterprise-costs

The News:
- Corporate executives are scrutinizing AI spending as rising token costs outpace measurable productivity gains, forcing companies to reassess deployment strategies.
- One unnamed enterprise client spent $500 million in a single month on Anthropic’s Claude after failing to set usage limits on employee licenses, according to an AI consultant cited by Axios.
- Microsoft cancelled most internal Claude Code licenses for approximately 100,000 engineers, effective June 30, 2026, less than six months after rolling out the program in December 2025. Per-engineer API costs ranged from $500 to $2,000 per month.
- Uber burned through its entire 2026 budget for Claude Code and Cursor in four months. COO Andrew Macdonald told the Rapid Response podcast: “It’s very hard to draw a line between one of those stats and ‘Okay now we’re actually producing 25% more useful consumer features.’”
- Enterprise AI plans are not flat-rate subscriptions. Every query and agentic task carries token costs. One CTO told Axios that employees were using enterprise AI models to check the weather.
- Sophia Velastegui, former Chief AI Technology Officer and GM AI Products at Microsoft, now of Velui Ventures, told Axios that “most individuals tend to automate tasks they find unpleasant rather than those most beneficial to the organization.” She described deploying AI licenses without targeting specific use cases as a “thousand flowers bloom” strategy that produces no measurable outcomes.
- CloudBees CEO Anuj Kapur told Axios that for some companies, the real reason behind AI-era layoffs may simply be that “it’s the only way to cover the AI bill”.
My take: There are lots of good information in this paywalled article that matches my own experience working closely with some of the largest Swedish companies rolling out AI tools, AI processes and AI strategies. Let’s break it down.
First. A high-performing senior agentic developer producing 100% source code and software tests with agentic AI, will typically have a daily token cost between $100 and $200 if not using “fast mode”. The reason is that this developer will use the best models at the best reasoning level (typically GPT-5.5 at extra high) and they have the skills to get the most out of it. That said, across an entire organization most developers have not yet reached this level of productivity and a majority might end up below $100 per month, not per day. This means that the total monthly AI bill for the company will start quite low with a few high-spenders, then grow over time. Once it starts growing, you’d better have the right metrics ready, because the financial department will want to know what they get for developer costs growing from $100 to $1,000 per month on average.
Second. The statement from Sophia Velastegui: “individuals tend to automate tasks they find unpleasant rather than those most beneficial to the organization”. I also find this to be true. This is why you cannot just push out AI tools and wait for the organizational productivity gains. You need AI leads in the teams to make sure everyone is using the tools the right way, so the costs are justified. Handing out free AI token usage without control is like serving your employees snacks 8 hours a day. Some might be able to control it, but definitely not everyone.
And third. Rate limits. You need to set rate limits. But remember that if the rate limit is reached for a team, the solution is not to stop them from using AI the rest of the month. You need escalation structures and people who can evaluate why a team suddenly blew through the budget, and some teams (such as people migrating SW stacks) will need much higher token budgets. You need to handle all that as a part of your AI governance strategy.
Used the right way AI is an incredible tool to increase quality and boost productivity. But you cannot just roll it out to your developers and expect them to find their ways with it, and this article points this out clearly. You could do it the past year as an experiment when GitHub Copilot was handed out nearly for free, but that time has passed. Now you need to do it in a structured way, preferably together with a partner company who have done this journey many times before and can work both top-down to setup agentic processes, form rate limit escalation chains, and set governance structures, and also bottom-up on-site, in your teams, making sure your developers learn to use AI the way you expect them to do.
BCG CEO Says AI Is Shifting Consulting Away From Billable Hours

The News:
- BCG CEO Christoph Schweizer addressed how AI is reshaping consulting firm revenue models and workforce strategies, speaking against predictions that AI will make management consultants obsolete.
- BCG reported 7% revenue growth in 2025, reaching $14.4 billion, while expanding its headcount to 33,500 employees to meet client demand for AI-driven transformation.
- AI- and tech-focused services now represent over 40% of BCG’s 2025 total revenue, driven by 25% year-over-year growth in AI services.
- Junior consultants at BCG are described by Schweizer as “so AI native, they use these tools as if the world had never existed without them.”
- BCG’s pricing model is shifting away from billable hours toward outcome-based fees, where consultants are paid based on measurable client results such as cost reduction or revenue growth rather than time spent.
