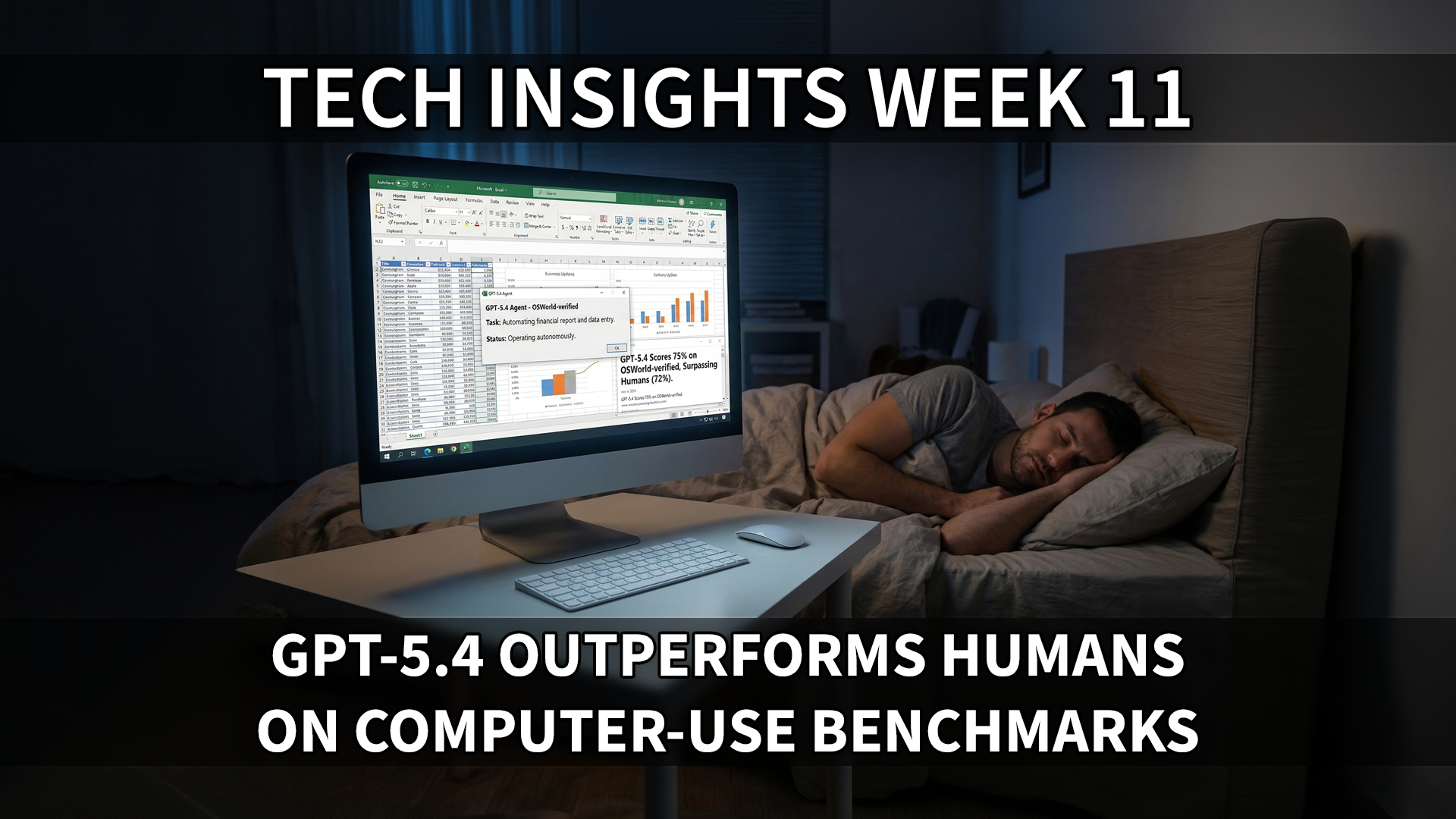
Last year in Tech Insights 2025 Week 30 I wrote: “In my last two seminars I got the question what main trend I see for AI in 2026, and to me it’s easy: computer control. It’s the natural next step, and once we get models specifically trained for this then they will very soon be much more efficient doing things at the computer than any human”. Last week OpenAI launched GPT-5.4 and guess what, it is specifically trained for computer use:
“GPT‑5.4 is our first general-purpose model with native computer-use capabilities and marks a major step forward for developers and agents alike. It’s the best model currently available for developers building agents that complete real tasks across websites and software systems.”
