W52 · 2025 — December 22, 2025
Tech Insights 2025 Week 52.

In 2017, the Merriam-Webster’s word of the year was “Feminism”, in 2020 it was “Pandemic” and in 2021 it was “Vaccine”. In 2025 the word of the year is “Slop”. The modern definition of “Slop” is “digital content of low quality that is produced usually in quantity by means of artificial intelligence”. Maybe you experienced it but lacked a word for it, well now you have it. Slop. Digital slop is something we have all become used to and exposed to in 2025, and it’s literally everywhere.
Based on the most recent AI launches in Q4 2025 such as GPT-5.2, Opus 4.5, Veo 3.1, Nano Banana Pro and Gemini 3.0 Pro, I do not believe “Slop” will be one of our main problems of 2026. The quality of the generated AI content will just be so much better. But I do think digital content produced in high quantities will be a problem. So maybe the word of the year 2026 will be “overload”. This goes for everything really, from software programming, to graphics, to videos and office work in general. When most work is done over 10 times faster with higher quality than today, structures need to change.
Five weeks ago (in Tech Insights 47) I wrote about the new personalization hub added to ChatGPT to adjust the tone of response. Last Friday, OpenAI added another feature to ChatGPT where you can steer it in even more detail. In the new Characteristics settings you can now set frequency of emojis, how many headers and lists you want in your replies, and even fine-tune the “enthusiasm” level. If you use ChatGPT you probably want to go and change these settings right now. If you use Copilot then unfortunately you still cannot change settings like these, the way Copilot responds to your queries is still fully controlled by Microsoft.
In an interview in the Big Technology Podcast, Sam Altman last week gave his vision for the future of AI tools: “I think there will be a shift over time to the way people use computers where they go from a sort of dumb reactive thing to a very smart proactive thing”. And when it comes to WHEN business should start investing heavy into AI, he states: “The overhang of the economic value that I believe [GPT] 5.2 represents relative to what the world has figured out how to get out of it so far is so huge that even if you froze the model at 5.2, how much more like value can you create and thus revenue can you drive, i bet a huge amount.”. This is what I have been saying for a while now: we don’t need better models, companies just need to start exploring how to best use the current models. Not by creating yet another Copilot chatbot, but by moving real work from people to AI agents, redefining work processes to prevent overload. That said, models will continue to improve, and according to Sam Altman OpenAI already have models planned for Q1 that show “significant gains from 5.2”.
Thank you for being a Tech Insights subscriber!
Listen to Tech Insights on Spotify: Tech Insights 2025 Week 52 on Spotify
THIS WEEK’S NEWS:
- Anthropic Publishes Agent Skills as Open Standard
- Anthropic Launches Claude Chrome Extension for Paid Users
- Meta Releases SAM Audio for Multimodal Audio Separation
- Mistral OCR 3 Achieves 74% Win Rate Over Previous Generation
- Google Launches Gemini 3 Flash, T5Gemma 2 and FunctionGemma
- Alphabet and Nvidia VC Arms Back Lovable at $6.6 Billion Valuation
- ChatGPT Images Launches with GPT Image 1.5 Model
- Apple releases SHARP monocular 3D view synthesis model
- OpenAI Adds Skills Support to Codex CLI and ChatGPT
- OpenAI Releases GPT-5.2-Codex Specialized for Software Engineering and Security
- OpenAI Opens ChatGPT App Submissions
- NVIDIA launches Nemotron 3 family of open models for agentic AI
- Microsoft Releases TRELLIS.2 Open-Source Image-to-3D Model
- Grok Voice Agent API launches for low-latency multilingual voice agents
- Resemble AI Releases Chatterbox Turbo Open Source TTS Model
- ByteDance Launches Seedance 1.5 Pro Audio-Video Generation Model
- Black Forest Labs launches FLUX.2 [max]
Anthropic Publishes Agent Skills as Open Standard
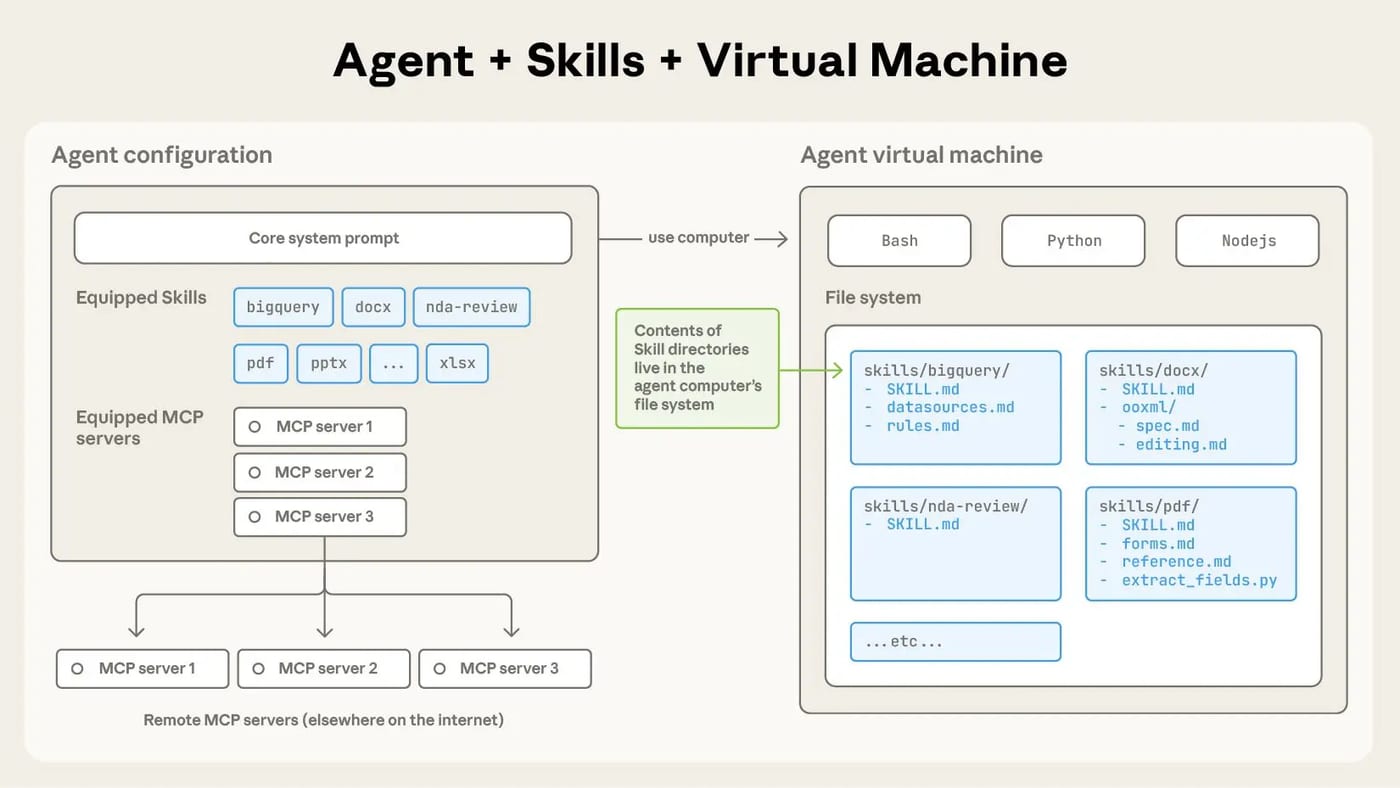
The News:
- Anthropic published Agent Skills as an open standard on December 18, 2025, releasing the specification and SDK at agentskills.io for any AI platform to adopt.
- Agent Skills are folder-based modules containing instructions, scripts, and resources that AI agents load dynamically when relevant to specific tasks.
- The standard uses progressive disclosure, loading only necessary information to reduce token costs and maintain efficiency during complex operations like code execution and filesystem manipulation.
- Microsoft, OpenAI, Atlassian, Figma, Cursor, and GitHub adopted the standard at launch, with partner-built skills available from Canva, Stripe, Notion, and Zapier.
- Skills are composable, stacking together automatically when Claude identifies multiple capabilities needed for complex tasks.
- The same skill format works across Claude apps, Claude Code, and API implementations without modification.
My take: We now have one standard for agentic communication: MCP, one standard for agentic configuration: AGENTS.md, and one standard for Agentic Skills. In 20 years time we will all refer to these standards like we talk about HTTP and SSH today; we are witnessing history in the making. Agent Skills still lack an update mechanism and a centralized distribution infrastructure, so I would not consider it a “production ready” standard by any means, this is still a work in progress. But opening it up as an open standard is a good step in the right direction.
Anthropic Launches Claude Chrome Extension for Paid Users
https://chromewebstore.google.com/detail/claude/fcoeoabgfenejglbffodgkkbkcdhcgfn

The News:
- Anthropic released Claude for Chrome on December 19, 2025, a browser extension that reads webpage content, navigates sites, fills forms, and executes multi-step workflows across tabs.
- The extension requires a Pro subscription at $20 per month, down from the initial $200 monthly fee for Max users during November beta testing.
- Users can record workflows to teach Claude specific task sequences, and the extension integrates with Claude Code through the /chrome command.
- The extension operates in a side-panel within Chrome, extracting webpage content with one click and maintaining conversation context across browsing sessions.
- Claude prompts users before executing high-risk actions like publishing content or making purchases, and automatically deactivates on financial sites, adult content platforms, and torrent sites.
My take: Now before you run to install this, just take note of what you need to agree to before you activate this extension: “Malicious actors can hide instructions in websites, emails, and documents that trick AI into taking harmful actions without your knowledge”. This means that web sites can hide hidden texts that are read by Claude and used as prompt injections to make it do things you did not intend. I tried it for a few basic tasks, and it’s horribly slow. It takes screenshots of every web page, uploads the screenshots for analysis to Anthropic, and slowly takes action. I can only guess the slowness comes from all the guardrails they have implemented but right now this is not something I would recommend to use for anyone.
Read more:
Meta Releases SAM Audio for Multimodal Audio Separation

The News:
- Meta released SAM Audio, a unified model that separates individual sounds from complex audio mixtures using text, visual, or time span prompts. The model addresses audio editing tasks that previously required manual work in dedicated software.
- The model accepts three prompt types. Text prompts describe sounds in natural language, visual prompts select sounding objects in video frames, and time span prompts mark specific segments in the waveform.
- SAM Audio produces two outputs per separation request. The target output contains the isolated sound, and the residual output contains everything else from the original mix.
- Meta released three model sizes: sam-audio-small, sam-audio-base, and sam-audio-large, plus TV variants optimized for visual prompting. The models are available for download and testing in the Segment Anything Playground.
- The architecture uses separate encoders for each conditioning signal, combining audio, text, span, and visual encoders with a diffusion transformer that applies self-attention and cross-attention before decoding.
- Meta acknowledges the model struggles with highly similar audio events, such as isolating one voice among many speakers or a single instrument from an orchestra.
My take: You have all probably seen or heard about stem separation tools, which takes a full music track and extracts vocals, drums, bass and other instruments from it into separate stems. These tools contain models that are carefully tuned for a specific type of audio data, and they typically do a very good job at it. But say you wanted to extract something else? Maybe you want to isolate a specific sound from a specific subject, or the dialogue from just one person in a crowd? This is what SAM Audio does, and it is very impressive! If you have 2 minutes to spare, go to their web page and try the playground, it’s really something else!
Meta also open-sourced PE-AV, the core engine behind SAM Audio’s separation quality. The research team behind PE-AV says that it represents a key step toward general-purpose audiovisual understanding, bridging the gap between what models see and what they hear.
Read more:
- Meta AI Demos
- Pushing the Frontier of Audiovisual Perception with Large-Scale Multimodal Correspondence Learning | Research - AI at Meta
Mistral OCR 3 Achieves 74% Win Rate Over Previous Generation
https://mistral.ai/news/mistral-ocr-3

The News:
- Mistral AI released Mistral OCR 3, a document processing model that extracts text and images from PDFs and scanned documents. The model costs $2 per 1,000 pages via API, or $1 per 1,000 pages through the Batch API.
- The model achieves 74% overall win rate compared to Mistral OCR 2 across forms, scanned documents, complex tables, and handwriting. On the FUNSD dataset for form understanding, it scores an F1 of 0.92, up from 0.87 in OCR 2.
- Mistral OCR 3 outputs markdown with HTML table reconstruction, including colspan and rowspan attributes to preserve layout structure. The model handles rotated text at 98% accuracy and reduces character error rates by 90% on noisy images.
- The Document AI Playground provides a drag-and-drop interface for parsing documents into clean text or structured JSON. The model processes documents up to A3 size at 600 DPI resolution and supports over 100 languages.
My take: It is now 9 months since Mistral release OCR 2 in March 2025, and the amount of progress Mistral shows in this relatively short time frame is impressive. One of the key capabilities of Mistral OCR is native handwriting support which makes it possible to use one engine for both machine written and hand written documents. We are quickly moving away from models that just translates text into models that truly understand both the structure and context of the text. This model should be on top of your list if you are working with document processing.
Read more:
Google Launches Gemini 3 Flash, T5Gemma 2 and FunctionGemma
https://blog.google/technology/developers/build-with-gemini-3-flash/

The News:
- Google introduced Gemini 3 Flash as the new default model for Gemini app users and Google Search AI Mode, targeting high-volume tasks such as coding, gaming assistants, deepfake detection, and document analysis.
- Gemini 3 Flash processes text, images, video, and audio, and ships through Google AI Studio, Gemini API, Vertex AI, Android, Antigravity, and the Gemini CLI, with support for long-running stateful agents via the new Interactions API.
- T5Gemma 2 extends the Gemma 3 family with encoder-decoder models that support multimodal input, using a vision encoder plus text to handle visual question answering and multimodal reasoning across context windows up to 128K tokens.
- T5Gemma 2 comes in compact sizes around 370M, 1.7B, and 7B parameters (excluding the vision encoder), reuses tied embeddings and merged attention to cut parameter count, and is trained on over 140 languages for multilingual work.
- FunctionGemma is a 270M parameter variant of Gemma 3 tuned specifically for function calling, designed to translate natural language into structured API calls and act as a local agent or traffic controller that routes complex tasks to larger models such as Gemma 3 27B.
- Google reports that fine tuning FunctionGemma on its Mobile Actions dataset raised task accuracy from 58 percent to 85 percent, and third party coverage notes it can run with about 550MB RAM on phones and Jetson-class devices.
My take: The primary use for FunctionGemma is to run in mobile phones, translating user intentions to defined APIs. The model is built to be fine-tuned, so you get consistent, deterministic behavior rather than zero-shot prompting variability. If you are developing mobile apps and want to add “smartness” to them, this is the model to use. You can check the Google blog page for lots of nice examples. T5Gemma 2 is a transformer model with full encoder-decoder split, in contrast to LLMs that only keep the decoder. It’s great at tasks like translating texts into different languages, summarizing documents, analyzing documents with retrieval (like find all mentions of a product code across 100 support tickets), and instruction-following tasks where you need precise output based on complex input. And finally Gemini 3 Flash is a masterpiece of engineering, with performance close to Gemini 3 Pro but much faster and cheaper. Google said that they used new technologies for pre-training in Gemini 3 Flash that made it so close in performance to Gemini 3 Pro, and that they will use these technologies to further improve the next version of Gemini Pro.
Read more:
- FunctionGemma: New Gemma model for function calling
- T5Gemma 2: The next generation of encoder-decoder models
Alphabet and Nvidia VC Arms Back Lovable at $6.6 Billion Valuation
https://www.cnbc.com/2025/12/18/google-and-n.html

The News:
- Lovable, a Swedish AI coding startup, raised $330 million in Series B funding at a $6.6 billion valuation.
- CapitalG (Alphabet’s growth fund) and Menlo Ventures led the round, with participation from Nvidia’s NVentures, Accel, Khosla Ventures, Salesforce Ventures, Databricks Ventures, and Atlassian Ventures.
- The valuation more than tripled from $1.8 billion in July 2025, just five months earlier.
- Lovable offers “vibe coding” where users describe applications in natural language and AI generates production-ready code.
- The platform surpassed $200 million in annual recurring revenue, doubling from $100 million ARR reached eight months after launch.
- More than 100,000 new projects are built daily on the platform, with over 25 million projects created in the first year.
- The company plans to use funds for third-party app integrations, enterprise features, and infrastructure such as databases, payments, and hosting.
My take: If I knew much less about agentic programming than I do today, then I would probably be all-in on Lovable, “the last piece of software” you need to build all other software. Lovable has grown from 10 employees in 2024 to over 130 employees in 2025, they hire 17 year olds straight from high school, and will probably be over 500 people in 2-3 years. Anton Osika is an amazing person and I wish him and his company all the best, but as I have said in my newsletters many times before - I really believe AI companies need to own their own models. Therefore my best-guess for Lovable is that they will continue to grow, and in 2-3 years the company will be sold using stock exchange by one of the US AI giants for over $10 billion to expand their vibe code offering. Investors will become richer and the AI bubble will grow bigger.
ChatGPT Images Launches with GPT Image 1.5 Model
https://openai.com/index/new-chatgpt-images-is-here/

The News:
- OpenAI released GPT Image 1.5 on December 16, 2025, as its flagship image generation model, available in ChatGPT for all users and through the API.
- The model generates images up to 4x faster than its predecessor while reducing operational costs.
- GPT Image 1.5 preserves specific details during edits, including facial likeness, lighting, composition, and color tone across multiple iterations.
- The model renders text within images, handling dense markdown, code snippets, and small text that previous versions struggled with.
- OpenAI introduced a dedicated Images section in ChatGPT with preset styles and popular designs, replacing the previous text-prompt-only workflow.
My take: I have used and compared GPT Image 1.5 with Google Nano Banana Pro the past week and for some creative tasks GPT Image 1.5 is better, but when it comes to photo realism and overall quality Google Nano Banana Pro is in a different league, it’s way better. GPT Image 1.5 is also very restrictive when it comes to content it can generate, and while speed improvement is stated as “up to 4x” in practice it is much slower than that.
Read more:
Apple releases SHARP monocular 3D view synthesis model
https://github.com/apple/ml-sharp