“We are blown away about the junior talent we can hire. They are so AI native, they use these tools as if the world had never existed without them. So perhaps a bit counter to many narratives out there, we have not reduced our junior intake, and we are very happy with that.”
My take: According to Christoph: “For the majority (three quarters) of our largest AI cases, we now have a variable-fee arrangement”. BCG joins other companies like McKinsey that now generates roughly a quarter of its global fees from outcome-based pricing, a departure from the traditional time-and-material model that has defined consulting economics for decades.
I am not a fan of outcome-based pricing arrangements, because it has a tendency to shift the goal to be primarily about short-term results for the current project, and not about quality and long-term growth. When I work with clients in AI transformation projects a major part of the work is teaching the company we work with and their employees so they get really good at using, maintaining and improving the agentic AI systems we develop, so we can leave as quickly as possible and let them continue the work themselves. But the time to get up to speed with agentic AI varies greatly between companies.
Having an outcome-based pricing model means that we as consultancy company would be driven to spend as little time as possible on the learning and training part, and only focus on getting the results we need for maximum profit as quickly as possible. In contrast, a traditional time-and-material billing model means the client can decide themselves how much time we should spend on improving product quality and teach their employees how get up to speed. The BCG and McKinsey model works well as long as BCG and McKinsey owns everything and controls everything and does not have to teach you anything, but is this really how you want to build your own future AI foundation?
Read more:
Stanford Study Finds AI Hiring Tools Produce Racial Disparities
https://www.ft.com/content/5c442b38-6989-461a-988e-653f7a275eee

The News:
- A Stanford-led study analyzed 4 million job applications submitted by 3.4 million candidates across 156 employers and 11 industries, mostly companies with $5 billion or more in annual revenue, all screened by the AI hiring tool Pymetrics. It is the first large-scale independent study of AI hiring algorithms using real-world deployed data.
- The AI rejected Black and Asian applicants at rates large enough to trigger U.S. federal discrimination rules in 26% and 15% of their respective applications. These rules flag statistically disproportionate rejection rates between demographic groups. Applied equally across groups, 40,000 additional minority applications would have advanced to the next hiring stage.
- Pymetrics had previously reported no discriminatory outcomes by pooling applicant data across all positions and employers into a single calculation. The Stanford researchers measured rejection rates position by position instead, as U.S. law requires, exposing discrimination the aggregate method had hidden.
- Pymetrics does not screen resumes. It evaluates candidates through online cognitive games measuring traits such as risk tolerance, processing speed, and altruism. Scores are stored and reused for up to 330 days, so an applicant screened by two companies using Pymetrics receives the same score twice rather than an independent assessment.
- Among applicants who submitted four applications to Pymetrics-screened positions, 10% were rejected from all of them at a rate statistically higher than chance. To reduce the probability of that outcome below 0.1%, an applicant would need to apply to at least 25 positions.
- The paper, “Algorithmic Monocultures in Hiring,” will be presented at the ACM Conference on Fairness, Accountability, and Transparency in Montreal in June 2026.
“As a single vendor comes to dominate decision-making in a space, their quirks or shortfalls can be present across that entire sector in a way that wasn’t possible before.” Kathleen Creel, a co-author of the study
My take: A previous study by researchers found that “distinctively Black names” reduced the probability of employer contact by 2.1 percentage points relative to “distinctively white names”. This research analyzed individual roles, and found that one in 10 of the positions in the dataset demonstrated “adverse impact” against Black applicants, while one in 20 roles did so for Asian applicants. The study says this happens because Pymetrics trains its model on a company’s existing high-performing employees, then screens new candidates to match that profile. If a company’s current workforce lacks racial diversity, the model learns to replicate that historical pattern.
Pymetrics has been around for over a decade now, and the reason this hasn’t come up until now is that no independent researcher had access to cross-employer data until now. Previous audits were limited to single companies, which made it impossible to detect the pattern of the same score following a candidate from employer to employer. This study only became possible because Pymetrics voluntarily handed over four years of proprietary data under a special research agreement.
The EU AI Act classifies hiring algorithms as high-risk AI systems, with compliance requirements taking effect on August 2 this year. It mandates transparency, documentation, and bias testing, but does not require the kind of cross-employer data access that made this study possible.
Read more:
DeepSWE: New Benchmark Exposes Wide Gaps Between AI Coding Agents
https://x.com/serenaa_ge/status/2059308218564890875

The News:
- Datacurve released DeepSWE on May 26, a new agentic coding benchmark with 113 original tasks across 91 active open-source repositories and five programming languages (TypeScript, Go, Python, JavaScript, and Rust).
- GPT-5.5 leads the leaderboard at 70% (±4%), followed by Claude Opus 4.8 at 58%, GPT-5.4 at 56%, Claude Opus 4.7 at 54%, Claude Sonnet 4.6 at 32%, and Gemini 3.5 Flash at 28%.
- Tasks use short prompts averaging 2,158 characters, but reference solutions require adding an average of 668 lines of code across 7 files, compared to roughly 120 lines across 5 files typical of SWE-Bench Pro.
- DeepSWE’s verifier shows a 0.3% false positive rate and a 1.1% false negative rate, compared to 8.5% and 24.0% respectively for SWE-Bench Pro, based on Datacurve’s audit of 30 sampled tasks run with 10 agent configurations each, 3 times per task.
- All tasks are original, with no public pull requests or merged commits available in the evaluation environment, blocking the type of git history retrieval that inflated scores on SWE-Bench Pro.
- Claude Opus 4.7 and GPT-5.4 spontaneously wrote new repository-native tests in over 80% of DeepSWE rollouts, compared to 3-28% under SWE-Bench Pro’s prompt template, which instructs agents not to modify testing logic.
My take: If you have been following my newsletters you know I have been pushing for new SW-dev tests for a long time now. SWE-Bench Pro is close to useless now, with every single AI model being able to create 120 lines on average across 5 files. This test is much more interesting since it bumps this to 668 lines on average across 7 files, and it’s here the difference between the models becomes apparent. DeepSWE clearly shows why I have been using GPT-5.x myself for coding since December 2025. For simple autocomplete tasks or function-based coding, everyone will get good results with Opus and Sonnet. But it was over a year since I worked that way. If you are still working like that, maybe it’s time to kick it up a notch. Start writing more detailed prompts that lets the agent create more things in one go, and maybe give GPT-5.5 a good try. It’s an amazing model.
Read more:
Anthropic Raises $65 Billion at $965 Billion Valuation
https://www.anthropic.com/news/series-h

The News:
- Anthropic closed a Series H funding round of $65 billion, bringing its post-money valuation to $965 billion, above OpenAI’s most recent post-money valuation of $852 billion from its March 2026 round.
- The round was led by Altimeter Capital, Dragoneer, Greenoaks, and Sequoia Capital, with Capital Group, Coatue, D1 Capital Partners, GIC, ICONIQ, and XN as co-leads.
- $15 billion of the total represents previously committed investments from hyperscalers, including $5 billion from Amazon.
- Anthropic’s run-rate revenue crossed $47 billion earlier this month, up from its Series G post-money valuation of $380 billion in February 2026.
- The company signed compute agreements with Amazon for up to five gigawatts of new capacity, with Google and Broadcom for five gigawatts of next-generation TPU capacity, and with SpaceX for GPU access in Colossus 1 and Colossus 2.
- Strategic infrastructure partners Micron, Samsung, and SK hynix joined the round to support memory, storage, and logic chip supply.
- Claude is now available on all three major cloud platforms: AWS, Google Cloud, and Microsoft Azure, with AWS remaining Anthropic’s primary cloud provider and training partner.
My take: To me it makes absolutely no sense in Anthropic being worth more than OpenAI, and the main reason for that is that OpenAI just launched their new base model GPT-5.5, a ground-up rebuild with a completely new pre-training set. GPT-5.5 is also natively omnimodal, meaning it processes text and images in a unified architecture. OpenAI also has a the edge over Anthropic when it comes to context window management, where Anthropic models still forget much of what is put into the context memory. If Anthropic managed to launched their mythical Mythos model, and they could prove they have the infrastructure to support it, and it performed better than GPT-5.5, then this valuation would at least make some sense. Now, I fully expect the fine tuned versions of GPT-5.5 to run circles around all currently available Anthropic models in the next few months.
Anthropic Releases Claude Opus 4.8 With Dynamic Workflows and Improved Honesty
https://www.anthropic.com/news/claude-opus-4-8

The News:
- Anthropic released Claude Opus 4.8 on May 28, with improved performance across coding, agentic reasoning, and knowledge work benchmarks, at the same standard pricing of $5 per million input tokens and $25 per million output tokens.
