W48 · 2025 — November 24, 2025
Tech Insights 2025 Week 48.

Last week Google finally launched their long-awaited model Gemini 3 Pro, together with the outstanding new Nano Banana Pro “image processor”. I’m not even sure what I should call Nano Banana Pro, it can do things with images I didn’t think was possible, and looking at the things it can produce it really gives you a somewhat uncomfortable feeling, like “if AI can do all this now, what else can it do in 6-12 months?”. I’ve had this feeling for AI programming the past 3-6 months, but now that feeling is rapidly spreading into other domains. Nano Banana Pro is no longer a prompt-based image generator, it’s something completely different. It does most things in seconds that would have required a seasoned and highly skilled art director hours or days to do, and it clearly shows how competent and complex today’s AI models have become.
What’s even more impressive with Google’s launch last week is that they pre-trained all their models on TPUs, not GPUs. Not a single NVIDIA chip in sight. That said, NVIDIA is selling like hotcakes, and NVIDIA’s upcoming Blackwell series is already sold out. But owning the hardware and the software stack together gives Google unique competitive advantages. Compare this to Microsoft who right now needs to buy NVIDIA chips to run models owned by other companies like Anthropic and OpenAI, there’s no way Microsoft will be able to compete with Google on price with that setup. The only way to stay competitive in this race is to own the vertical, and Google just showed everyone else that it’s possible. Apple? I believe it’s time for a management change in that company and pretty quickly too.
“How can we best train our staff so we can develop our own multi-agent solutions in our company?” I get that question quite a lot. There are two main challenges with this: the first one is that you need to spend quite a lot of time learning and working with agentic AI to get the skills needed to build and deploy solutions in production systems. And that takes months. The second thing is that things are moving so quickly so if you have a course agenda you would need to constantly revise the content during the course to make sure it’s up to date and relevant.
I searched a lot but couldn’t find any course like this, so we decided to make it ourselves. Last week at TokenTek we launched our very own AI Engineer program together with Hubbau. It’s a 12 month course, aimed at newly graduated M.Sc. young engineers paired with company mentors with deep domain skills. After this program has finished, companies will have employees with deep skills in generative AI such as multi-agent systems, custom transformer models, local models, cloud deployments, cost optimizations, AI act details, and much more. Everything you need to build and scale your own advanced AI solutions as the backbone for your organization.
We have presented it for a few select companies, and the first one to sign up for it is Coretura, a joint-venture startup company owned by Volvo Group and Daimler. They launched their program last week and it will start in February 2026. If you plan to launch a young talent program at your company next year then please feel free to reach out to me if you want to know more. There is a limit to the number of programs we can hold every year and interest is high.
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2025 Week 48 on Spotify
THIS WEEK’S NEWS:
- Google Releases Gemini 3, Claims Top Spot on AI Leaderboards
- Google Releases Gemini 3 Pro Image (Nano Banana Pro) with Text Rendering and Multi-Character Support
- Google Releases WeatherNext 2 AI Weather Forecasting Model
- OpenAI Releases GPT-5.1-Codex-Max for Long-Running Coding Tasks
- OpenAI Upgrades ChatGPT Pro with GPT 5.1 Pro
- ChatGPT Launches Group Chats for Up to 20 Users
- xAI Launches Grok 4.1 with Improved Emotional Intelligence and Reduced Hallucinations
- Microsoft, NVIDIA, and Anthropic Announce Strategic Partnerships
- Meta Segment Anything Model 3 Adds Text Prompts and Video Tracking
- NVIDIA Introduces Apollo Open Models for AI Physics Simulation
- Klay Becomes First AI Company to License Music from All Three Major Labels
Google Releases Gemini 3, Claims Top Spot on AI Leaderboards
https://blog.google/products/gemini/gemini-3/

The News:
- Google launched Gemini 3 Pro, a multimodal AI model that scores 1,501 Elo on the LMArena Leaderboard and 1,487 Elo on WebDev Arena. The model is available in the Gemini app, AI Studio, Vertex AI, and third-party platforms including Cursor, GitHub, JetBrains, Replit, and Manus.
- The model achieves 91.9 percent on GPQA Diamond, 81 percent on MMMU-Pro, 76.2 percent on SWE-bench Verified, and 37.5 percent on Humanity’s Last Exam without tools. On MathArena Apex, it scores 23.4 percent, while pure reasoning on AIME 2025 reaches 95 percent without code execution.
- Gemini 3 Deep Think mode achieves 93.8 percent on GPQA Diamond, 41.0 percent on Humanity’s Last Exam, and 45.1 percent on ARC-AGI-2 with code execution. The enhanced reasoning mode will roll out to Google AI Ultra subscribers following additional safety testing.
- Google also introduced Google Antigravity, an agentic development platform where AI agents receive direct access to the editor, terminal, and browser. Agents can autonomously plan and execute software tasks while validating their own code.
My take: Let’s start with Gemini 3 Pro. Gemini 3 Pro is the first model to be fully trained on custom TPUs, and not a single NVIDIA chip was used during training. Gemini 3 Pro is around the same size as Gemini 2.5 Pro, but was using much more efficient pre-training and post-training. If you believed that AI scaling had reached a peak during 2025 you were mistaken, and Google Deepmind researchers seem very confident that they will be able to continue scaling model performance for years to come.
Google also launched Antigravity, their new vibe-coding platform. In July earlier this year, Google signed a 2.4 billion agreement with the company Windsurf for a non-exclusive licensing agreement for the entire Windsurf code base AND the two founders at the same time. Antigravity is based on Windsurf. Google seems to have rushed the release however so they even forgot to change strings in it such as changing the name “Cascade” (the LLM used by Windsurf) to Gemini 3 (see picture above). If you enjoyed using Windsurf and thought it was the best agentic platform on the market then you will probably be very happy vibe-coding in Antigravity. I tried using Antigravity myself with different code bases and it’s clear to me this is not its intended purpose. Antigravity is an agentic vibe coding tool, not an IDE for modifying and improving production code.
Gemini CLI is unfortunately still as bad as it has ever been for coding, even with Gemini 3 Pro. About half the time it forgets to format the output in readable format, and about half the time when writing comments it writes it’s full internal reasoning chain into the code comments. It frequently gets stuck “currently experiencing high demand” mid-task (even with a Google Ultra subscription), and it’s nowhere near OpenAI Codex when it comes to writing solid and reliable source code. It also misses things when asked to modify existing code. I have benchmarked GPT-5.1-CODEX-MAX against GEMINI 3.0 Pro the past week (which often falls back to 2.5 pro due to high demand) and I would advice any company against rolling out Gemini CLI with Gemini 3.0 Pro in production right now. It’s just too buggy and incomplete in its current form. If you want to explore agentic programming go with Codex.
It’s clear that Google internally does not use either Antigravity or Gemini CLI, if they tried they would not be able to get anything done. So it will be interesting to see where this goes from here. Was the Gemini CLI team waiting for Gemini 3 Pro with it’s improved tool use before ramping up development speed, or will Gemini CLI keep evolving slowly as an unsupported side project? I guess we will know in a few months.
Read more:
- This is the true AI moat. Gemini 3 was trained 100% on TPUs. No Nvidia tax : r/singularity
- Google hires Windsurf execs in $2.4 billion deal to advance AI coding ambitions | Reuters
- Scott Wu on X: “Congrats to the @antigravity team on the launch today! fyi you missed a spot: https://t.co/SIqINoMRjR” / X
Google Releases Gemini 3 Pro Image (Nano Banana Pro) with Text Rendering and Multi-Character Support
https://blog.google/technology/ai/nano-banana-pro/

The News:
- Google released Nano Banana Pro (Gemini 3 Pro Image) on November 19, 2025. This image generation and editing model uses Gemini 3 Pro’s reasoning and knowledge base and is available in Vertex AI, Google Workspace, Gemini app, and NotebookLM.
- Text rendering accuracy improved from 56% error rate in the previous Nano Banana model to 8% error rate in Nano Banana Pro. The model generates legible text in multiple languages for posters, infographics, and diagrams.
- Character consistency works across up to 5 distinct characters and can blend up to 14 reference images while maintaining chosen details. Users can place characters in new scenes with different outfits across multiple images.
- The model generates images at resolutions up to 4K. Output includes studio-quality control over composition, color, and camera angles. All images include imperceptible SynthID watermarks for AI detection.
- Google’s Josh Woodward reported internal users tested the model by converting code snippets and LinkedIn resumes into infographics. The first Nano Banana contributed 13 million new users to the Gemini app within four days of its August release.
My take: The past six months one of my favorite assignments in my agentic programming workshops was for participants to create an cookbook infographic showing how to prepare different recipes. We used the model gpt-image-1 for this task which until now was one of the best models for text generation, but it had lots of issues with longer sentences and image structure. Now with Nano Banana Pro by Google it feels like we have jumped 3-5 years into the future, at least. This is on a whole different level compared to every single AI image generator we have today. Just look at the infographic on the top of this post.
If you have a few minutes to spare, go to their web page and look at the examples. Google Nano Banana Pro is not just about creating images, it’s about working with images to create content. It’s so good at what it does that it’s actually hard to explain just how good it is. You really should go checkout for yourself. If you have your own advertising agency or work with design today, Nano Banana Pro will fundamentally change the way you work. It’s that good.
Read more:
Google Releases WeatherNext 2 AI Weather Forecasting Model
https://blog.google/technology/google-deepmind/weathernext-2/

The News:
- Google DeepMind and Google Research released WeatherNext 2, an AI forecasting model that generates 15-day weather predictions in under a minute on a single TPU chip. The model produces forecasts eight times faster than its predecessor.
- WeatherNext 2 outperforms the original WeatherNext model on 99.9% of variables (temperature, wind, humidity) and lead times from 0 to 15 days, using the Continuous Ranked Probability Score (CRPS) metric tested against ECMWF ERA5 reanalysis data.
- The model uses a new architecture called Functional Generative Networks (FGN) that injects noise into the model to generate hundreds of possible weather scenarios from a single starting point. This approach enables ensemble forecasting with resolution down to one-hour intervals.
- For tropical cyclones, WeatherNext 2 provides roughly one additional day of useful predictive skill compared to previous models. The model predicts cyclone formation, track, intensity, size, and structure up to 15 days ahead.
- Forecast data is available through Google Earth Engine and BigQuery for analysis, with early access on Google Cloud’s Vertex AI for custom, on-demand inference. The model is integrated into Google Search, Gemini, Pixel Weather, and Google Maps.
- Google notes that precipitation and snow forecasts may lack accuracy due to incomplete training data in those areas. The model can exhibit subtle artifacts appearing as “honeycomb” patterns in higher frequency variables at longer lead times.
My take: Everywhere you are using weather forecasts from Google like Google Search, Google Maps weather information, Google Maps Platform Weather API and Gemini chatbot, all these services use Google’s own platforms GraphCast and GenCast, which have now been upgraded to WeatherNext 2. The new model is not only eight times faster than version 1, it can run on a single TPU chip, and is 99.9% better than the previous model. It still has problems forecasting precipitation and snow forecasts, but for temperature forecasts it should be a solid improvement for everyone, every day.
OpenAI Releases GPT-5.1-Codex-Max for Long-Running Coding Tasks
https://openai.com/index/gpt-5-1-codex-max/

The News:
- OpenAI released GPT-5.1-Codex-Max, an agentic coding model that operates independently on software engineering tasks spanning more than 24 hours.
- The model uses 30 percent fewer thinking tokens than GPT-5.1-Codex while scoring 77.9 percent on SWE-bench Verified, compared to 73.7 percent for its predecessor.
- GPT-5.1-Codex-Max introduces “compaction,” a training technique that maintains coherence across millions of tokens by pruning session history to retain only relevant context.
- The model achieves 79.9 percent on SWE-Lancer IC SWE and 58.1 percent on Terminal-Bench 2.0, outperforming both GPT-5.1-Codex and competing models from Anthropic and Google.
- OpenAI implemented additional cybersecurity safeguards and describes the model as its most capable for security tasks.
- The model is available in Codex for ChatGPT Plus, Pro, Business, Edu, and Enterprise plans, with API access expected soon.
My take: I have used OpenAI Codex for three months now, and both the model (GPT5-CODEX) and the tool (Codex CLI) is improving at an incredible pace. Comparing it to Gemini CLI (above), it’s clear that Google does not use Gemini CLI for anything production related internally, where OpenAI seems to have moved almost every single developer over to Codex CLI the past months. This is how good Codex CLI is today.
As you can see in the graph above, you really need to be pushing GPT5.1-Codex-Max to the “high” reasoning level for best results. And to do this you need an “OpenAI Pro” subscription if you are a full time developer ($200 per month). But if you have not yet tried it, and you are getting tired of Claude constantly saying “You’re absolutely right” while continuing to push out massive amounts of poorly written and bloated code, then invest in yourself and buy an OpenAI Pro subscription. It will change the way you look at software development forever.
OpenAI Upgrades ChatGPT Pro with GPT 5.1 Pro

The News:
- OpenAI released GPT 5.1 Pro on November 19, 2025, exclusively for Pro tier subscribers at $200/month.
- Early testing showed users consistently preferred GPT 5.1 Pro over its predecessor, with testers highlighting “improved clarity, relevance, and structure in its responses”.
- The model delivers performance gains in writing assistance, data science tasks, and business applications.
- GPT 5.1 Pro achieves 94% on AIME 2025 mathematics benchmarks and 88.1% on GPQA graduate-level physics questions.
- The model will replace GPT 5 Pro, which remains available for 90 days before retirement.
My take: I have tried to use the “GPT 5.0 Pro” model many times in the past months, but it is so slow that work with LLMs (with lots of iterations) means it’s not really feasible to work with it. You send it one question and then you have to go and do something else for a few minutes. Do you use GPT 5.0 / 5.1 Pro? For what? I would be very interested in hearing your experience with it.
Read more:
- OpenAI on X: “GPT-5.1 Pro is rolling out today to all Pro users. It delivers clearer, more capable answers for complex work, with strong gains in writing help, data science, and business tasks.” / X
- GPT-5.1 Pro is rolling out today to all Pro users. : r/OpenAI
ChatGPT Launches Group Chats for Up to 20 Users
https://openai.com/index/group-chats-in-chatgpt/
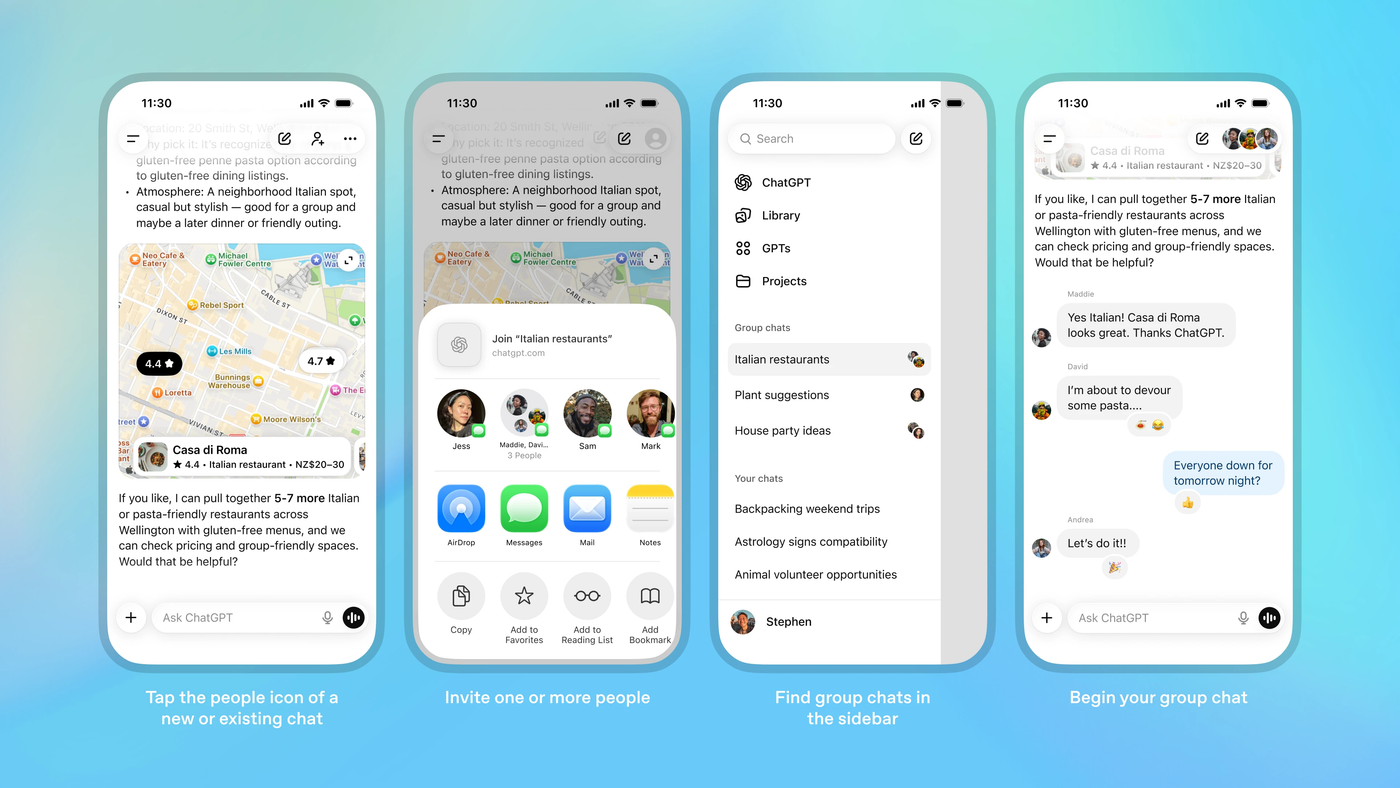
The News:
- ChatGPT introduced group chats on November 20, 2025, following a one-week pilot in Japan and New Zealand. The feature lets users add up to 20 people into a shared conversation with the AI.
- Group chats work across all subscription tiers, including Free, Go, Plus, and Pro plans. Users receive an invitation link and must accept to join the group.
- Personal ChatGPT memory remains private and isolated from group conversations. The AI does not create new memories from group interactions.
- OpenAI trained ChatGPT to recognize conversational flow patterns. The AI determines when to respond and when to remain silent based on message context. Users can mention “ChatGPT” directly to prompt a response, and the bot can react with emoji.
- The feature uses GPT-5.1 Auto, which selects the appropriate model based on the prompt and the access level of the addressed user. Rate limits apply only when ChatGPT sends messages.
My take: I guess the main question is: Will people use this instead of Slack, Teams or iMessage? The only reason I can see people would choose to use ChatGPT group chats instead of their current channels is if they know beforehand that they want to have ChatGPT as an active participant in the chat. At least this is how OpenAI envisions it, where ChatGPT presents restaurant suggestions, and participants responds back with “looks great. Thanks ChatGPT”. That said, I do see several uses for it especially for businesses. Want to come up with a new name for your product, design a class schedule, write an abstract for an article or work with travel plans? All these tasks are things most people use AI for today, so I can definitely see this moving into shared group chats where AI does the research and coordination.
xAI Launches Grok 4.1 with Improved Emotional Intelligence and Reduced Hallucinations

The News:
- xAI released Grok 4.1 on November 18, 2025, as a conversational AI model with reduced hallucination rates and improved emotional intelligence, available free on grok.com, X, and mobile apps.
- The model achieved top ranking on LMArena Text Leaderboard with 1,465 Elo points (before Gemini 3.0 was launched), with a “thinking” variant scoring 1,483 Elo.
- Hallucination rates dropped from 12.09% to 4.22%, while FActScore errors decreased from 9.89% to 2.97%, representing a 50-70% reduction in factual errors.
- Grok 4.1 scored highest on EQ-Bench3, an emotional intelligence benchmark evaluating 45 multi-turn roleplay scenarios for empathy and interpersonal awareness.
- xAI conducted a two-week silent rollout, running blind pairwise comparisons where 64.78% of users preferred Grok 4.1 over the previous model.
- The API version launched November 19 at $0.20 per 1 million input tokens, alongside Grok 4.1 Fast with 2 million token context window for tool-calling applications.
My take: I have said it a few times before, but I genuinely believe hallucinations will not be a significant problem with LLMs in the next 1-2 years. Grok 4.1 going from 12% to 4% hallucinations shows the direction all modern LLMs are taking. xAI is showing some truly amazing progress in their AI development, and I fully expect them to catch up with both Google and OpenAI within the next few months in both text and code generation.
Microsoft, NVIDIA, and Anthropic Announce Strategic Partnerships
https://www.anthropic.com/news/microsoft-nvidia-anthropic-announce-strategic-partnerships

The News:
- Anthropic is scaling its Claude AI model on Microsoft Azure expanding access to Claude for Azure enterprise customers.
- Anthropic has committed to purchase $30 billion of Azure compute capacity and to contract additional compute capacity up to one gigawatt.
- NVIDIA and Microsoft are investing up to $10 billion and up to $5 billion respectively in Anthropic.
- Claude models including Claude Sonnet 4.5, Claude Opus 4.1, and Claude Haiku 4.5 will be available to Microsoft Foundry customers.
- This makes Claude the only frontier model available on all three major cloud providers: Azure, AWS, and Google Cloud.
- NVIDIA and Anthropic will collaborate on design and engineering to optimize Anthropic models for performance and efficiency on NVIDIA Grace Blackwell and Vera Rubin systems.
- Claude will remain accessible within Microsoft’s Copilot family, including GitHub Copilot, Microsoft 365 Copilot, and Copilot Studio.
My take: Thanks to this deal, Azure customers can now choose between both Claude and GPT models within Microsoft Foundry. Great news for all Azure customers that no longer has to sign up for separate API services from Anthropic to use Claude. This makes it so much simpler to rollout agentic frameworks where all model access can be routed through a single Azure Foundry endpoint. If you are not an AI developer this news was maybe not the most exciting news of the week, but for us AI developers this was one of the best.
Meta Segment Anything Model 3 Adds Text Prompts and Video Tracking
https://ai.meta.com/blog/segment-anything-model-3/

The News:
- Meta released Segment Anything Model 3 (SAM 3) last week, a unified AI model that detects, segments, and tracks objects in images and videos using text, visual, and exemplar prompts.
- SAM 3 accepts open-vocabulary text prompts like “striped red umbrella” or “yellow school bus” and returns unique masks and IDs for all matching objects simultaneously, unlike SAM 1 and 2 which predicted a single object per prompt.
- The model achieves 47.0 mask AP on LVIS zero-shot benchmarks, compared to 38.5 for the previous best system, representing a 22% improvement.
- SAM 3 delivers 2x performance on Meta’s new SA-Co benchmark compared to existing systems and processes images at 30 ms per image on an H200 GPU while handling 100+ detected objects.
- Meta built SAM 3 using a hybrid data engine that combined human annotators with Llama-based AI models, which annotated data 5x faster than humans alone and created the SA-Co dataset with over 4 million unique concepts, 5.2 million images, and 1.4 billion masks.
My take: It’s fascinating how quickly these smart classifiers are improving in both features and usability. Have a video stream and want to quickly mask every object of a specific type? Just prompt it. When compared to custom models for medical applications however, SAM 3 is still nowhere near the performance of custom developed models.
I guess the main question is why Meta is investing so much time and money into SAM as a platform. On their web page they say they will use this in Instagram to “enable new effects that creators can apply to specific people or objects in their videos”, and a new “View in Room feature” at Facebook Marketplace. Still seems a bit vague to me; either they have a clear long-term goal with this platform that they are not willing to communicate, or the are just exploring various technologies without having a clear roadmap. None of these options are great.
Read more:
NVIDIA Introduces Apollo Open Models for AI Physics Simulation
https://blogs.nvidia.com/blog/apollo-open-models/

The News:
- NVIDIA announced Apollo at the SC25 conference, a family of open models that accelerate industrial and computational engineering simulations across semiconductors, structural mechanics, weather, fluid dynamics, electromagnetics, and multiphysics.
- The models incorporate neural operators, transformers, and diffusion methods with domain-specific physics knowledge.
- NVIDIA provides pretrained checkpoints and reference workflows for training, inference, and benchmarking.
- Applied Materials achieved 35x acceleration in modules of its ACE+ multi-physics software using NVIDIA GPUs and CUDA framework.
- Synopsys achieved up to 500x speedups by initializing GPU-accelerated fluid simulation tools like Ansys Fluent with AI physics surrogates.
- Cadence used its Fidelity CFD software with NVIDIA -powered Millennium M2000 Supercomputer to produce thousands of time-dependent full aircraft simulations, training an AI physics model that enabled a real-time digital twin of a full aircraft.
- Models will be available through build.nvidia.com, HuggingFace, and as NVIDIA NIM microservices.
My take: NVIDIA is driving this development to make it easier for companies to develop software solutions based on NVIDIA chips. All Apollo models run on NVIDIA GPUs using the CUDA framework and CUDA-X libraries, and when companies like Applied Materials, Synopsys, Siemens, or Cadence adopt these AI physics models, they need NVIDIA hardware to train, fine-tune, and deploy them. It’s a strategic platform that I fully expect will grow in the coming years - it makes it both much easier for companies to get started with state-of-the-art engineering simulations, but also much harder to switch to other hardware providers in the future.
Klay Becomes First AI Company to License Music from All Three Major Labels

The News:
- Klay secured licensing agreements with Universal Music Group, Sony Music, and Warner Music Group, becoming the first AI music service to reach deals with all three major labels.
- The startup licensed thousands of hit songs to train its large language model and will build a streaming service that functions like Spotify while allowing users to remake songs in different styles using AI.
- Klay is led by music producer Ary Attie and employs former executives from Sony Music and Google’s DeepMind, including former Sony Music executive Thomas Hesse and former DeepMind music lead Björn Winckler.
- The company has positioned itself as offering artists and labels control over how their work is used, though details about opt-out provisions for individual artists remain unclear.
- Universal Music Group’s Michael Nash stated the deal “extends our long-standing commitment to entrepreneurial innovation in the digital music ecosystem” and praised Klay’s “commitment to ethicality in generative AI music”.
My take: Klay is building the service everyone has been talking about: Your own music radio that continuously creates new music for you and which you can control and steer in different directions. Want to listen to melodic trance? Just prompt it. In contrast to Suno and Udio, Klay has license agreements in place with all three major record labels. I think this is the kind of service that you wouldhave to try out and experience before judging it, so I will refrain from giving my perspective on this until it’s out so I can try it.