The News:
- Apple released SHARP, a monocular view synthesis model that reconstructs a 3D Gaussian scene from a single image in under one second on a standard GPU, targeting real time 3D views from 2D photos.
- SHARP predicts a full 3D Gaussian scene representation in a single feedforward pass, then renders nearby viewpoints in real time at high resolution using that representation.
- The representation is metric with absolute scale, so camera trajectories correspond to physical movements rather than arbitrary parallax.
- On multiple benchmarks, SHARP reduces LPIPS by about 25–34 percent and DISTS by about 21–43 percent compared with the strongest prior model, while lowering synthesis time by roughly three orders of magnitude.
- The code and weights are open source on GitHub, with a CLI that runs
sharp predict -i /path/to/input/images -o /path/to/output/gaussians, downloading the model checkpoint automatically or via a direct URL.
My take: To understand the use cases for Apple SHARP, you really need to spend 30 seconds watching the video showing how you can use SHARP within the Apple Vision Pro environment. It’s amazing: take any photo and nearly instantly convert it to a full 3D Gaussian 3D model which you can move around in. Combine this with a generative model and we are very close to creating full detailed 3D walkthroughs based on just an iPhone capture.
Read more:
- Apple introduces SHARP, a model that generates a photorealistic 3D Gaussian representation from a single image in seconds. : r/LocalLLaMA
- Paper page - Sharp Monocular View Synthesis in Less Than a Second
- Apple’s new open-source model turns 2D photos into 3D views - 9to5Mac
OpenAI Adds Skills Support to Codex CLI and ChatGPT
https://community.openai.com/t/skills-for-codex-experimental-support-starting-today/1369367

The News:
- OpenAI launched experimental support for Skills in Codex CLI and ChatGPT, adopting the filesystem-based skill mechanism originally introduced by Anthropic in October 2025.
- Skills consist of a folder containing a SKILL.md file with metadata and instructions, plus optional scripts and resources that coding agents can discover and load into context when relevant.
- Codex CLI scans ~/.codex/skills directories at startup and makes discovered skills available through the —enable skills flag.
- ChatGPT implements skills through a /home/oai/skills directory covering spreadsheets, docx files, and PDFs with conversion to rendered PNGs for vision model processing.
- Skills use progressive disclosure with three levels of detail: metadata for discovery, full SKILL.md content when loaded, and optional linked files for complex scenarios.
My take: Skills make it super easy to setup personal agentic workflows with Claude Code and Codex, such as document processing, report generation, web search, and much more. If you are a heavy ChatGPT or Claude user you really should invest some time into learning how to use Skills in your daily work, it brings so many possibilities to everyday repetitive tasks. With Skills now also being an open standard thanks to Anthropic the investment will be worth it.
Read more:
OpenAI Releases GPT-5.2-Codex Specialized for Software Engineering and Security
https://openai.com/index/introducing-gpt-5-2-codex/

The News:
- GPT-5.2-Codex is OpenAI’s specialized coding model released December 18, 2025, designed for complex software engineering tasks and cybersecurity workflows.
- The model scored 56.4% on SWE-Bench Pro, compared to GPT-5.2 at 55.6% and GPT-5.1 at 50.8%, and achieved 64.0% on Terminal-Bench 2.0.
- Native context compaction processes millions of tokens in a single session through automatic compaction at context limits via a new /responses/compact API endpoint.
- Security researchers used the predecessor GPT-5.1-Codex-Max to discover a previously unknown vulnerability in React Server Components within one week by guiding the model through fuzzing and local test environments.
- The model achieved 87% on CVE-Bench for vulnerability discovery tasks and 72.7% on long-form Cyber Range assessments.
My take: While not being much better in benchmarks than the “regular” GPT-5.2, GPT-5.2-Codex is significantly stronger in discovering vulnerabilities. I have used this models the past few days, and while GPT-5.2 is excellent, this model really takes it to the next level. I have run it exclusively at the “Extra high” setting and it really feels “smart” when you work with it. It’s thorough, detailed and thoughtful and the code it generates is so good that you really need to remind yourself that a year ago the best we had was Claude Sonnet 3.5 that could write a few dozen lines at a time with decent quality.
OpenAI Opens ChatGPT App Submissions
https://openai.com/index/developers-can-now-submit-apps-to-chatgpt/
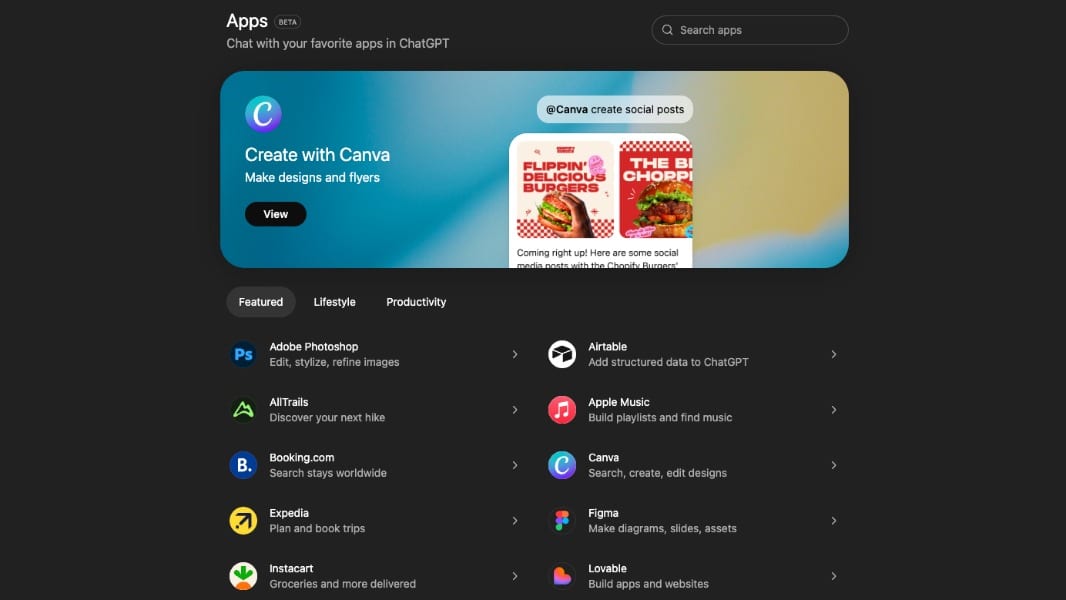
The News:
- OpenAI opened app submissions to developers on December 17, 2025, allowing third-party applications to be reviewed and published within ChatGPT.
- Apps extend ChatGPT conversations by connecting external services and data, such as ordering groceries, creating slide decks, or searching apartments.
- The Apps SDK, built on the Model Context Protocol, provides developers with tools to create interactive UI elements including buttons, maps, and sliders directly in chat responses.
- Developers submit apps through the OpenAI Developer platform where they can track approval status, with approved apps launching gradually in early 2026.
- The app directory launched at chatgpt.com/apps and within the ChatGPT tools menu, featuring early partners including Booking.com, Canva, Spotify, Zillow, DoorDash, and Apple Music.
- Apps activate via @mention commands or appear as contextual suggestions during conversations based on user topics.
- Apps currently support external links for physical goods transactions only, with digital goods and monetization details unspecified.
My take: This is the second try for OpenAI to launch an app store, with the previous one being the GPT Store launched in January 2024. I think this has much better changes of succeeding, mainly because the new Apps system put the applications directly inside chat responses rather than creating a separate chatbot experience. No revenue-sharing details or monetization plans have been announced yet, but it will definitely come. Right now I am not too convinced this is the way to go for most apps, bringing apps into ChatGPT is a much worse experience for apps like Figma and PhotoShop, compared to bringing ChatGPT into the apps. I am also not totally sure users will actually bother to download these apps, or if they will just continue use ChatGPT as it is. It will be very interesting to follow how this evolves in 2026.
NVIDIA launches Nemotron 3 family of open models for agentic AI
https://nvidianews.nvidia.com/news/nvidia-debuts-nemotron-3-family-of-open-models

The News:
- NVIDIA introduces the Nemotron 3 family of open models, data, and libraries for building agentic AI systems across industries.
- The family ships in three sizes, Nemotron 3 Nano, Super, and Ultra, using a hybrid Mamba Transformer mixture of experts architecture for multi agent workloads.
- Nemotron 3 Nano is a 30 billion parameter model with about 3 billion active parameters per token, a 1 million token context window, and is trained in NVFP4 with FP8 inference weights.
- NVIDIA reports that Nemotron 3 Nano achieves up to 4x higher throughput than Nemotron 2 Nano, and about 3.3x higher throughput than Qwen3 30B and 2.2x than GPT OSS 20B on an 8k in 16k out H200 benchmark.
- On Vectara’s hallucination leaderboard, Nemotron 3 Nano 30B A3B is listed with a 9.6 percent grounded hallucination rate and 90.4 percent grounded quality score, similar to Qwen3 Next 80B A3B Thinking at 9.3 percent.
- NVIDIA releases supporting components such as NeMo Gym, NeMo RL, and NeMo Evaluator as open source to provide training environments, reinforcement learning pipelines, and evaluation tools, with distribution through GitHub, Hugging Face, and NIM microservices.
- Nemotron 3 Nano is available now via Hugging Face, vLLM, SGLang, LM Studio, OpenRouter, and NVIDIA build endpoints, while Super and Ultra are slated for the first half of 2026.
My take: Nemotron 3 Nano is 2-3 times faster than Qwen3 30B and GPT OSS 20B on a single H200 GPU, while matching or exceeding the reported accuracy on several reasoning benchmarks. This is a very strong model for agentic workflows, with a large 1 million token context window and low hallucination rates. NVIDIA has so far not yet published any benchmarks on the larger models Super (100B parameters) and Ultra (500B parameters), and they expect to arrive first half of 2026.
NVIDIA also released NeMo Gym and NeMo RL, where Nemotron 3 Nano serves as the general reasoning and orchestration model, NeMo Gym provides the environments and tasks for agents to act in, and NeMo RL turns those interactions into systematic post‑training. It’s basically everything you need for a complete local agentic setup, including post-training. If you are working with agentic systems you should really checkout Nemotron 3, including NeMo Gym and NeMo RL and see if they fit your use cases.
Read more:
- GitHub - NVIDIA-NeMo/Gym: Build RL environments for LLM training
- GitHub - NVIDIA-NeMo/RL: Scalable toolkit for efficient model reinforcement
Microsoft Releases TRELLIS.2 Open-Source Image-to-3D Model

The News:
- Microsoft released TRELLIS.2, a 4 billion parameter open-source 3D generative model that converts single images into textured 3D assets with full PBR materials.
- The model uses a sparse 3D VAE and an O-Voxel representation to compress 3D geometry with 16× spatial downsampling while preserving complex topology and sharp surface details.
- TRELLIS.2 generates 512³ assets in about 3 seconds, 1024³ in about 17 seconds, and 1536³ in about 60 seconds on a single NVIDIA H100 GPU, with separate shape and material timings reported.
- The pipeline includes CUDA-accelerated mesh processing and exports GLB assets with base color, roughness, metallic, opacity, and other maps suitable for common DCC tools and game engines.
- Microsoft provides a public Hugging Face checkpoint and GitHub repository, plus a web demo that accepts direct image uploads without local setup.
My take: The first version of Microsoft Trellis was launched a year ago, and it found it’s place as a decent complement to other SOTA image-to-3d tools like Hunyuan Image 3.0. Where Hunyuan excelled in some areas but lacked in others, Trellis could usually fit the spot and produce good result in those areas. Trellis 2 introduces a new O-Voxel “field free” sparse voxel structure which should mean higher quality of the output geometry and higher resolution. Based on early user feedback most still seems to prefer Hunyuan 3D, but again this can be a nice complement for some use cases especially since it’s free and open source.
Read more:
Grok Voice Agent API launches for low-latency multilingual voice agents
https://x.ai/news/grok-voice-agent-api

The News:
- xAI introduced the Grok Voice Agent API, a speech-to-speech interface for building real-time conversational voice agents, positioned for contact centers, assistants, and other interactive audio applications.
- The API uses a WebSocket endpoint for full duplex audio, accepts both audio and text, and streams back text and synthesized speech in real time.
- xAI reports sub 700 ms response latency and time-to-first-audio under one second, and states that Grok ranks first on the Big Bench Audio reasoning benchmark and is nearly five times faster than the closest competitor on this test.
- Pricing is a flat 0.05 USD per minute, about 3 USD per hour, with xAI community users citing this as roughly half the cost of OpenAI’s Realtime API; xAI also offers 150 USD in monthly credits for developers who opt into telemetry plus 20,000 sandbox tokens.
- The system supports over 100 languages with automatic language detection, multiple expressive voices, and prosody controls such as laughing, whispering, and tone shifts.
My take: Ok so exactly what is the “Grok Voice Agent API”? Basically it’s the Tesla “voice system in a box” that listens to audio data on a Websocket and sends back text and audio tokens. You control it with JSON messages to set system instructions, pick the Grok model, choose the voice, toggle things like turn detection, and register tools / functions (with JSON schemas) so the agent can call your backend APIs. xAI describes it as a single model that takes speech in and generates expressive speech out, instead of three separately orchestrated components for ASR, LLM, and TTS. As is usual with xAI they don’t go much into details into what variant of Grok is used in the Voice Agent. Should you use it? If you have the needs for a high quality navigation agent then you might want to look into the Grok Voice Agent API. If you want to test how it works just jump into any Tesla car, it’s built right into the core navigation experience.
Resemble AI Releases Chatterbox Turbo Open Source TTS Model
https://www.resemble.ai/chatterbox-turbo/

The News:
- Resemble AI released Chatterbox Turbo, an open source text-to-speech model with 350 million parameters that generates speech 6x faster than real-time on GPU.
- The model clones voices from 5 seconds of reference audio without training and includes built-in PerTh watermarking that embeds imperceptible neural watermarks surviving MP3 compression and audio editing.
- Chatterbox Turbo achieves 75ms latency through single-step mel decoding, reduced from the previous 10-step process in earlier Chatterbox versions.
- The model supports paralinguistic tags including [cough], [laugh], [sigh], and [gasp] that generate natural vocal reactions in cloned voices.
- Resemble AI includes emotion exaggeration control that adjusts output intensity from monotone to expressive through a single parameter.
- The model is MIT licensed and available on Hugging Face and Replicate as of December 14, 2025.
My take: Definitely look into this model if you need real-time TTS. Compared to other models like VibeVoice 7B that requires 24GB of VRAM to run, Chatterbox Turbo requires only 6GB of VRAM to run, so you can run it on fairly cheap consumer-grade GPUs like RTX 4060 (8GB). When I first listened to it on the Resemble AI web page I was disappointed, but then I noticed I was listening to the ElevenLabs samples they put up as references. This model actually sounds really good, and the fact that you can run it on such cheap hardware only makes it better.
ByteDance Launches Seedance 1.5 Pro Audio-Video Generation Model
https://seed.bytedance.com/en/seedance1_5_pro

The News:
- ByteDance released Seedance 1.5 Pro on December 16, 2025, a dual-branch Diffusion Transformer model that generates synchronized audio and video content from text prompts or image inputs.
- The model generates videos up to 10 seconds at resolutions of 480p, 720p, and 1080p, with generation times of approximately 41 seconds for 5-second clips at 1080p.
- Audio-visual synchronization matches character lip movements with speech across multiple languages and dialects, including support for stylized content like comedy performances.
- Camera control includes complex movements such as long tracking shots and Hitchcock zooms, with multi-shot storytelling that maintains character identity across different angles.
- The model uses post-training optimizations including Supervised Fine-Tuning on high-quality datasets and Reinforcement Learning from Human Feedback with multi-dimensional reward models, achieving a 10X increase in inference speed compared to earlier versions.
- Available through Ji Meng AI and Dou Bao platforms, with pricing at $1.8 to $2.5 per million tokens depending on model tier.
My take: I wasn’t too impressed with this model. On stills images it looks like it has quite some potential, but once you see things moving and hearing the generated audio it more or less falls apart, it both looks and sounds super artificial. Google Veo 3.1 is the current benchmark for AI-generated video, and despite nice improvements since Seedance 1.0 Pro was first launched in June this year it’s still not even close to the quality of Veo 3.1.
Black Forest Labs launches FLUX.2 [max]
https://bfl.ai/models/flux-2-max

The News:
- Black Forest Labs released FLUX.2 [max], a text to image and image editing model positioned as the highest precision variant in the FLUX.2 family for production image work.
- The model outputs images up to 4 megapixels and supports flexible aspect ratios, which targets use cases like marketing assets, product shots, and print layouts.
- FLUX.2 [max] accepts up to 10 reference images in a single run to maintain character, product, or brand consistency across generations and edits.
- Grounded generation integrates live web search so outputs can reflect current events, entities, and factual context instead of relying only on static training data.
- The model uses the FLUX.2 latent flow matching architecture with an integrated vision language backbone, and sits alongside FLUX.2 [pro], [flex], and [dev], with [dev] offered as open weights for local deployment.
My take: One of the key advantages with FLUX.2 compared to other top models like Nano Banana Pro is that you can give it JSON structures to describe your images. Depending on your workflow this can be exactly what you need to control lightning and materials in a consistent way across dozens of images. Quality-wise the model is still behind Google Nano Banana Pro, and it’s also closed-source. Check it out if you are working professionally with AI-generated images, otherwise you are probably better off with Nano Banana Pro and Z-image that both complements each other very well.