GPT-5.4 is not only good at using web browsers and desktop apps, it is actually better than humans. In the test OSWorld-Verified introduced in July 2025, GPT-5.4 scores 75% where humans averages 72.4%. GPT-5.4 also scores 83% at GDPval (meaning it is better than human experts at 83% of all office tasks), and scores 83% at the visual understanding benchmark ARC-AGI-2 where humans average 60%. Quite soon we will have to measure AI models at how many factors better they are than humans at specific tasks – are they 2x better or 4x better.
It’s hard to overstate the importance of this. Right now we have AI models that are training other AI models with reinforcement learning and the models are learning at an exponential rate. AI models are already better than humans in mathematics, programming, and visual understanding, and are now also better than most of us at using a computer. The models will not just be slightly better in a year – they will be massively better. And massively faster too.
Finally, as a small side-note: Last week Apple announced their new design leadership after Alan Dye (the mastermind behind visual glass) left for Meta last year. Apple has now added both Steve Lemay and Molly Anderson to their executive leadership page. Molly is an industrial designer who has been at Apple for over a decade, and Lemay has been working 27 years at the company. Both are very highly regarded as designers, so those two working closely together with John Ternus (the clear successor to Tim Cook) means the future of Apple looks brighter than ever.
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2026 Week 11 on Spotify
THIS WEEK’S NEWS:
- OpenAI Introduces GPT-5.4
- OpenAI Brings ChatGPT Directly into Excel with GPT-5.4
- OpenAI: Reasoning Models Cannot Control Their Chain of Thought
- OpenAI Codex App Arrives on Windows via Microsoft Store
- Google Workspace CLI Released: Command-Line Access to the Full Workspace API
- NotebookLM Introduces Cinematic Video Overviews
- Anthropic Releases Labor Market Impact Research With New AI Exposure Metric
- Anthropic and Mozilla Partner on Firefox Security Audit
- Claude Adds Memory Import, Targets ChatGPT and Gemini Switchers
- Google Releases Gemini 3.1 Flash-Lite
- Alibaba Releases Qwen 3.5 Small Model Series:
- Cursor Launches Automations: Always-On Coding Agents
OpenAI Introduces GPT-5.4
https://openai.com/index/introducing-gpt-5-4

The News:
- GPT-5.4 merges the coding capabilities of GPT-5.3-Codex with a general reasoning model, now available in ChatGPT, the API, and Codex.
- The model introduces native computer-use capabilities as a general-purpose model for the first time, achieving 75.0% on OSWorld-Verified (desktop navigation via screenshots and keyboard/mouse), exceeding both GPT-5.2’s 47.3% and human performance at 72.4%.
- Hallucination rates are reduced: individual claims are 33% less likely to be false and full responses are 18% less likely to contain any errors compared to GPT-5.2.
- Tool search reduces token usage by 47% on MCP Atlas benchmark tasks by loading tool definitions on demand rather than injecting all definitions upfront into the context window.
- On investment banking spreadsheet modeling tasks, GPT-5.4 scores 87.3% versus GPT-5.2’s 68.4%, and human raters preferred its generated presentations 68% of the time over GPT-5.2 output.
- The 1M token context window is supported experimentally in Codex; API requests exceeding the standard 272K token window are billed at 2x the normal input rate.
- API pricing increases from $1.75 to $2.50 per million input tokens (vs. GPT-5.2), with output at $15/M tokens. The Pro variant moves from $21 to $30/M input and $168 to $180/M output.
My take: At TokenTek have already used GPT-5.4 in several production projects and this is a significant release with improvements all across the board. OpenAI seems to have moved to a monthly release cycle where GPT-5.2 was launched in December, GPT-5.3 in February, and now GPT-5.4 in March. It will be interesting to see if they manage to continue this release schedule over the coming year.
GPT-5.4 is exceptionally good at computer use, and was specifically trained for this. In the benchmark OSWorld-Verified, GPT-5.4 (75%) even performs better than humans (72.4%)! This is a massive leap in performance, and it clearly shows the power of reinforcement learning when the models are focusing on a specific area for improvement in a release.
OpenAI Brings ChatGPT Directly into Excel with GPT-5.4
https://openai.com/index/chatgpt-for-excel

The News:
- OpenAI launched ChatGPT for Excel in beta on March 5, an Excel add-in that embeds ChatGPT directly inside workbooks to build, update, and analyze spreadsheet models using plain-language prompts.
- The add-in is powered by GPT-5.4, the same model available as GPT-5.4 Thinking in ChatGPT, Codex, and the API, positioned by OpenAI for financial reasoning and multi-step modeling tasks.
- Users describe what they need in plain language; the add-in creates or modifies live Excel models in place, preserving existing formulas, sheet structures, and formatting.
- ChatGPT explains its changes as it works, links answers to the specific cells it references, and requests user confirmation before modifying a workbook.
- Alongside the add-in, OpenAI added financial data integrations from Moody’s, Dow Jones Factiva, MSCI, Third Bridge, MT Newswire, and others, with FactSet listed as coming soon.
- The beta is rolling out to ChatGPT Business, Enterprise, Edu, Teachers, Pro, and Plus subscribers in the U.S., Canada, and Australia; a Google Sheets version is listed as forthcoming.
My take: If you use Excel and have a ChatGPT subscription then pause what you are doing and go install GPT-5.4 right now. I promise you will be completely blown away with what it can do. Having an LLM working right inside Excel that can help you with structures, formulas, layout and structure is a game changer.
Give it one more year and the models we have then will be better than most of us creating Powerpoint presentations and Excel sheets. Then add programming skills and a bit of computer control to the mix and you will soon have a remote worker available as a service for virtually any task you can think of, right inside your computer.
Read more:
OpenAI: Reasoning Models Cannot Control Their Chain of Thought
https://openai.com/index/reasoning-models-chain-of-thought-controllability

The News:
- OpenAI published a research paper and open-source evaluation suite measuring whether frontier reasoning models can deliberately obscure their internal reasoning traces, a capability relevant to AI oversight and safety monitoring.
- The study tested 13 reasoning models using CoT-Control, a benchmark containing over 13,000 tasks drawn from GPQA, MMLU-Pro, HLE, BFCL, and SWE-Bench Verified.
- Frontier models scored between 0.1% and 15.4% on CoT controllability, meaning they fail to follow instructions about their own reasoning in at least 84% of cases.
- A concrete example from the paper shows GPT-5.2 Thinking instructed not to use the word “XOR” in its reasoning immediately using it, recognizing the violation mid-thought, then continuing to use the word four more times.
- Controllability increases modestly with model size but drops sharply with longer reasoning chains and additional reinforcement learning post-training; OLMo-3-7B-RL-Zero-Math dropped its controllability score by more than a factor of ten over training.
- OpenAI will begin reporting CoT controllability scores alongside monitorability metrics in system cards for future models starting with GPT-5.4 Thinking, and has committed to not applying direct optimization pressure on frontier model reasoning chains.
My take: As AI models become more advanced being able to monitor their “thoughts” is critical for safety measures. And AI models are still very bad at controlling their thought processes. Ask GPT-5.2 to not use the word “XOR” while reasoning and it will immediately think of it, quickly recognizing it’s mistake, then use the word four more times.
The interesting part here is the balance. If you remember a year ago everyone had fun asking ChatGPT to draw an image with “absolutely no elephants” and it added an elephant in the image every single time. It just couldn’t help it. Today’s models are much better, but ask it to not think about something it ends up thinking about it every single time. And when it comes to security, this is a good thing.
In the article, OpenAI writes: “Low Chain of Thought (CoT) controllability is a feature, not a bug. Current reasoning models’ low controllability makes CoT monitoring more trustworthy as a safeguard. At the same time, we do not yet understand why current reasoning models’ controllability is low—or whether this property will persist as models become more capable”. For now, this gives us an extra layer of control over the models. But we don’t really understand it, and this layer might go away in the near future.
Read more:
OpenAI Codex App Arrives on Windows via Microsoft Store
https://apps.microsoft.com/detail/9plm9xgg6vks

The News:
- OpenAI’s Codex desktop app, previously macOS-only since its February 2026 launch, is now available on Windows through the Microsoft Store as of March 4.
- The app runs natively on Windows using PowerShell inside a dedicated Windows sandbox, built with OS-level security controls including restricted tokens, filesystem ACLs, and dedicated sandbox users.
- Users can run multiple coding agents in parallel, manage long-running tasks, and review code diffs in one place, without switching to WSL or virtual machines.
- The Windows version includes the same core features as the macOS release: Skills for extending Codex capabilities, Automations for background task scheduling, and Worktrees for handling independent tasks within the same project.
- The current model powering the app is GPT-5.4-Codex, which includes experimental support for a 1M context window and improved tool use for long-horizon tasks.
- Supported Windows developer environments now include Visual Studio, Rider, PhpStorm, Git Bash, GitHub Desktop, Cmder, WSL, and Sublime Text.
- The app is free to download and available across Free, Go, Plus, and Pro ChatGPT subscription tiers, with lower-tier accounts subject to tighter token limits.
My take: My main gripe with the Codex desktop app for macOS and Windows is that it’s impossible to clear the context window in a chat session, which you need to do multiple times when you ask the AI to review the code it wrote. You need to start new chat sessions to clear the context. And this means you cannot work in isolated work trees, since these are locked to each chat session. Which in turn means you cannot run multiple sessions in parallel, which is the key point of this software. As it is right now, Codex Desktop app is a tool for vibe coders. If you produce production code I still recommend you stick to the terminal versions.
Google Workspace CLI Released: Command-Line Access to the Full Workspace API
https://github.com/googleworkspace/cli

The News:
- Google Workspace CLI (gws) is a new open-source command-line tool published March 4 under Apache 2.0 license, covering Drive, Gmail, Calendar, Sheets, Docs, Chat, and the Admin Console in a single interface.
- The tool is written in Rust and distributed via npm (npm install -g @googleworkspace/cli); rather than shipping a static command set, it reads Google’s Discovery Service at runtime and builds its entire command surface dynamically, picking up new API endpoints automatically without requiring updates.
- It ships with 50+ agent skills and supports MCP (Model Context Protocol) via gws mcp, which starts a stdio-based MCP server that MCP-compatible clients such as Claude Desktop and Gemini CLI can call directly.
- The CLI accepts raw JSON payloads matching the API schema rather than human-friendly flags, a deliberate design choice to reduce AI hallucination and token consumption. It also includes a dry-run mode for destructive operations and integrates with Google Cloud Model Armor to sanitize malicious prompts in API responses.
- Authentication supports interactive login, service accounts for CI/CD, and existing access tokens. The tool outputs structured JSON, YAML, CSV, and table formats.
My take: Two weeks ago the text editor Obsidian launched version 1.12 with a new CLI feature, allowing AI agents work directly with all your notes. The CEO of Obsidian described it as “54x faster than grep. 70,000x cheaper than MCP”. CLI means AI agents can access Obsidian as a tool, by calling “obsidian” directly from the command line. It’s extremely fast and scales extremely well.
This week we got a CLI from Google, and through this terminal command you can now let AI agents read, send and manage emails, or access and manage calendar events. This is something I would very much like to see from Microsoft too, just imagine if you could access your entire M365 store from a terminal command that your AI agents could access through skills. That would be a true game changer.
Read more:
NotebookLM Introduces Cinematic Video Overviews
The News:
- NotebookLM now generates animated videos from uploaded documents, replacing the previous narrated slideshow format that launched in July 2025.
- The feature combines three Google AI models: Gemini 3 handles narrative structure and script, Nano Banana Pro generates images and visual elements, and Veo 3 produces the final animated output.
- Gemini acts as a creative director, selecting narrative arc, visual style, and format, then running a self-review pass for consistency across the video.
- Users can prompt the system with specific goals, such as “create a three-minute explainer for a non-technical audience” or “compare two approaches and show trade-offs”.
- Access is currently limited to Google AI Ultra subscribers, English language only, users aged 18 and over, with a cap of 20 generated videos per day.
My take: These generated movies are truly spectacular. If you have time just check this YouTube video to see how they look. At launch it requires a Google Ultra subscription ($250 per month) but it should soon trickle down to Pro users.
Read more:
Anthropic Releases Labor Market Impact Research With New AI Exposure Metric
https://www.anthropic.com/research/labor-market-impacts

The News:
- Anthropic economists Maxim Massenkoff and Peter McCrory published a report on March 5, introducing “observed exposure”, a new metric that combines theoretical LLM capability data with real-world Claude usage to measure which jobs AI is actually affecting, not just which jobs it could theoretically affect.
- Computer Programmers rank highest on the observed exposure scale at 75% task coverage, followed by Customer Service Representatives and Data Entry Keyers at 67%.
- Actual AI usage covers only 33% of tasks in Computer & Math occupations, despite theoretical capability estimates reaching 94% for that same category.
- Workers in the most exposed occupations are on average 47% higher-paid, more likely to be female (by 16 percentage points), and nearly four times more likely to hold a graduate degree compared to workers in unexposed roles.
- The study finds no statistically significant increase in unemployment among highly exposed workers since late 2022, but does identify a 14% drop in job-finding rates for workers aged 22-25 entering high-exposure occupations in the post-ChatGPT period.
- For every 10 percentage point increase in observed exposure, BLS employment growth projections fall by 0.6 percentage points through 2034.
- 30% of workers have zero AI coverage in this measure, including Cooks, Motorcycle Mechanics, Bartenders, and Dishwashers.
My take: This report differs from similar work since it weighs actual automated usage more heavily than theoretical task feasibility. This is how you should view this graph – not just where AI can be used, but where AI can be used to automate large parts of everyday work.
“As capabilities advance, adoption spreads, and deployment deepens, the red area will grow to cover the blue.”
Consider all the news this week about computer use automation, then consider areas like finance, math and programming. Of course these areas will be heavily automated in the near future. We just got our very first model that’s better than us at computer use (GPT-5.4) so expect the red areas to start covering the blue areas rapidly in the coming year.
Anthropic and Mozilla Partner on Firefox Security Audit
https://www.anthropic.com/news/mozilla-firefox-security

The News:
- Claude Opus 4.6 conducted a two-week security audit of Mozilla Firefox, finding 22 vulnerabilities and submitting 112 total bug reports, with most fixes shipped to hundreds of millions of users in Firefox 148.0 released February 24.
- Of the 22 security vulnerabilities, Mozilla rated 14 as high-severity, representing roughly one-fifth of all high-severity Firefox vulnerabilities remediated throughout 2025.
- Claude identified its first vulnerability, a Use After Free flaw in the JavaScript engine, within 20 minutes of initial exploration, and had already flagged 50 additional crashing inputs before the first bug report was submitted.
- Anthropic scanned approximately 6,000 C++ files and tested exploitation of the discovered bugs by running the task several hundred times at a cost of around $4,000 in API credits. Claude succeeded in producing a working exploit in only two cases, and those exploits required a test environment with sandboxing deliberately disabled.
- Anthropic has published a Coordinated Vulnerability Disclosure process and released Claude Code Security in limited research preview, which extends vulnerability discovery and patching directly to developers and open-source maintainers.
My take: Wow, just look at that graph. In two weeks Claude Opus found 14 high severity bugs, representing one-fifth of ALL high-severity bugs identified during the entire 2025. The way models are evolving at the moment the trend for 2026 is extremely clear – by the end of 2026 the best AI models will be able to understand extremely complex and large structures in massive code bases, identifying bugs and errors that is way beyond what is humanly possible. If you have a company that is offering these kinds of services to customers today but are doing the work manually, now is the time to start building your first in-house agentic systems on a large scale.
Claude Adds Memory Import, Targets ChatGPT and Gemini Switchers
https://claude.com/import-memory

The News:
- Anthropic launched a memory import tool on March 1 that lets users transfer stored preferences and context from ChatGPT, Google Gemini, and Microsoft Copilot into Claude in two copy-paste steps.
- The tool works by providing a pre-written prompt that users paste into their current AI service; the output is a structured code block summarizing stored memories, which is then pasted into Claude’s memory settings.
- Memory is now available on Claude’s free plan for the first time; it previously required a paid subscription (Pro, Max, or Team) since its general launch in October 2025.
- The import feature is accessible via Settings > Capabilities > “Start import,” and users can review or edit imported data before confirming.
- Anthropic confirmed the import and export of memories has technically been possible since October 2025, but the new dedicated import path and free-tier availability are new as of this release.
My take: AI “memories” are one of the greatest service lock-ins we have seen in modern history. The more you use an AI service the more it learns about you and the better it will get at assisting you. And every year that goes by it will be harder and harder to switch to another service. Neither OpenAI nor Google support exporting AI memories, so switching to another provider traditionally meant you would loose all your memories. With this new import tool you should be able to get most of your memories over to Claude by prompting the AI to list all memories.
“You’ve spent months teaching another AI how you work. That context shouldn’t disappear because you want to try something new.”
And while Anthropic provides an import tool they still do not provide an export tool, so if you are moving from Anthropic to ChatGPT or Gemini later you would still have the exact same problem, but in reverse.
Google Releases Gemini 3.1 Flash-Lite
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-lite

The News:
- Google released Gemini 3.1 Flash-Lite on March 3, targeting high-volume developer workloads where cost per token is a primary constraint.
- Priced at $0.25 per million input tokens and $1.50 per million output tokens, it is 37.5% cheaper than GPT-5 Mini on both input and output.
- According to the Artificial Analysis benchmark, the model is 2.5x faster on Time to First Token and 45% faster on output speed compared to Gemini 2.5 Flash, running at approximately 363 tokens per second.
- On benchmarks, it scores 86.9% on GPQA Diamond (expert-level reasoning) and 76.8% on MMMU Pro (multimodal understanding), and achieves an Elo score of 1432 on the Arena.ai leaderboard.
- The model ships with adjustable thinking levels in both AI Studio and Vertex AI, letting developers tune reasoning depth per task.
- Targeted use cases include high-volume content moderation, translation, UI generation, simulation creation, and multi-step agentic tasks.
My take: The closest competitor to Gemini 3.1 Flash-Lite is GPT-5 Mini. Compared to GPT-5 Mini however Flash-Lite has a 2.5x larger context window (1M vs 400K tokens), includes native support for video and audio input, and leads on 6 of 8 benchmarks including MMLU-Pro, MATH-500, and HumanEval.
So when do you use these smaller models? There are lots of use cases: content classification and labeling, short structured document summarization, code completion and boilerplate generation, and converting unstructured notes to structured formats. All these are use cases where you in most cases do not need a large model and where you need to process large amounts of data on a daily basis, and for those use cases these smaller models typically work very well.
Alibaba Releases Qwen 3.5 Small Model Series:
https://twitter.com/Alibaba_Qwen/status/2028460046510965160

The News:
- Alibaba released four compact open-weight models on March 1: Qwen3.5-0.8B, Qwen3.5-2B, Qwen3.5-4B, and Qwen3.5-9B, licensed under Apache 2.0 and available on Hugging Face.
- All four models are natively multimodal with a 262K context window, built on the same Qwen3.5 foundation as the larger series, and include base model variants intended for research and custom fine-tuning.
- The 9B model scores 70.1 on MMMU-Pro (multimodal reasoning), 81.7 on GPQA Diamond, and 83.2 on HMMT Feb 2025, outperforming GPT-OSS-120B (59.7, 71.5, and 76.7 respectively) on those benchmarks.
- The 4B scores 65.4 on MMMU-Pro, ahead of the previous-gen Qwen3 VL 4B (52.0) and Ministral 3 8B (46.0), while the 0.8B scores 25.8 on the same benchmark.
- According to Artificial Analysis Intelligence Index, the 9B (score: 32) is the top-ranked model under 10B parameters, and the 4B (score: 27) leads all models under 5B.
My take: Feedback so far has been very good for these small models, especially the 9B variant. If you have the need for a model below 10B parameters, Qwen-9B should be on the top of your list. The use cases I listed for Gemini 3.1 Flash-Lite above applies equally well to this model, but here you can run it fully local on a consumer-grade graphics card with decent performance (~ 30 tokens / second).
Read more:
- Qwen3.5-9B Surprised Me – Faster and More Reliable Than Larger Models for My Setup : r/LocalLLM
- Breaking : The small qwen3.5 models have been dropped : r/LocalLLaMA
Cursor Launches Automations: Always-On Coding Agents
https://cursor.com/blog/automations

The News:
- Cursor Automations is a new feature that runs AI agents continuously on a schedule or in response to external events, without requiring a human to initiate each task.
- Agents trigger on events from Slack, Linear, GitHub, and PagerDuty, or via custom webhooks. Each run spins up a cloud sandbox, executes instructions using configured MCPs and models, then verifies its own output.
- Agents carry a memory tool that persists context across runs, letting them learn from previous executions and refine behavior over time.
- Cursor’s own security review automation audits every push to main for vulnerabilities, skips issues already discussed in the PR, and posts high-risk findings directly to Slack.
My take: If you took the time to review the videos of how the new Automations feature works, you’ll notice that Automations is running in the cloud, and not in the desktop app. Cursor as a company started with an “AI Powered” VS Code fork, but is now quickly growing into something completely different. Cursor purchased Graphite in December 2025 (a code review and PR management startup), and my guess is that Cursor is using the Graphite cloud infrastructure for Automations.
This means that Cursor is now a mix of cloud-services and local-services, where Cursor Automations runs in the Cursor cloud environment. Agents connect to your GitHub via OAuth credentials and can read repos, open PRs, post comments, and react to webhooks. You grant the permissions; Cursor’s cloud executes against them.
I have always been cautious in recommending Cursor to companies I work with, mainly because I don’t really know in which direction they are going. VSCode will probably still be an IDE within a year. The main shift they did recently was integrating the Copilot plugin into the VSCode core. But Cursor is now evolving into something else. If you have a Pro, Teams or Enterprise license of Cursor you now also have the cloud based automation features. For some organizations this will be great news, for others it will just bring headaches. For example, there is not a single mention in the Teams setup configuration for Cursor that even mentions if you can disable automations for users, or if this will be enabled by default.
Read more: