Tech Insights 2026 Week 24
June 8, 2026

Last week OpenAI finally released their models on Amazon Bedrock, through both the API and the updated Codex app. This removes one of the biggest barriers for companies wanting to adopt GPT-5.5 and Codex but were held back by security, compliance, procurement, billing, and governance requirements. OpenAI worked closely with Amazon on the launch and even published a short getting started tutorial: Getting Started with OpenAI Models on Amazon Bedrock. If you have only experimented with GitHub Copilot or Claude Code in your organization I really recommend that you give Codex a go. For large, complex code bases it’s in a completely different league.
Last week we got dozens of new model releases, and you’ll find some of them in the “Notable model releases” section below. Gemma 4 by Google can now run on laptops with 16GB of VRAM, Ideogram 4 is Ideogram’s first open-weight text-to-image model, Mellum 2 is JetBrains’ new open-source coding model, and Nemotron 3 Ultra is the best-performing US-created open-weights model to date. If you are working with open or local models, you’ll have a busy week this week.
Otherwise the main show last week was from Microsoft who launched seven new AI models, built from scratch on commercially-licensed data. Microsoft is doing things the right way, and I have no doubt MAI-Thinking-1 will reach a level where it becomes the default model for all their Copilot integrations later in 2026. The new Frontier Tuning option is also interesting: organizations can now create their own variants of MAI, tuned to their workflows and documents using reinforcement learning. This is in direct contrast to OpenAI, who last month announced they are winding down self-serve fine-tuning of their models. But having a customized model that outperforms GPT-5.5 at a price 10x lower for a specific task is extremely interesting, especially for us “agent builders” who help companies automate large work tasks with agentic AI.
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2026 Week 24 on Spotify
Notable model releases last week:
- Gemma 4 by Google, designed to bring agentic multimodal intelligence directly to laptops.
- Ideogram 4 by Ideogram. Ideogram’s first open-weight text-to-image model, trained from scratch - this is not a fine-tune of an existing model.
- Magenta RealTime 2 by Google DeepMind. Open music generation model built for on device streaming generation with low-latency control.
- Mellum2 by JetBrains, a 12B-parameter MoE language model optimized for coding, reasoning, tool use, and agentic workflows.
- Nemotron 3.5 Content Safety by NVIDIA. Compact 4B-parameter multimodal safety moderation model that evaluates prompts, responses, and images to determine whether content is safe or unsafe.
- Nemotron 3 Ultra by NVIDIA. New 550B parameter model by NVIDIA which is “the most intelligent US open weights model” to date.
THIS WEEK’S NEWS:
- Anthropic Claude Now Writes Over 80% of Its Own Code
- Microsoft Launches Seven New MAI Models
- Microsoft Scout: An Always-On Autonomous Work Agent for Microsoft 365
- Microsoft’s Majorana 2 Quantum Chip Built with Agentic AI
- Microsoft Project Solara: A New Platform for Agent-First Devices
- Meta Launches Business Agent Across WhatsApp, Messenger, and Instagram
- NVIDIA Cosmos 3: Open Omnimodal World Foundation Model for Physical AI
- Perplexity Releases Search as Code for AI Agents
- OpenAI Expands Codex With Role-Specific Plugins, Sites, and Annotations
- ChatGPT Memory Gets a Dreaming Upgrade
Anthropic Claude Now Writes Over 80% of Its Own Code
https://www.anthropic.com/institute/recursive-self-improvement
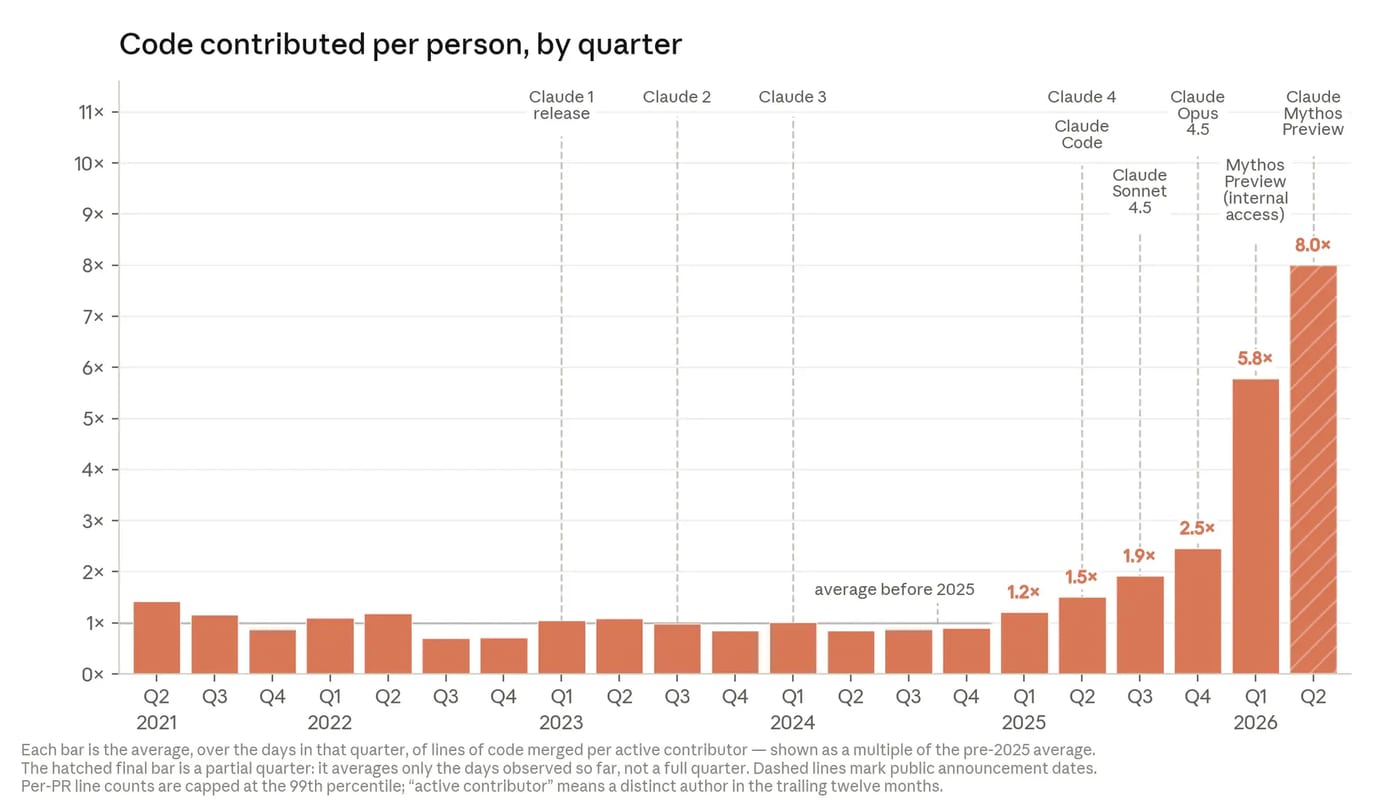
The News:
- The Anthropic Institute published a report on June 3, showing that Claude now authors more than 80% of the code merged into Anthropic’s production codebase, up from low single digits before Claude Code launched in February 2025.
- Anthropic engineers in Q2 2026 merge 8x as much code per day as they did in 2024, driven primarily by Claude writing the code while engineers direct and review.
- On the most open-ended internal tasks (no clear specification, no known solution), Claude’s success rate reached 76% in May 2026, up 50 percentage points in six months.
- In a code optimization benchmark run at each model release, Claude Opus 4 achieved roughly a 3x speedup in May 2025; by April 2026, Claude Mythos Preview reached roughly 52x on the same task, while a skilled human researcher reaches roughly 4x in four to eight hours.
- METR measured Claude Mythos Preview as capable of sustaining work for “at least” 16 hours, placing it “at the upper end of what [METR] can measure without new tasks.”
- In an April 2026 open-ended AI safety experiment, Claude-powered agents recovered 97% of a defined performance gap on a supervised learning problem, compared to 23% recovered by two human researchers over roughly a week, spending roughly $18,000 in compute over 800 cumulative agent-hours.
- Anthropic states that recursive self-improvement, where an AI designs and trains its own successor without human involvement, has not yet occurred and is not inevitable, but notes it “could come sooner than most institutions are prepared for.”
- The report calls for a coordinated, verifiable global pause mechanism for frontier AI development, modeled loosely on existing arms control regimes, and commits the Anthropic Institute to convene policymakers, researchers, and other AI companies to develop those mechanisms.
“We believe it would be good for the world to have the option to slow or temporarily pause frontier AI development”
My take: Anthropic writes: “If it were possible to effectively slow the development of this technology to give ourselves more time to deal with its immense implications, we think that would likely be a good thing. But if a slowdown simply lets the least cautious actors catch up technologically, it could leave everyone less safe. Without a global coordination mechanism, companies and governments will have to make difficult decisions about safety while under competitive and geopolitical pressures”.
I think everyone understands that this is completely impossible. A “global coordination mechanism” between all countries means pausing all further AI research so the US can continue staying in the lead while the rest of the world waits for their turn. I don’t even understand why Anthropic puts out this nonsense. Maybe it is to show their concerned employees that they want to be the “good guys”, and it is the rest of the world that don’t agree with pausing all research.
About the rest of the news. Claude is not developing the next Claude yet. Developers using Claude are automating their work to be 8x more productive than two years ago. For everyone working with agentic engineering this should come as no surprise, and we are still very far away from having an AI autonomously building the next AI. The models are simply not at that level yet. The only takeaway I got from this post is to drive valuation up for their IPO, indicating they are so close to automatic exponential AI growth that they really should be stopped, but that won’t happen so the sky is the limit for them.
Microsoft Launches Seven New MAI Models
https://microsoft.ai/news/building-a-hillclimbing-machine-launching-seven-new-mai-models/
The News:
- Microsoft AI, led by CEO Mustafa Suleyman, announced a family of seven in-house models at Build 2026 on June 2, covering reasoning, coding, image generation, transcription, and voice, all trained from scratch on commercially licensed data without distillation from third-party models.
- MAI-Thinking-1 is the flagship reasoning model, a sparse Mixture of Experts architecture with 35 billion active parameters and approximately 1 trillion total parameters, a 256K context window, and scores of 97.0% on AIME 2025 and 94.5% on AIME 2026. In blind evaluations run by Surge across 1,276 tasks, human raters preferred it over Claude Sonnet 4.6, and it matches Claude Opus 4.6 on SWE-Bench Pro coding benchmarks.
- MAI-Code-1-Flash is a 5-billion-parameter coding model rolling out across GitHub Copilot and VS Code, scoring 51.2% on SWE-Bench Pro versus Claude Haiku 4.5’s 35.2%, and solving harder coding tasks with up to 60% fewer tokens on SWE-Bench Verified.
- MAI-Transcribe-1.5 runs five times faster than competing models, achieves state-of-the-art accuracy on the FLEURS speech benchmark, and supports 43 languages with built-in domain-specific terminology handling.
- MAI-Voice-2 generates speech across 15 languages with voice adaptation from a short audio sample, and includes safeguards against misuse.
- Frontier Tuning uses reinforcement learning in real-world environments so organizations can train MAI models on their own workflows. A MAI model tuned for Excel matched GPT 5.4 at up to 10x greater efficiency; a model tuned for McKinsey outperformed GPT-5.5 on quality at projected 10x lower cost based on public pricing data.
- Model weights are available for direct fine-tuning, with distribution on Microsoft Foundry, OpenRouter, Fireworks, and Baseten.
My take: I wouldn’t say the benchmarks results from these new models are a disaster, but they are not good. So how come these models are so far away in performance from publicly available open source models like DeepSeek and Qwen? I think the simple reason is that Chinese models like DeepSeek distilled GPT and Claude outputs, where all Microsoft models are built from scratch on commercially licensed data. Microsoft is doing this the right way, and I truly hope it’s possible to catch up with the other AI giants by doing things by the book. That said, MAI-Thinking-1 and MAI-Code-1-Flash are far away from the best models from Anthropic and OpenAI, but give it a bit of fine tuning and polishing and they might both become quite usable by the end of 2026. If you have been following my newsletter for a while you know I am a firm believer that Microsoft will switch over to their own AI models as default models in both M365 Copilot and GitHub Copilot as soon as they are comparable in performance to GPT and Claude, and given current progress that might happen this year already.
And to clarify, the title of the news page at Microsoft is “Launching seven new MAI models”, however only four of these models were actually launched at Build 2026. MAI-Image-2, MAI-Voice-1 and MAI-Transcribe-1 were available earlier and I have written about them previously in Tech Insights, the Build announcement just renamed them to be part of the “MAI” family of models.
Frontier Tuning is perhaps the most interesting news of all these Build 2026 announcements, where organizations can create their own variants of MAI that is tuned to their own workflows and documents with reinforcement learning. Having a customized model that outperforms GPT-5.5 at a price that’s 10x lower for a specific task is extremely interesting, especially for us “agent builders” that help companies automate work tasks with agentic AI.
Read more:
- CNBC: Microsoft unveils new AI models lessen reliance on OpenAI, lower costs
- MAI-Thinking-1 | Hacker News
Microsoft Scout: An Always-On Autonomous Work Agent for Microsoft 365

The News:
- Microsoft Scout is the first product in a new agent category called Autopilots: autonomous agents that carry their own Entra identity and act on a user’s behalf across Microsoft 365 without requiring a prompt for each task.
- Scout connects to Teams, Outlook, OneDrive, SharePoint, email, calendar, and contacts, operating across cloud, desktop, and web, and can be extended to local resources and MCP servers via a desktop app.
- Scout builds context through a system called Work IQ, learning user priorities over time. Concrete tasks include scheduling meetings across time zones, generating prep materials, blocking calendar time for deliverables, tracking stalled decisions, and monitoring implicit commitments made in messages and meetings.
- Each Scout instance runs under its own governed Entra identity, with credentials scoped per task, redacted from logs, and subject to Microsoft Purview sensitivity labels and data loss prevention policies. Sensitive actions can require human sign-off before executing.
- Access currently requires Frontier enrollment, Intune policy configuration, an opt-in attestation, and a GitHub Copilot license. Priority access for the private preview goes to Microsoft 365 E5 and Purview customers, with broader access beginning Q4 2026 and a public beta not expected before mid-2027.
My take: Microsoft Scout builds on OpenClaw, the popular open-source agent framework by Peter Steinberger. And here Microsoft has connected it to the entire Microsoft 365 suite with its own Entra identity. The internal working name for Scout was ClawPilot, which later was renamed Microsoft Scout. Anyone want to bet against that it will be renamed to something with “Copilot” later this year?
I know the process Peter Steinberger used when developing OpenClaw, and at the speed this platform is moving I would not feel confident giving an AI agent built on OpenClaw access to M365 without user prompts required for each task. Instead, if you haven’t already, start exploring how you can create a similar platform yourself in your organization but do it in a secure way, only opening up the exact entry points needed for each specific agentic workflow. Like the Meta Business Agent mentioned below, Microsoft Scout needs to have full access since it’s an agentic solution hosted by Microsoft. Building it yourself in your own infrastructure means you can have multiple instances isolated from each other to secure your data. This is what I would recommend instead.
Microsoft’s Majorana 2 Quantum Chip Built with Agentic AI
https://news.microsoft.com/source/features/innovation/majorana-2-microsoft-discovery-agentic-ai/

The News:
- Microsoft announced Majorana 2, a topological quantum chip developed with the help of its Microsoft Discovery agentic AI platform, targeting a scalable, commercially viable quantum computer by 2029, cutting the previous projected timeline in half.
- Majorana 2 qubits report a mean lifetime of 20 seconds and up to one minute in some instances, compared to microseconds for conventional qubit approaches, representing a 1,000x improvement over Majorana 1.
- The materials stack changed from aluminum to lead-based superconductors, which better shields qubits from cosmic disturbances and environmental noise. Chetan Nayak, Microsoft Technical Fellow, said: “That was actually a fairly large change, and it led to big, big improvements in device quality.”
- The chip operates at one-microsecond gate speeds with a qubit size of 1/100th of a millimeter.
- Microsoft Discovery’s AI agents automated measurement cycles, managed fabrication workflows, and analyzed nearly two decades of quantum research data across multiple formats and disciplines. Setting parameters and running measurements previously each took weeks; agents reduced the cycle time by “orders of magnitude,” according to VP Zulfi Alam.
- Microsoft Discovery is now generally available as a platform for enterprise R&D, and a free Microsoft Discovery app is available in early preview for individuals with a GitHub Copilot account.
“Microsoft now expects to achieve a scalable quantum computer by 2029, cutting its original timeline in half”
My take: Majorana 1 was introduced in 2025, and achieved parity lifetimes measured in milliseconds. And now a year later Majorana 2 reports a lifetime of 20 seconds. If true, that’s an extraordinary achievement. And this is where this news kind of falls flat.
The chips are named after Majorana fermions, particles first theorized in 1937 that are their own antiparticles. In quantum computing, they are interesting because they store quantum information non-locally across two physically separated points, which makes the information resistant to local noise and interference that corrupts ordinary qubits.
The challenge however is that no one has conclusively proven they exist in a controllable, reproducible form in hardware. A 2018 Nature paper claiming Majorana evidence was retracted in 2021 after independent review found key data had been omitted. Majorana 1 was disputed almost immediately, with physicist Henry Legg arguing the measurement protocol was flawed and that it never demonstrated a functioning topological qubit. Now Majorana 2 arrives with even larger claims, but the supporting paper is still a preprint, peer review has not started, and Legg’s core objection remains: the new paper presents only Z-basis measurements, while demonstrating an actual qubit requires both X and Z.
Microsoft Project Solara: A New Platform for Agent-First Devices
https://commandline.microsoft.com/project-solara-build-2026/

The News:
- Microsoft announced Project Solara at Build 2026 in San Francisco on June 2, a chip-to-cloud software platform designed to run AI agents as the primary interaction model, replacing traditional apps on a new category of purpose-built devices.
- The platform runs on Microsoft Device Ecosystem Platform (MDEP), an enterprise-grade OS built on Android Open Source Project (AOSP), not on Windows. It includes Microsoft Intune device management, Entra ID sign-in, Windows Hello biometric authentication, and a physical microphone mute button.
- Microsoft introduced two reference concept designs: a Badge Device (portable, Qualcomm wearable silicon, touchscreen, fingerprint sensor, camera, 5G, WiFi, Bluetooth, GNSS) and a Desk Device (stationary, MediaTek IoT silicon, facial recognition, UWB presence sensor, dual microphone array, two USB-C ports, optional Windows 365 client).
- A core technical concept is “just-in-time UI,” where agents dynamically adapt their interface to the device, screen size, and input modality without requiring developers to rebuild the experience for each form factor. Microsoft states that fully generative UI “is not yet here” and the current implementation uses semi-structured approaches such as Adaptive Cards.
- Microsoft confirmed that hundreds of its own employees are already piloting the concept devices internally. Private pilots with AccuWeather, Best Buy, CVS Health, Levi’s, and Target are planned in the coming months. The concept devices are reference designs for OEMs, not products Microsoft intends to ship itself.
My take: Project Solara are AI agents running directly on hardware from Qualcomm (the wearable “Badge Device”), and MediaTek (the “Desk Device”) where both devices operate “just in time” to adapt their interface based on the hardware they run on. The devices run a variation of Android, with main difference being they don’t run apps but run agents directly with processing in the cloud. This is still a very early test prototype platform, but it’s interesting since it challenges the current “device becomes the app” paradigm we have used for 20 years now, instead the device becomes an agent.
Meta Launches Business Agent Across WhatsApp, Messenger, and Instagram
https://about.fb.com/news/2026/06/meta-business-agent/
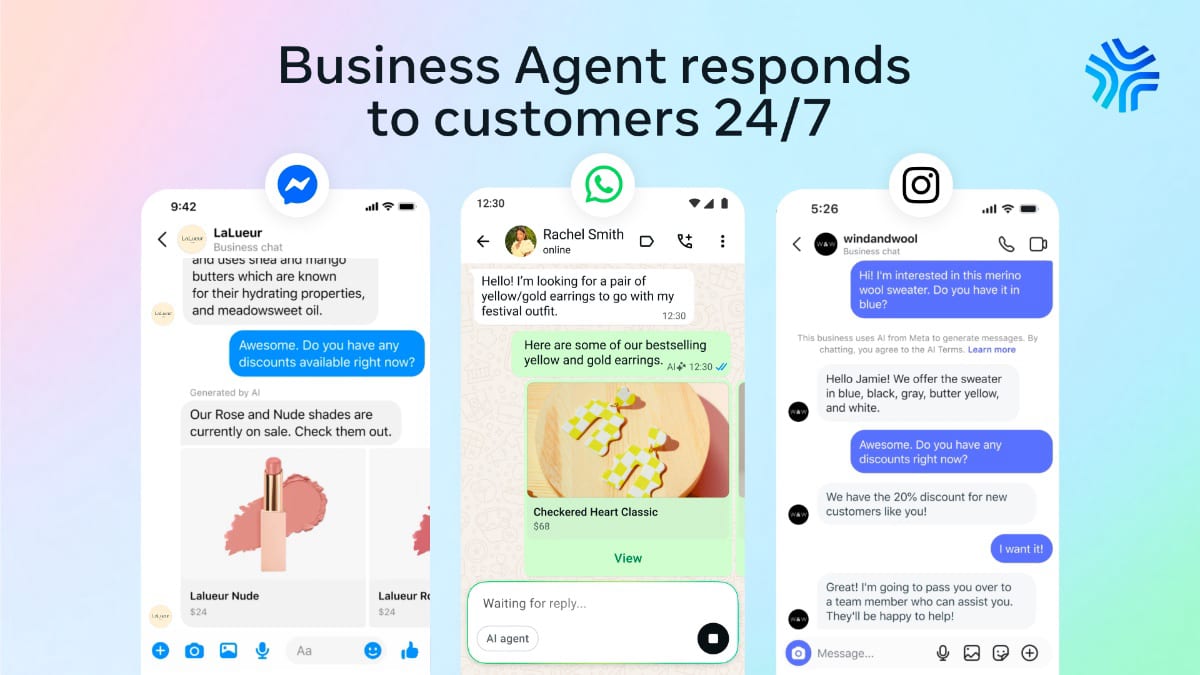
The News:
- Meta Business Agent is an AI customer-service agent announced June 2 at the Conversations 2026 conference in London, now rolling out globally across WhatsApp, Messenger, and Instagram.
- More than 1 million businesses were already running earlier chatbot versions on WhatsApp and Messenger; the new release adds Instagram and agentic capabilities such as booking appointments and closing sales directly in chat threads.
- The agent responds in customers’ local languages using the business’s configured tone, and can answer business-specific questions, recommend products from a catalog, qualify leads, and escalate complex queries to a human agent.
- A “morning briefing” feature summarizes overnight customer conversations for business owners, with a waitlist open for future capabilities including market research, product insights, and competitive intelligence.
- The basic tier is free to activate; paid subscription tiers for businesses of all sizes are planned for the coming months.
- A companion Meta Business Agent Platform connects to hundreds of third-party systems including Shopify, Zendesk, and Shopee, and provides larger businesses with enterprise-grade controls, guardrails, and measurement.
“We actually want to take actions now. We actually want it to be able to complete the payment, to process the booking, to place the order” Naomi Gleit, Head of product.
My take: Meta’s new Business Agent is connected directly into WhatsApp, Messenger and Instagram. This is where your customers are, and Meta owns that space. Meta Business Agent is released for free, with paid subscriptions planned in the coming months. Meta also formed a new internal team called Enterprise Solutions, that will will send squads of forward-deployed engineers to embed with enterprise customers - to navigate internal politics around AI adoption and write custom code to bring the best out of the integrations.
The main challenge with using a “do everything” agentic platform like this, is that it’s typically hard to secure. As an example, just a few days ago hackers used Meta’s AI-powered support chatbot to infiltrate high-profile Instagram accounts. This was later confirmed by Meta.
My recommendation is that whenever possible build your own agentic infrastructure and own the vertical. Build several agents, and limit access to each agent based on user authentication, and always require a human in the loop for confirmation. The timing of announcing the new Business Agent the same week their support bot got hacked to infiltrate the Obama White House Instagram account couldn’t have been worse, but rest assured that it is possible to implement these chatbots the right way.
Read more:
- Hackers trick Meta AI support bot to infiltrate Obama White House Instagram account | Meta | The Guardian
- Meta enters enterprise AI race with new business agent | The Star
NVIDIA Cosmos 3: Open Omnimodal World Foundation Model for Physical AI
https://research.nvidia.com/labs/cosmos-lab/cosmos3/
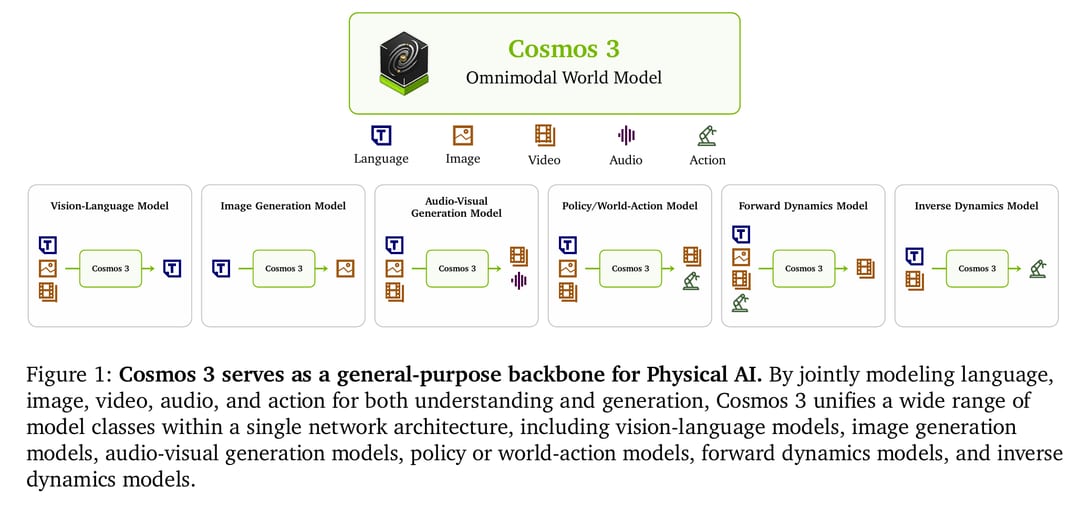
The News:
- NVIDIA released Cosmos 3 on June 1 at GTC Taipei, an open-weight foundation model family for physical AI that processes and generates language, images, video, ambient sound, and robot actions within a single unified architecture. Model weights, code, training scripts, and six synthetic datasets are available on Hugging Face and GitHub under the Linux Foundation’s OpenMDW-1.1 license.
- The architecture uses a dual-tower Mixture-of-Transformers design: an autoregressive “Reasoner” tower for multimodal understanding paired with a diffusion-based “Generator” tower for world state and action prediction. Two model sizes are available now: Cosmos 3 Nano at 16B parameters (8B reasoner + 8B generator) and Cosmos 3 Super at 64B parameters (32B + 32B). A Cosmos 3 Edge variant for real-time local inference is announced but not yet released.
- The model was trained on 20 trillion tokens of multimodal data, including nearly one billion images, 400 million real and synthetic videos, ambient sounds, and human and robot action data. It generates action outputs such as robot joint angles, gripper positions, and movement trajectories, making it applicable to both synthetic training data generation and direct policy model development.
- As of May 28, Cosmos3-Super-Text2Image ranked first among open-weight models on Artificial Analysis’s text-to-image leaderboard, based on blind human aesthetic evaluation. In the combined open and closed model ranking, it placed fourth overall. Cosmos3-Super-Image2Video also ranked first among open models on Artificial Analysis’s image-to-video leaderboard, placing 22nd overall. Among physical AI benchmarks, Cosmos 3 ranks first across Physics-IQ, PAI-Bench, R-Bench, RoboLab, RoboArena, VANTAGE-Bench, and TAR.
- NVIDIA simultaneously launched the Cosmos Coalition, a partner consortium that includes Agile Robots, Black Forest Labs, LTX, Runway, and Skild AI, with the stated aim of advancing open world models for physical AI deployment.
My take: Before Cosmos 3 you had three different products from NVIDIA that handled separate parts of the pipeline: Cosmos Predict 2.5, Cosmos Reason 2 and Cosmos Transfer 2.5. Cosmos 3 consolidates these into one single model that unifies text, image, video, ambient sound, and action. NVIDIA has released everything in Cosmos 3 to the public, including weights, code, datasets, and fine-tuning recipes. The two fine-tunes Cosmos3-Super-Text2Image and Cosmos3-Super-Image2Video rank first among open-weight models on the Artificial Analysis text-to-image and image-to-video leaderboards, placing them just below Nano Banana 2 in the combined open and closed rankings.
So, what do you use it for? Cosmos 3 is a physical AI world model, not a language assistant. It generates synthetic video, simulates physics, and outputs robot actions (joint angles, trajectories, gripper positions). Use it to build robotic systems, autonomous vehicles, or industrial vision solutions. It can generate large amounts of synthetic data, and it has most of the features needed to build the next big robotics model.
Perplexity Releases Search as Code for AI Agents
https://research.perplexity.ai/articles/rethinking-search-as-code-generation

The News:
- Perplexity has released Search as Code (SaC), a search architecture for AI agents that generates Python code to call Perplexity’s search infrastructure directly, rather than issuing serial function calls or MCP invocations one at a time.
- Instead of a monolithic search endpoint, SaC exposes an Agentic Search SDK of composable primitives covering retrieval, ranking, filtering, fanouts, and rendering, which model-generated code assembles into task-specific pipelines.
- Agents can execute hundreds or thousands of parallel search operations within a single inference turn using secure compute sandboxes, with intermediate state managed via filesystem-based serialization across turns rather than through token-space state.
- In a CVE advisory case study covering 200+ high-severity vulnerabilities from 2023-2025, SaC scored 100% accuracy while reducing token usage by 85.1%, from 288.7K tokens to 42.9K tokens, versus a non-SaC baseline.
- On the WANDR benchmark, a new wide-research evaluation covering complex multi-step tasks, SaC outperforms the next-best system by a factor of 2.5x. Compared to non-SaC Perplexity search, SaC adds +19.77 percentage points on DSQA (29% relative gain) and +12 percentage points on WANDR (45% relative gain).
- The Agentic Search SDK is optimized continuously through an autoresearch loop that proposes and validates SDK structure changes against metrics including latency, codegen quality, and task performance.
My take: When an AI agent needs to search the web today it makes individual tool calls, one at a time, waiting for each result before deciding what to search next. Perplexity’s new Search as Code (SaC) changes this. Instead of calling a search tool repeatedly, the agent writes a short Python script on the fly, and that script runs inside a secure sandbox and handles all the retrieval, filtering, ranking, and fanout logic in one go. The CVE benchmark showed 85% fewer tokens versus serial tool calls, from 288.7K down to 42.9K.
If this had come from any other company than Perplexity I would be raving about it, but for now I am extremely cautious of recommending Perplexity for anything at all. If you don’t know what I am talking about here, go check my previous newsletter and search for Perplexity. But I do believe this way of working where agents create code runtime to solve tasks is the future, and I can see it coming to almost any type of software in the coming years.
Read more:
OpenAI Expands Codex With Role-Specific Plugins, Sites, and Annotations
https://openai.com/index/codex-for-every-role-tool-workflow/
The News:
- OpenAI expanded Codex on June 2 with six role-specific plugins, a hosted Sites feature, and document-level annotations, targeting non-developer knowledge workers who now represent about 20% of Codex’s 5 million weekly active users and are growing more than 3x faster than developers.
- The six plugins cover data analytics, creative production, sales, product design, public equity investing, and investment banking, collectively bundling 62 apps and 110 skills across tools such as Snowflake, Databricks Genie, Tableau, Figma, Canva, Salesforce, HubSpot, Moody’s, FactSet, and PitchBook.
- Sites, currently in preview for Business and Enterprise plans, lets Codex generate and host interactive dashboards, project boards, scenario planners, and lightweight apps sharable via URL within a workspace; OpenAI is working with partners including Vercel, Wix, Replit, Lovable, Figma, Webflow, and Emergent toward a broader Sites ecosystem.
- Annotations now extend beyond code and Markdown to documents, spreadsheets, and slides, letting users select a specific element and ask Codex to modify only that part without regenerating the full output.
- Additional plugins for Corporate Finance, Private Equity Investing, Marketing Strategy, Strategy Consulting, and Legal are announced as upcoming, alongside a planned open partner ecosystem for custom plugins in both Codex and ChatGPT.
My take: Codex is quickly becoming OpenAI’s “do-it-all” platform and with these new role-specific plugins you can do almost everything with it. Think Claude Cowork but with specialized skills for almost any purpose. I believe that within 1-2 years time the best AI models will be able to perform almost any task at the computer a user can do, with the proper interface. OpenAI Codex is one such interface, and for many it will be THE interface used for almost everything at their computer within a year or so.
ChatGPT Memory Gets a Dreaming Upgrade
https://openai.com/index/chatgpt-memory-dreaming/
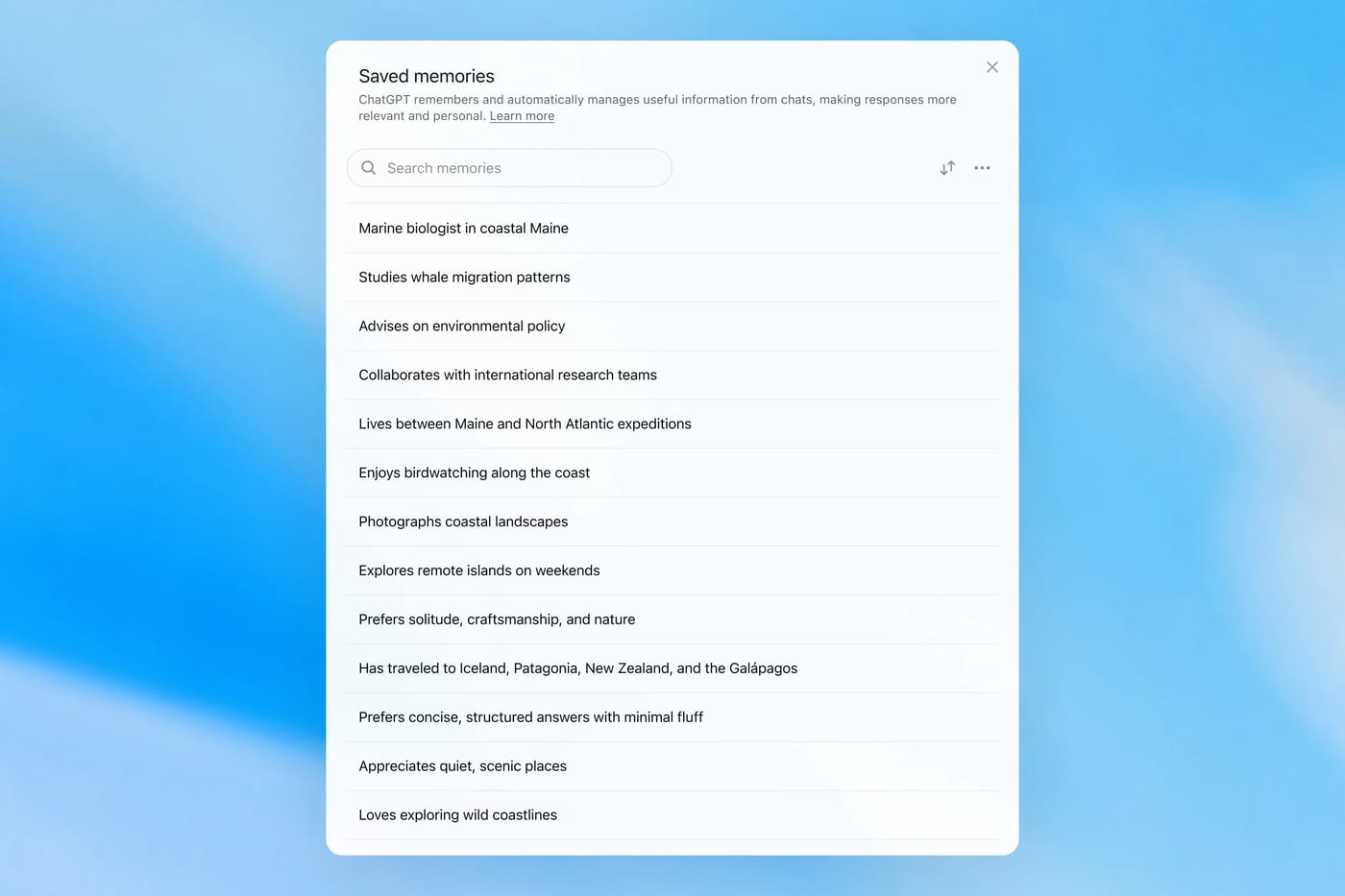
The News:
- OpenAI rolled out Dreaming V3 on June 4, a background memory architecture for ChatGPT that automatically synthesizes and updates what the model knows about users across conversations, without requiring explicit instructions.
- The system runs as an offline consolidation process after conversations end, scanning transcripts for context such as camera gear, travel plans, or dietary preferences, and folds this into a unified user profile.
- Factual recall accuracy in OpenAI’s internal benchmarks rose from 41.5% (2024 saved memories system) to 82.8% with Dreaming V3; preference-following accuracy reached 71.3%, and temporal state accuracy, correctly reflecting that a past trip is over for example, reached 75.1%.
- The system actively manages temporal context: if a user stored “I’m going to Singapore in July” and the trip ends, Dreaming V3 updates that memory to reflect the past tense, so future responses default back to the user’s home location and time zone.
- A new Memory Summary page under Settings lets users review a structured breakdown of what ChatGPT has stored, add or update information, and specify what topics ChatGPT should bring up and when.
- The rollout starts with Plus and Pro users in the US. Recent improvements reduced the compute cost to serve dreaming to Free users by approximately 5x, making it possible to extend the feature to Free and Go users globally over the coming weeks.
My take: This new dreaming system in ChatGPT does three things right: first, a synthesized profile requires much less space than the raw conversation history, means it’s much more context efficient. The bonus side effect is accuracy and freshness of the memories, where information such as travel plans are automatically pruned once the trip is finished. The potential drawback with this is that the AI will only remember the things it believes it will have use for in the future, which in turn might limit the creativity and future response of the model compared to the previous dreaming system that kept all the unprocessed details.