- On SWE-Bench Pro, Opus 4.8 scores 69.2%, up from Opus 4.7’s 64.3%, and ahead of GPT-5.5’s 58.6% and Gemini 3.1 Pro’s 54.2%. On Terminal-Bench 2.1 using the Terminus-2 public harness, Opus 4.8 scores 74.6%, while GPT-5.5 scores 78.2% using the Codex CLI harness, a different test condition.
- Anthropic reports Opus 4.8 is approximately four times less likely than Opus 4.7 to let flaws in its own generated code pass without comment.
- Dynamic Workflows, available as a research preview in Claude Code for Enterprise, Team, and Max plans, allows Claude to plan a task, spawn hundreds of parallel subagents in a single session, and verify outputs before returning results. Anthropic gives codebase-scale migrations across hundreds of thousands of lines of code as an example use case.
- Fast mode for Opus 4.8 costs $10 per million input tokens and $50 per million output tokens, running at 2.5x the speed and priced three times cheaper than fast mode was for previous models.
- A new Effort Control feature in claude.ai and Cowork lets users select how much thinking Claude applies before responding, ranging from standard up to “max.” The Messages API now accepts system entries mid-conversation, letting agent harnesses update permissions, token budgets, or environment context without breaking the prompt cache.
My take: User feedback from Opus 4.8 had been mixed. It’s a bit better than Opus 4.7 in some areas, but still behind GPT-5.5 in others. As expected with a highly fine-tuned model like this it aces benchmarks like SWE-Bench Pro, but still falls behind GPT-5.5 on benchmarks that are not part of it’s training curriculum like DeepSWE. This is hopefully the last fine-tuning release we’ll get from the Opus 4.x series before it’s time for either a new base model in 5.0 or Mythos.
Anthropic Details How It Contains Claude Agents Across Products
https://www.anthropic.com/engineering/how-we-contain-claude
The News:
- Anthropic published an engineering post on May 25, detailing the containment architectures used across claude.ai, Claude Code, and Claude Cowork, with disclosures of three real security incidents.
- For claude.ai, code runs in ephemeral gVisor containers, fully server-side, with a per-session filesystem and no access to the user’s local machine.
- Claude Code uses an OS-level sandbox (Seatbelt on macOS, bubblewrap on Linux), allowing local reads and workspace writes while blocking network access by default. This reduced permission prompts by 84%, and Anthropic open-sourced the runtime.
- Claude Cowork runs inside a full virtual machine (Apple Virtualization framework on macOS, HCS on Windows) with its own Linux kernel, filesystem, and process table. Credentials remain in the host keychain and never enter the guest environment.
- Prior to the current architecture, Claude Code required user approval for each action. Telemetry showed users approved 93% of prompts, producing approval fatigue. The new Claude Code auto mode automates lower-risk approvals via a model-based classifier, blocking roughly 0.4% of benign commands while still letting through approximately 17% of overeager actions.
“Claude Code doesn’t implement sandboxing for Bash commands. If we tried to enforce a strict sandbox, many commands would stop working because they have side-effects like writing to storage outside of the working directory.” Robert Boyce, Anthropic
My take: This article is worth a read if you’re curious how Anthropic chose different sandbox environments for their products. In my experience it’s hard to accidentally get Claude Code or Codex to touch files outside the current working folder. That said, when you ask Claude Code or Codex to change something across 1,000 files, it will typically write a Python script to do the work. When you approve that script, neither tool asks for permission on individual file operations. A typo or logic error in that generated script can silently cause unplanned changes with no further prompts. Both tools have OS-level sandboxing, but it enforces workspace boundaries, not fine-grained file access control. And sandbox implementations are not bulletproof either: a network sandbox bypass in Claude Code went undetected for five months before being quietly patched in April 2026 with no public disclosure. My recommendation is to always to run AI agents inside Docker containers or devcontainers whenever possible.
Read more:
NVIDIA LocateAnything: Parallel Box Decoding for Visual Grounding
https://research.nvidia.com/labs/lpr/locate-anything/

The News:
- NVIDIA Research released LocateAnything on May 26, a 3B-parameter vision-language model for visual grounding that takes a natural language prompt and returns bounding boxes or points identifying matching objects or regions in an image.
- The core technique, Parallel Box Decoding (PBD), predicts all four bounding box coordinates (x1, y1, x2, y2) as an atomic unit in a single parallel step rather than generating them token by token, which removes the sequential bottleneck of standard autoregressive decoding.
- The model supports three inference modes: Fast (full parallel decoding for maximum throughput), Slow (autoregressive for maximum accuracy), and Hybrid (parallel by default, with automatic fallback to autoregressive when format irregularities or spatial ambiguities are detected).
- Training used LocateAnything-Data, a dataset of 12 million images, 138 million natural language queries, and 785 million bounding boxes spanning general object detection, GUI element grounding, OCR, document layout, referring expressions, and point-based localization.
- The model is available on Hugging Face (nvidia/LocateAnything-3B) and GitHub (NVlabs/Eagle/Embodied) under an NVIDIA license permitting academic and non-profit research use only; commercial use is not permitted except by NVIDIA and its affiliates.
- A live demo runs on Hugging Face Spaces, and the paper was submitted as an arXiv tech report (arXiv:2605.27365) and will be presented at the NVIDIA Booth at CVPR 2026 on June 5, 2026.
My take: So, how does this compare to other object recognition frameworks like Ultralytics YOLO? When it comes to YOLO, you use it when you know in advance exactly what you want to detect and need it fast and cheap. YOLO works in real time, runs on cheap hardware, and is extremely fast. But it only recognizes the categories it was trained on. LocateAnything instead works like this: you hand it instructions like “find the button labeled Submit in this screenshot” or “locate the invoice number in this document”, and it finds it. It understands free-form language and can locate virtually anything you can describe in words, across photos, app interfaces, PDFs, and drone footage.
So when do you pick YOLO vs LocateAnything? Pick YOLO if you know exactly what you are looking for and need real time performance. LocateAnything processes individual queries at around 12-16 objects per second, which is more suitable for agent tasks, document processing, and GUI automation.
MCP 2026-07-28 Specification Release Candidate
https://blog.modelcontextprotocol.io/posts/2026-07-28-release-candidate/
The News:
- The Model Context Protocol (MCP) published a release candidate for its 2026-07-28 specification, described by the project as the largest revision since MCP launched. The RC was locked on May 21; the final specification ships on July 28, 2026, giving SDK maintainers a ten-week validation window.
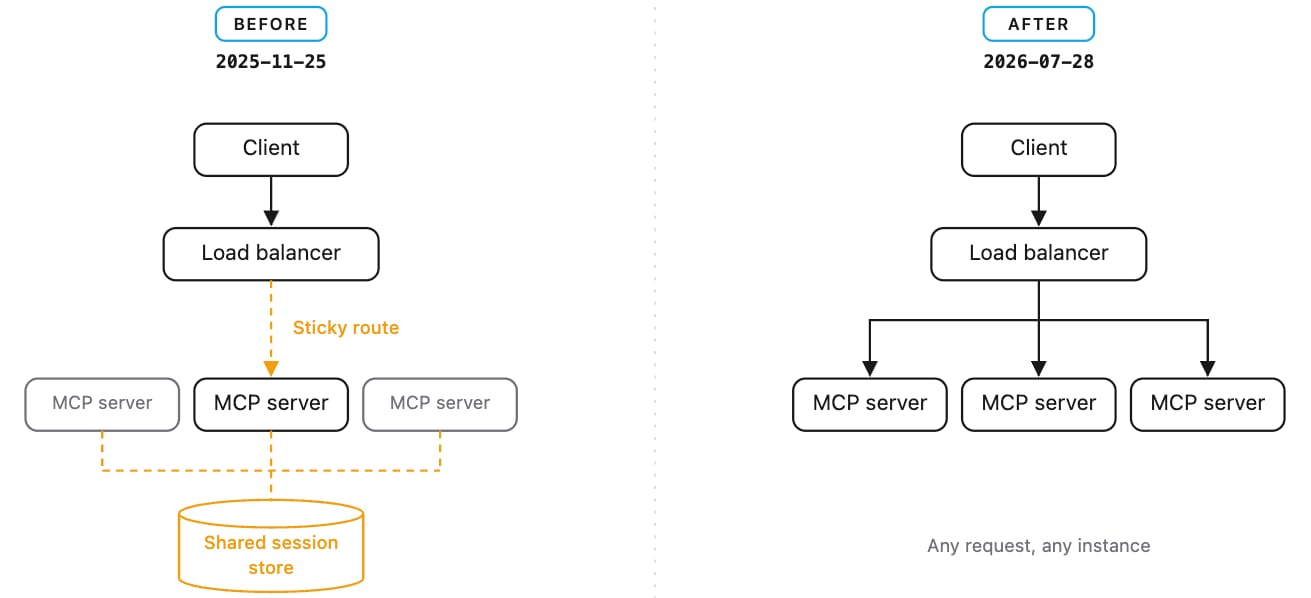
- The headline change removes the stateful session model entirely. The initialize/initialized handshake (SEP-2575) and the Mcp-Session-Id header (SEP-2567) are gone. Protocol version, client info, and capabilities now travel in
_metaon every request, so any request can reach any server instance without sticky sessions or a shared session store. - Two official extensions ship with the RC. MCP Apps (SEP-1865) lets servers deliver HTML interfaces rendered in a sandboxed iframe; every UI action routes through the same JSON-RPC audit path as a direct tool call. The Tasks extension graduates from the experimental core, adopts a server-directed lifecycle where clients drive progress via tasks/get, tasks/update, and tasks/cancel, and removes tasks/list because it cannot be scoped safely without sessions.
- Six SEPs harden authorization against OAuth 2.0 and OpenID Connect deployments. SEP-2468 requires clients to validate the iss parameter on authorization responses per RFC 9207, mitigating authorization server mix-up attacks. Separately, SEP-2243 requires Mcp-Method and Mcp-Name headers on every Streamable HTTP request, so load balancers and gateways can route on operation type without body inspection.
- Tool inputSchema and outputSchema are upgraded to full JSON Schema 2020-12 (SEP-2106), adding support for oneOf, anyOf, allOf, conditionals, and $ref. Three existing features are deprecated but not removed: roots, sampling, and logging. A formal deprecation policy (SEP-2577) guarantees at least 12 months between deprecation and any possible removal.
My take: The current specification of MCP requires every AI session to establish a handshake with the server and maintain a session ID, forcing all requests from that session to route to the same backend instance. This made horizontal scaling complicated and required sticky sessions or shared session stores. The new spec removes the handshake and session ID entirely. Every request is now self-contained, carrying its own context in a metadata field. This makes MCP servers deployable behind standard load balancers with no special configuration, the same way conventional REST APIs work today. MCP is not going away, it’s a nice complement to skills and commands, and getting rid of the stateful session model is a key improvement to making it stick around for a long time.
Nvidia Bets $150B Annually on Taiwan as US AI Hub Plans Stall

The News:
- Nvidia CEO Jensen Huang announced on May 27 that the company will increase its annual spending with Taiwanese supply chain partners to $150 billion, positioning Taiwan as its primary operational hub rather than the US.
- Huang called Taiwan “the epicentre of the AI revolution,” stating: “This is where the chips come, packaging comes. This is where the systems are made. This is where AI supercomputers were created.”
- Nvidia signed a 50-year land lease (with an optional 20-year extension) in Taipei’s Beitou-Shilin Technology Park for a new headquarters, dubbed the “Constellation” project, at a projected cost of over NT$40 billion (~$1.27 billion).
- Construction is scheduled to begin by end of 2026, with the facility set to open in 2030 and employ 4,000 people, up from around 1,000 currently in Taiwan.
- Huang flagged energy supply as a key condition for Taiwan’s role, telling Taipei Mayor Chiang Wan-an: “Human labor needs rice. Our AI labor needs electricity.”
My take: Just one week before this announcement, AMD also announced a $10 billion investment into Taiwan’s semiconductor and AI sectors. Today, TSMC produces around 90% of the world’s advanced chips, and Taiwanese companies produce roughly 90% of the world’s AI servers. Last year Nvidia pledged $500 billion in US AI infrastructure over four years, but that figure represents the projected value of products manufactured and sold through partners like TSMC, Foxconn, and Wistron, not Nvidia’s own capital. The actual factories are being built and owned by those partners. In other words, even the US buildout runs through Taiwanese companies.
Cognition Raises $1 Billion at $26 Billion Valuation
https://cognition.ai/blog/series-d

The News:
- Cognition, the San Francisco company behind the autonomous AI software engineer Devin, closed a Series D round exceeding $1 billion at a $26 billion post-money valuation on May 27, led by Lux Capital, General Catalyst, and 8VC, with participation from Founders Fund, Bain Capital Ventures, Ribbit Capital, Alpha Wave, Avenir, Vitruvian, Atreides, and others.
- Enterprise adoption has grown more than 10x since the start of 2026, with annualized run-rate revenue now at $492 million.
- Cognition reports that 89% of all code committed by its own engineers is now committed by Devin, with the remaining 11% attributed to local agents in Windsurf.
- Enterprise clients include Citi, Goldman Sachs, Mercedes-Benz, Santander, Dell, Elevance, the U.S. Army, and the U.S. Navy. Mercedes-Benz reduced an eight-month legacy modernization project to eight days using Devin. Itaú, Latin America’s largest bank, now resolves 70% of security vulnerabilities automatically with Devin.
- Cognition recently launched SWE-1.6, its own internally trained model now available in Windsurf, with throughput of up to 950 tokens per second.
My take: In September 2025 Cognition did a Series C round at a valuation of $10.2 billion, and now 8 months later they are worth $26 billion. Devin is an interesting proposal. Where tools like Cursor, Claude Code and Codex assist with multi-file code generation, Devin operates asynchronously, planning and executing complete tasks including testing, debugging, and pull request submission without developer supervision. The year-old quote from Han Xiao, VP AI at Elastic, explains Devin as: “it’s not copilot it’s autopilot, and you can truly treat it as a colleague”.
I have never felt the need to offload my planning tasks to an AI yet, I like to be in control. And this is why I prefer to use Codex and Claude Code. Do you use Devin, and why did you choose it before Codex or Claude Code? I would be very interested in your feedback.
CNN Sues Perplexity Over Verbatim Content Copying
https://www.theverge.com/ai-artificial-intelligence/938893/cnn-perplexity-ai-copyright-lawsuit

The News:
- CNN filed a copyright lawsuit against AI search company Perplexity on May 28, marking CNN’s first copyright action against an AI company and the first such suit from a television broadcaster.
- The 54-page complaint, accompanied by 1,165 pages of supporting documents, alleges that Perplexity scraped and reproduced more than 17,000 CNN articles, videos, and images without permission or payment.
- CNN claims Perplexity’s AI search engine bypassed its subscription paywall, making paywalled content freely accessible to users by entering article headlines as prompts.
- In October 2025, CNN and Perplexity negotiated a Comet Plus partnership that would have allowed Perplexity to surface CNN’s paywalled content to Comet Plus subscribers in exchange for payment; the deal collapsed in November 2025 over disagreements on content usage terms. CNN then sent a cease-and-desist letter that Perplexity did not respond to.
- CNN seeks an unspecified amount in damages and a permanent injunction. Perplexity Chief Communications Officer Jesse Dwyer responded: “You can’t copyright facts.”
My take: CNN posts their first lawsuit ever against an AI company, and Perplexity quickly answers: “You can’t copyright facts.” I have previously written quite a lot about Perplexity in my newsletter:
- Tech Insights 2025 Week 4. Cloudflare posts report that Perplexity evades no-crawl directives.
- Tech Insights 2026 Week 16. Perplexity partners up with Plaid, a payment company forced to pay a $58 million class action settlement in 2022.
- Tech Insights 2026 Week 16. Perplexity is charged a class-action lawsuit for secretly forwarding user conversations to Meta and Google, including sessions conducted in Perplexity’s “Incognito” mode.
Perplexity has also previously been sued by The New York Times, News Corp (Wall Street Journal, New York Post), Encyclopedia Britannica, Merriam-Webster, and Reddit. Based on the company history the business model of Perplexity seems to be quite clear: Index everything that is technically possible to index (CNN, Cloudflare), give away any information that brings money to partners (Meta, Google), and partner with companies willing to give Perplexity money (Plaid). If you are using Perplexity today and like it, fine I won’t judge, but please do not ever send anything even remotely sensitive to the Perplexity search engine.
As a side note: Last week Perplexity launched their “Computer” service that can now run inside Microsoft 365 applications. I feel I don’t even need to say that I strongly advice you not to even try this one.
Read more: