
For a long time, paying for enterprise software was simple. You bought a seat license, and a human sat in that seat and used the software. Last week that model started to break down as we are shifting from predictable software licenses to metered digital labor.
On June 16, Microsoft made Copilot Cowork generally available worldwide. It is an AI agent built to handle complex background tasks. The biggest change is the billing. While you still need a base user subscription, Copilot Cowork bills by usage in Copilot Credits. You pay $0.01 per credit based on model use, context retrieval, tool calls, and runtime.
This shift to token-based usage is spreading far beyond software development. Sakana AI just launched an autonomous business research assistant called Sakana Marlin. You give it a direction, and it runs on its own for up to eight hours to generate a detailed strategy report of up to 100 pages. Just like Microsoft, it uses a pay-as-you-go credit model for every run.
Suddenly, we have autonomous agents acting on our authenticated data, spending company budget token by token while our laptops are closed. As developers noted in a Hacker News discussion, letting agents loose inside your Microsoft 365 environment creates real issues for permissions and auditability.
Google DeepMind faced this exact problem. On June 18, they published their AI Control Roadmap, which treats AI agents as partially trusted insiders. After analyzing a million agent tasks, DeepMind found most errors were not malicious. They were just agents misinterpreting instructions or being too eager to help, leading to issues like unintentional data deletion in real time.
If you are deploying autonomous agents, you are basically onboarding new employees. If you want to get started with Copilot Cowork then start with a small pilot group so you can measure the actual token costs. Set up live monitoring, manage their permissions carefully, and build incident response procedures for these agents exactly like you would for a human worker. And build from there.
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2026 Week 26 on Spotify
Notable model releases last week:
- GLM-5.2 by Z.ai. Open model with 1M-token context for long coding agents and complex software tasks.
THIS WEEK’S NEWS:
- Midjourney Unveils Ultrasonic Body Scanner and Spa
- Microsoft Makes Copilot Cowork Generally Available Worldwide
- Google DeepMind Publishes AI Control Roadmap
- OpenRouter Fusion Tops Solo Models on DRACO
- Anthropic Finds Domain Expertise Drives Claude Code Success
- Google Shuts Down Gemini CLI and Code Assist for Consumers
- Sakana AI Launches Marlin, Its First Commercial Product
- SpaceX Moves Forward With $60 Billion Cursor Acquisition
- DeepSeek Raises $7.4 Billion in First Outside Round
- FastContext 1.0 Cuts Main-Agent Tokens by Up to 60%
- Perplexity Launches Brain: Self-Improving Memory for Computer
- Meta Launches Facebook AI Mode From Public Posts
Midjourney Unveils Ultrasonic Body Scanner and Spa
https://www.midjourney.com/medical/blogpost

The News:
- Midjourney published Midjourney Medical, a plan for a full-body ultrasonic CT scanner and spa service.
- The scanner design lowers a person through water past half a million sand-grain-sized elements, with a stated whole-body scan goal of 60 seconds.
- Those elements generate terabytes of data each second, which a massive cluster of thousands of computers uses to reconstruct sub-millimeter 3D body maps.
- The first Midjourney Spa is planned for San Francisco in 2027, starting with detailed body composition maps while Midjourney submits regular test results to the FDA for increased capabilities.
- The roadmap targets more cities and a third-generation custom-silicon scanner in 2028, with an ambitious goal of over 50,000 scanners worldwide by 2031.
My take: The Midjourney Medical project is pitching consumer medical-imaging infrastructure, but right now this is a roadmap rather than a finished diagnostic product. As Paul Smith on LinkedIn pointed out, it’s surprising to see an AI image company choose physical healthcare hardware instead of the expected headset or gadget. Their stated goal of completing a whole-body scan in 60 seconds to reconstruct 3D body maps sounds amazing. But the supplied evidence doesn’t include a technical paper or independent demo validating that target. I would wait for actual proof before taking these hardware claims as seriously as their software.
Read more:
Microsoft Makes Copilot Cowork Generally Available Worldwide

The News:
- On June 16, Microsoft made Copilot Cowork generally available worldwide for Microsoft 365 Copilot customers.
- It is built for complex, long-running, multi-tool tasks and runs end-to-end in the cloud.
- Use requires the Microsoft 365 Copilot User Subscription License, and Cowork bills by usage in Copilot Credits based on model use, context retrieval, tool calls, and runtime.
- PayGo is priced at $0.01 per Copilot Credit, and admins can leave Cowork off by default or cap spend by tenant, group, and user.
- At launch it runs on Anthropic Opus 4.8 and Sonnet 4.6, with Microsoft’s lower-cost Cowork 1 due in the coming weeks.
My take: Copilot Cowork changes how we pay for AI at work. We’re moving from predictable seat licenses to metered cloud labor. You still need the base subscription, but complex background tasks now add usage-based billing in Copilot Credits. Because these agents act on your authenticated data while your laptop is off, security and budget are a real concern. As developers noted in a Hacker News discussion, autonomous agents inside Microsoft 365 make permissions and auditability a practical rollout challenge. Cowork is turned off by default at launch and I recommend leaving it off for your broader organization. Enable it for a small pilot group first so you can measure the actual costs and verify your approval flows before expanding.
Read more:
Google DeepMind Publishes AI Control Roadmap
https://deepmind.google/blog/securing-the-future-of-ai-agents

The News:
- On June 18, Google DeepMind published the AI Control Roadmap, a framework for managing advanced AI deployed within Google with defense-in-depth safeguards even if alignment is imperfect.
- The roadmap treats untrusted agents as insider threats and builds on MITRE ATT&CK to break attacks into tactics and techniques.
- Monitoring and response are meant to scale with model capability, from delayed review for low-risk actions to real-time blocking for high-risk ones such as major cyber attacks.
- DeepMind says it has analyzed 1 million coding agent tasks, and that work informed a live monitor for Gemini Spark to catch issues like unintentional data deletion in real time.
- Most flagged events came from agent misinterpretation or overeagerness, not adversarial intent.
My take: DeepMind treating powerful AI agents as partially trusted insiders instead of perfectly obedient software is exactly the right move. Since most flagged events come from agents simply misinterpreting instructions or being too eager rather than acting maliciously, we have to rethink agent security. It’s an organizational control problem now. Adding system-level safeguards on top of model alignment means your near-term safety burden is going to be reliability and workflow design. If you are deploying autonomous agents, you need to manage their permissions, set up live monitoring, and build incident response procedures just like you would for a regular human employee.
Read more:
- AI Control Roadmap
- Google DeepMind unveils a plan to protect itself from its own rogue AI agents
- Taking a responsible path to AGI – Google DeepMind
OpenRouter Fusion Tops Solo Models on DRACO
https://openrouter.ai/blog/announcements/fusion-beats-frontier
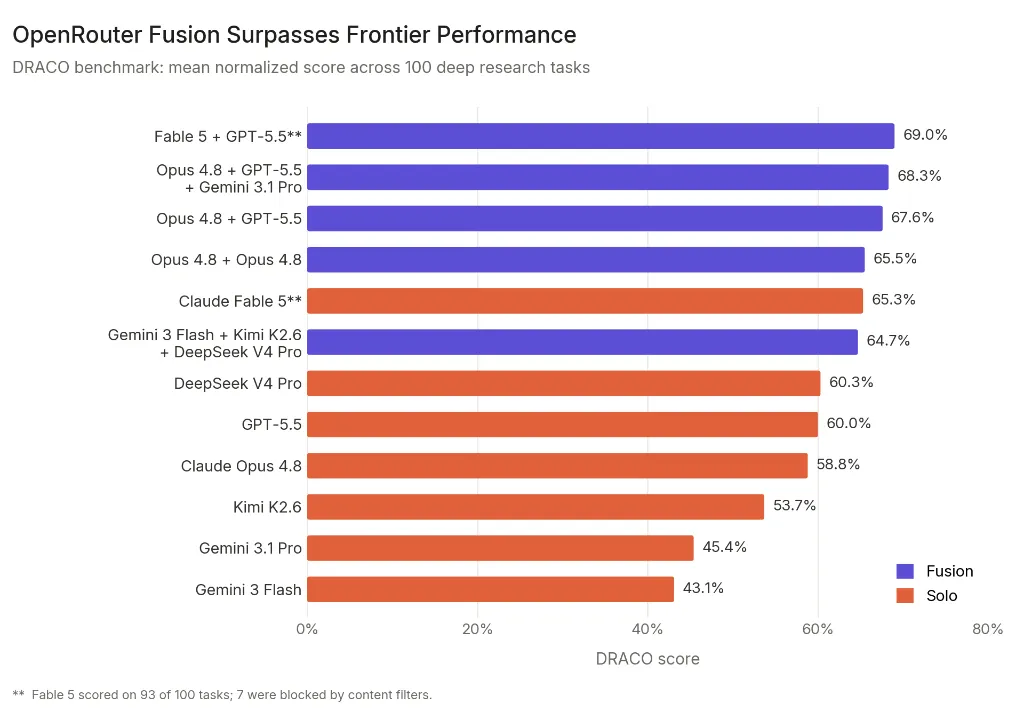
The News:
- OpenRouter published Fusion, a server-side API flow that sends a prompt to multiple models in parallel, has a judge compare the responses, and returns one fused answer.
- On 100 DRACO tasks, Fable 5 + GPT-5.5 scored 69.0%, above Fable 5’s 65.3%, though Fable’s result covers only 93 tasks because 7 were blocked by content filters.
- A budget panel of Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro scored 64.7%, ahead of GPT-5.5 at 60.0% and Claude Opus 4.8 at 58.8%, and within 1% of Fable 5 at 50% of the cost.
- Opus 4.8 fused with itself reached 65.5%, up from 58.8% solo, suggesting part of the gain comes from synthesis rather than model diversity alone.
- Developers can call
openrouter/fusiondirectly or exposeopenrouter:fusionas a server tool, and when Fusion runs its multi-step path is often 2-3x longer than a standard call.
My take: OpenRouter’s Fusion is a smart orchestration layer, not a new single-model champion. A prompt goes to several models in parallel, a judge produces a structured analysis of their answers, and the calling model writes the final response. The main enterprise value is cost control. A budget panel of three cheaper models scored 64.7% on the DRACO benchmark. That beats GPT-5.5’s benchmark result and comes within 1% of Fable 5 (which only completed 93 of 100 tasks) at 50% of the cost. Because latency is often 2-3x longer when Fusion runs, don’t route everything through it. Just expose it as a server tool so your calling model can decide when and if to use it for deep research that justifies the extra wait.
Read more:
Anthropic Finds Domain Expertise Drives Claude Code Success
https://www.anthropic.com/research/claude-code-expertise
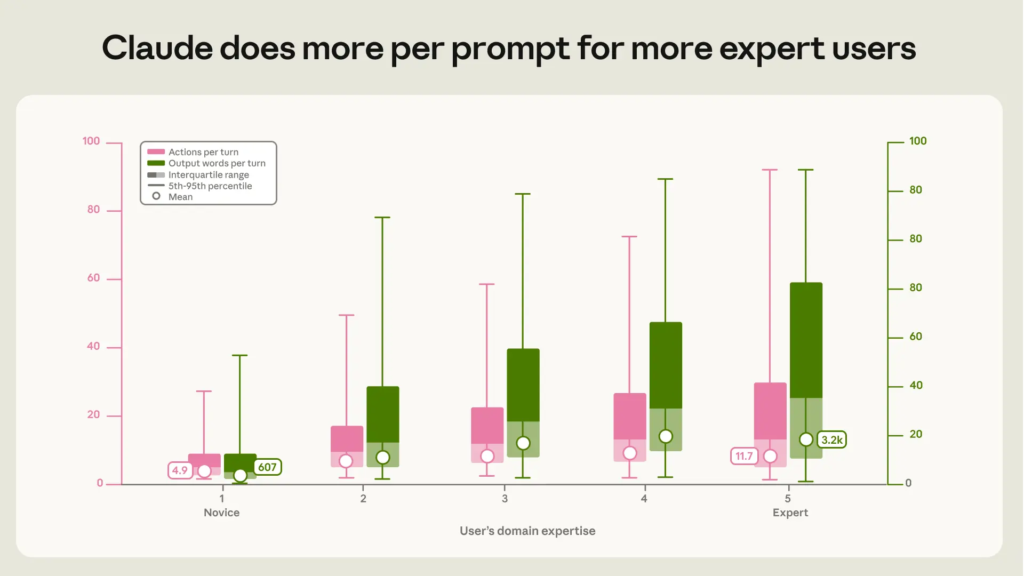
The News:
- On June 16, Anthropic published a study of about 400,000 Claude Code sessions from about 235,000 people between October 2025 and April 2026.
- By Anthropic’s verified-success measure, novice-rated sessions succeeded 15% of the time versus 28% to 33% for intermediate-or-higher sessions.
- In code-producing sessions, software-related occupations reached 34% verified success versus 29% for other professions.
- A typical session had users making about 70% of planning decisions while Claude made about 80% of execution decisions.
- Each prompt in expert-rated sessions set off about 12 Claude actions and 3,200 words of output, versus about five actions and 600 words in novice sessions.
My take: Agentic coding doesn’t replace expertise, it just changes which expertise matters most. In these Claude Code interactive sessions, domain expertise was more closely linked to success than your specific job title. Non-novice users succeeded much more often than novices, but software-related occupations only beat other professions 34% to 29%. Some commenters on Hacker News argued that Anthropic’s examples blur domain knowledge with senior technical system design. I think that is exactly the point. Users still make 70% of the planning decisions while Claude handles 80% of the execution. If you are rolling out agentic AI for your teams, focus your training on system architecture and task planning. The models execute the code, but you still need experienced people who know exactly what to build.
Read more:
- Agentic coding and persistent returns to expertise | Hacker News
- Coding agents in the social sciences
Google Shuts Down Gemini CLI and Code Assist for Consumers
https://9to5google.com/2026/06/17/gemini-cli-code-assist-shutting-down/
The News:
- On June 18, Google ended Gemini CLI and Gemini Code Assist IDE access for free individual users and Google AI Pro and Ultra subscribers as it shifted consumer coding tools to Antigravity CLI.
- Organizations using Gemini CLI or IDE extensions through Gemini Code Assist Standard or Enterprise licenses keep access unchanged, and Gemini CLI still works with paid Gemini API keys.
- Gemini Code Assist for GitHub was deprecated for consumer accounts on June 18 and is set to shut down fully on July 17.
- Google positions Antigravity CLI as the replacement, with multiple asynchronous workflows and a shared backend with the Antigravity 2.0 desktop app.
- It does not have 1:1 feature parity at launch, though Google says it keeps Agent Skills, Hooks, Subagents, and Extensions.
My take: Google is consolidating its consumer coding tools around Antigravity CLI, but they’re cutting off existing Gemini workflows before the replacement is ready. If you access Gemini Code Assist for individuals free of charge, or pay for Google AI Pro and Ultra, your terminal and IDE access just stopped. Organizations with Standard or Enterprise licenses and users with paid API keys remain unaffected. The technical rationale makes sense. Developers need multiple asynchronous workflows and a unified backend, not isolated terminal tools. Still, the transition is rough when Google admits Antigravity lacks “1:1 feature parity right out of the gate”.
Read more:
- An important update: Transitioning Gemini CLI to Antigravity CLI
- Sunset of the Consumer version of Gemini Code Assist on GitHub
Sakana AI Launches Marlin, Its First Commercial Product
https://sakana.ai/marlin-release/#English

The News:
- On June 15, Sakana AI launched Sakana Marlin, its first commercial product, an autonomous research assistant for business.
- After a brief user exchange to set direction, it runs without further human input for up to roughly eight hours and returns executive summary slides plus a detailed strategy report up to 100 pages long.
- Sakana says Marlin brings together its long-horizon reasoning work, including AB-MCTS and The AI Scientist.
- A closed beta that began in April involved around 300 professionals from financial institutions, operating companies, consulting firms, and think tanks.
- Pay-as-you-go is 100 credits per run at ¥98 per credit, while Pro and Team cost ¥150,000 and ¥400,000 a month.
My take: Sakana Marlin turns long-horizon reasoning research into a paid business workflow. Instead of standard chat-style prompting, you set a topic, have a brief exchange, and let this autonomous research assistant run without human input for up to eight hours. It packages their AB-MCTS and The AI Scientist work to produce executive slides and a detailed strategy report of up to 100 pages for professionals across finance, consulting, think tanks, and operating companies. The pay-as-you-go model of 100 credits per run at ¥98 per credit ($0.68) sets a clear price anchor for delegated strategy work. But as Trevin on X pointed out, this category lives or dies on whether these reports are decision-useful, not just long. It’s easy to generate massive documents today, making structure and usefulness the only real value tests.
Read more:
SpaceX Moves Forward With $60 Billion Cursor Acquisition
https://apnews.com/article/spacex-cursor-acquisition-vibe-coding-a5c60fcbaaca262cf107d30f1de899ef

The News:
- SpaceX moved forward with its $60 billion acquisition of Cursor after its Wall Street debut last week.
- In April, SpaceX said it had the right to buy Cursor or pay $10 billion to “work together” with the company.
- A regulatory filing says Cursor will become a wholly owned subsidiary when the deal closes in the third quarter.
- Cursor previously said its partnership with SpaceX subsidiary xAI would let it build future AI products using Colossus in Memphis, Tennessee.
- Cursor, made by Anysphere, competes with Anthropic’s Claude Code and OpenAI’s Codex and has relied on those larger labs for the foundations of its technology.
My take: SpaceX is using a $60 billion pending acquisition to buy direct distribution to expert software engineers. Cursor, made by the startup Anysphere, controls the developer workflow that sits right next to code, debugging patterns, and enterprise software teams. As developers noted in the linked Hacker News thread, Cursor is praised for this product harness, and users are already speculating about future Grok integration. But a SpaceX-controlled Cursor creates a strange platform tension. It will sit inside xAI’s rival ecosystem while still heavily relying on model foundations from the companies it is trying to beat. Cursor competes directly with Anthropic’s Claude Code and OpenAI’s Codex, yet it depends on those same frontier labs to actually work.
Read more:
- SpaceX is working with Cursor and has an option to buy the startup for $60 billion
- So SpaceX bought a $60B Option on Cursor, plus a bunch of …
DeepSeek Raises $7.4 Billion in First Outside Round
https://www.forbes.com/sites/anishasircar/2026/06/17/deepseek-just-raised-74-billion-heres-the-catch
The News:
- On June 17, Forbes reported that DeepSeek had raised more than 50 billion yuan, about $7.4 billion, in its first outside round at a valuation above $50 billion.
- Until now, founder Liang Wenfeng had funded the lab through profits from High-Flyer.
- Investor capital reportedly went into a Liang-controlled limited partnership rather than direct equity, with zero voting rights and a five-year lock-up.
- The only reported exception was China’s National Artificial Intelligence Industry Investment Fund, which Forbes says invested directly and got voting rights without a lock-up.
- The raise made DeepSeek China’s most valuable AI startup, though Forbes still places it far below Anthropic at $965 billion and OpenAI at $852 billion.
My take: DeepSeek taking outside money is a major shift, but their new control structure matters far more than the valuation. Forbes reports that most ordinary investors are locked in for five years with zero voting rights. That gives founder Liang Wenfeng complete freedom to fund long-term AI infrastructure. But the exception is what you should watch. China’s state AI fund supposedly invested directly and secured voting rights. DeepSeek hasn’t publicly commented on these terms yet, but if this is accurate, the special treatment will make Western data and governance scrutiny much harder to dismiss. This doesn’t change how their chatbot works for you today. It just shows how the state plans to stay close to their most valuable AI startup.
Read more:
- DeepSeek Closes Record $7 Billion-Plus Funding with Unusual Deal Structure
- DeepSeek Becomes China’s Most Valuable AI Startup After Over $7.4 Billion Fundraise
FastContext 1.0 Cuts Main-Agent Tokens by Up to 60%
https://huggingface.co/microsoft/FastContext-1.0-4B-SFT
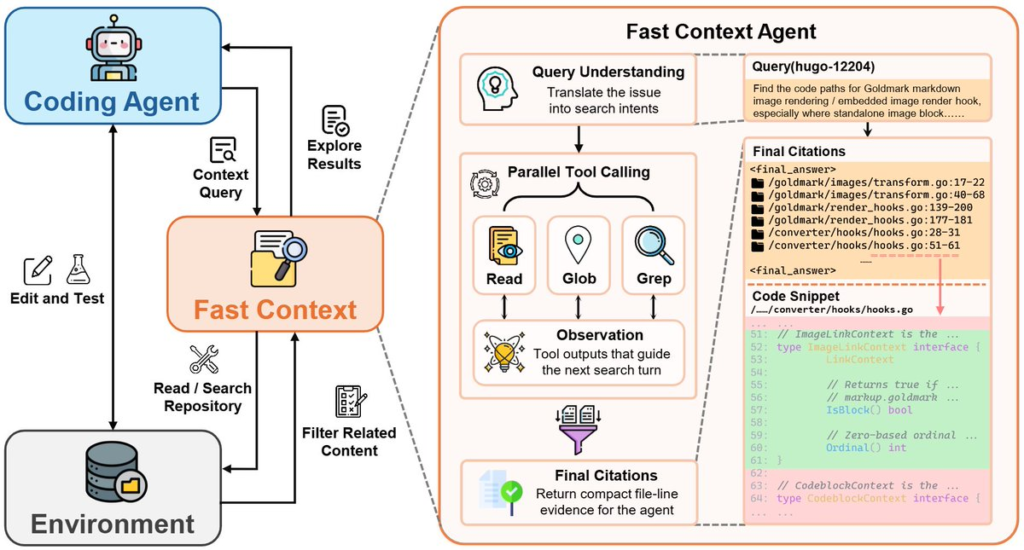
The News:
- Microsoft published FastContext 1.0 as a lightweight repository-exploration subagent for LLM coding agents.
- A main coding agent invokes it on demand, and FastContext uses parallel READ, GLOB, and GREP calls to return compact file paths and line ranges.
- In Microsoft’s GPT-5.4 trajectory analysis, reading and searching accounted for 56.2% of tool-use turns and 46.5% of main-agent tokens.
- In Mini-SWE-Agent tests, FastContext improved end-to-end resolution rates by up to 5.5% while reducing main-agent token consumption by up to 60%.
- The family spans 4B to 30B parameters, supports up to 262K tokens of context, and is MIT-licensed.
My take: FastContext is less a new coding assistant than a bet that agent architecture should split repository exploration from problem solving. Right now, main agents waste a lot of context just exploring the repository. By offloading that work to a specialized subagent, the main model receives compact file paths and line ranges instead of carrying a long trail of exploratory reads. Microsoft notes this cuts main-agent token consumption by up to 60%, but keep in mind this measures solver-context efficiency, since it excludes the subagent’s own internal model calls. You don’t just install this as an end-user app. If your team is already wiring LLMs into custom coding-agent frameworks, this is the architecture shift you should explore to keep your main agent focused on writing code.
Read more:
- GitHub – microsoft/fastcontext: FastContext: Training Efficient Repository Explorer for Coding Agents
- FastContext: Training Efficient Repository Explorer for Coding Agents
Perplexity Launches Brain: Self-Improving Memory for Computer
https://www.perplexity.ai/hub/blog/self-improving-memory-for-agents
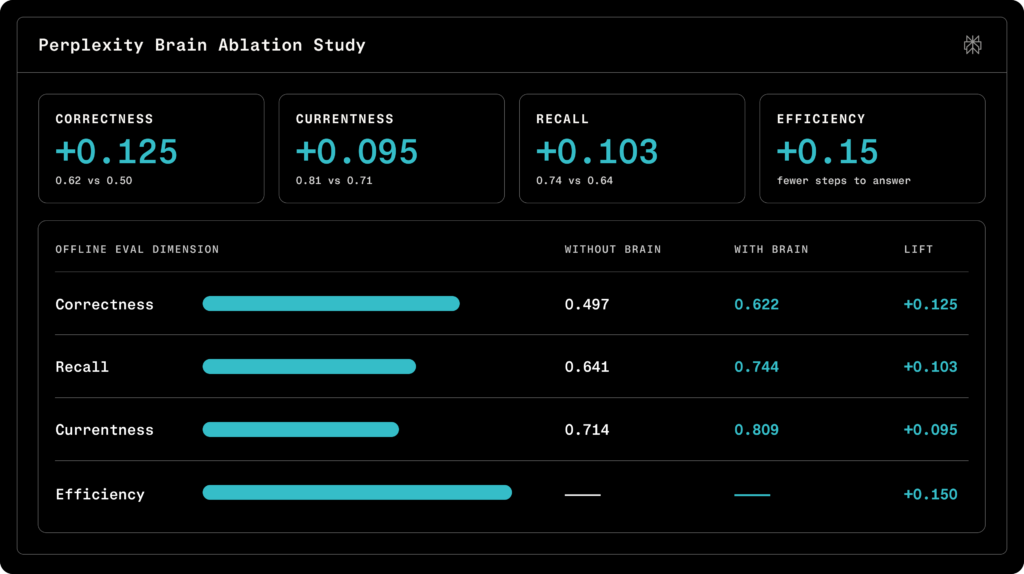
The News:
- Perplexity launched Brain, a self-improving memory system that builds a context graph of the work Computer performs.
- It centers memory on the agent’s work history, including what worked, what failed, and what corrections were made.
- At set intervals such as overnight, Brain synthesizes sessions, connector results, document changes, and corrections into an LLM wiki loaded onto the agent sandbox.
- Perplexity says early measurements show 25% higher answer correctness on tasks Computer has seen before, 16% higher recall, and 13% lower cost for tasks that require historical context.
- Brain is rolling out in Research Preview to Max and Enterprise Max subscribers.
My take: Perplexity Brain is a practical bet that work memory, not personality, is the next real differentiator for AI agents. Vellum previously pointed out that Perplexity Computer lacked persistent memory across sessions. Brain fixes this by shifting memory toward the agent’s actual work history. While the marketing hints at recursive self-improvement, it’s really a periodic update. Brain synthesizes past sessions overnight into an LLM wiki, giving the agent a better starting point for each new task without retraining the underlying model. The enterprise angle is strong, but the governance controls are completely missing. We don’t know the rules for data ownership, lifecycles, or how admins delete these generated wikis. Test it in the preview, but wait for clear admin controls before trusting it with sensitive enterprise work.
Read more:
- Perplexity Brain Adds Self-Improving Work Memory to Its Agent
- 10 Best Perplexity Computer Alternatives in 2026
Meta Launches Facebook AI Mode From Public Posts
https://www.androidheadlines.com/2026/06/facebook-ai-mode-search-engine-public-posts.html
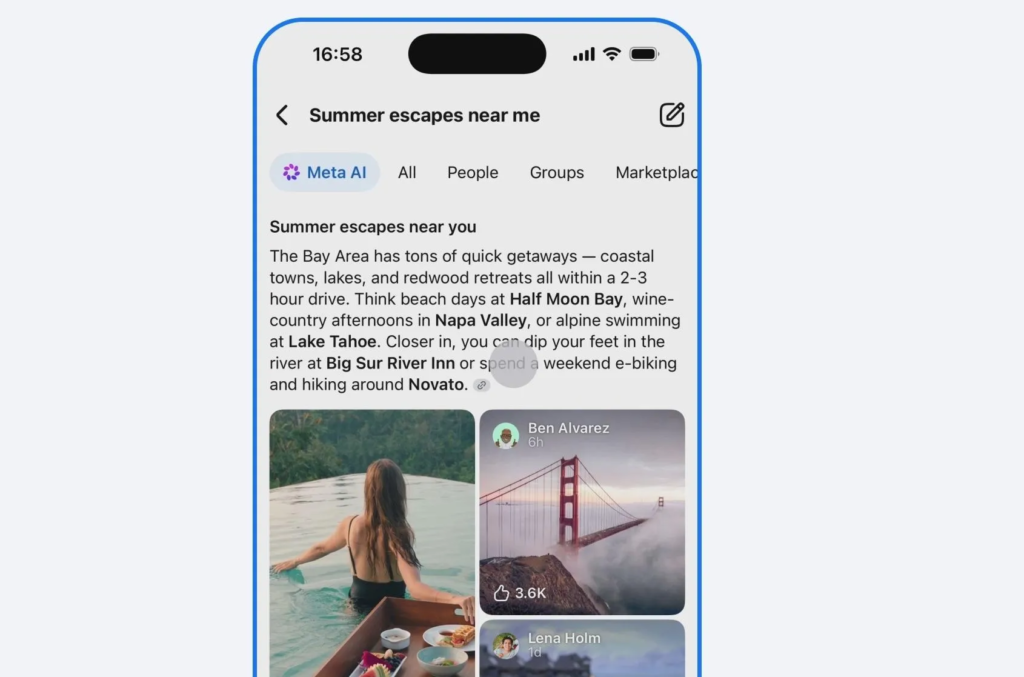
The News:
- On June 15, Meta launched Facebook AI Mode in the US, adding AI answers to Facebook search.
- Queries now return plain-language answers instead of link lists, using public content from Groups, Reels, and Marketplace.
- The tool can surface local Group discussions, active Marketplace listings, and clips from existing Reels.
- Because it summarizes everyday user posts rather than verified databases, answers may include outdated or unverified advice.
- Meta also recently launched Facebook and Instagram Plus memberships from $3.99 a month, and TechCrunch reports more AI-related tiers are on the way.
My take: Meta isn’t just adding AI to Facebook search. They are turning public social chatter into an answer layer by generating AI answers directly from public content. Getting plain-language summaries instead of feed scrolling is incredibly useful for discovery – Facebook Groups are full of practical local recommendations and niche troubleshooting that ordinary search engines often miss. The catch is reliability. Because the tool summarizes everyday user posts rather than verified databases, there’s a potential risk that the AI will surface outdated information or unverified advice. If you’re looking for an active Marketplace listing or local tips, this is a great update. Just be careful not to treat social summaries as verified facts.
Read more: