W1 · 2026 — December 29, 2025
Tech Insights 2026 Week 1.

A year ago on December 14 2024 Ilya Sutskever famously warned that the “age of pre-training” was nearing its end. He called training data the “fossil fuel” of AI, said we had reached “peak data”, and reminded everyone that “there’s only one Internet”. There were many LinkedIn experts who believed in this, and I believe this talk significantly contributed to many companies waiting with their AI investments in 2025.
By late 2025 Sutskever was still arguing that simply turning the pre-training crank harder would not magically transform capabilities, describing 2020–2025 as the “age of scaling” and suggesting we are returning to an “age of research”, just with much bigger computers. Even Yann LeCun, reliably skeptical about current approaches, said: “Some people claim that if we just keep improving our current technology, we’ll achieve human-level intelligence… I’ve always thought that was nonsense”.
Now as we close out 2025 however the “slowdown” narrative by both Ilya and Yann looks greatly overstated. Internet scraping may have matured, but progress did not stop. Scaling shifted toward new training recipes (including heavier use of reinforcement learning), a more synthetic experience, and more compute spent at inference time, plus agents that can iterate, check their work, and use tools. 
The launch of GPT-5.2 is just one example of that pivot: OpenAI GPT-5.2 has reached human-expert level on GDPval across 44 occupations, beating professionals on over 70% of comparisons, while producing outputs at more than 11x the speed and under 1% of the cost of expert professionals.  The “fossil fuel” constraint did not kill the engine. It just forced the AI companies to build a better one.
Here are my five predictions for 2026:
- I predict most programmers will stop writing code and shift all their focus to requirements, review and test. We already have the tools for 10x improvement (GPT-5.2 and Opus 4.5) and now it’s just a matter of how fast organizations will adopt it. Developers who don’t transition will be slowly phased out.
- I predict most companies will start to understand the enormous potential of agentic AI systems, and will start to invest in learning and building foundations for it. By the end of 2026 I predict most companies will at least have a roadmap to adopt AI Agents into their core business.
- I predict we will see the first AI systems that have contributed with new scientific inventions. AI models are already better than the best mathematicians and programmers in the world, next year they will be better by several factors and that should help drive research and innovation forward at an incredible pace.
- I predict that by the end of next year, most office workers using AI will primarily work as human-in-the-loop (not all office workers). The AI will be the one driving the work forward, with us tagging along giving it input, steering it in the right direction and approving the results. Some of us are already there in terms of programming, but I believe a majority of all desktop workers with access to AI in their workplace will be there for most office tasks within the next 12 months.
- I predict young engineers highly skilled in agentic AI will be much more productive than senior employees stuck in old habits, creating a surge for graduate students that are also highly skilled in generative AI. This is the main reason we launched our new AI specialist talent program at TokenTek together with Hubbau, and there are already many companies including one of Sweden’s largest banks signed up for it and ready to launch in 2026. This means that in early 2027 there will be a large number of young and very hungry engineers that know the inside-and-out of transformer models and agentic AI systems and they will all be more productive than what anyone thinks is possible today.
With that I wish you all a happy new year and see you in 2026! 🎉
Listen to Tech Insights on Spotify: Tech Insights 2026 Week 1 on Spotify
THIS WEEK’S NEWS:
- Andrej Karpathy: Powerful Alien Tech Is Here - Do Not Fall Behind
- NVIDIA Licenses Groq’s Inference Technology, Hires Key Executives
- Google Tests 30-Minute Lecture Mode for NotebookLM
- Poetiq Achieves 75% Accuracy on ARC-AGI-2 Benchmark Using GPT-5.2
- OpenAI Hardens ChatGPT Atlas Against Prompt Injection
- Z.AI Releases GLM-4.7 Open-Source Coding Model
Andrej Karpathy: Powerful Alien Tech Is Here - Do Not Fall Behind
https://x.com/karpathy/status/2004607146781278521
The News:
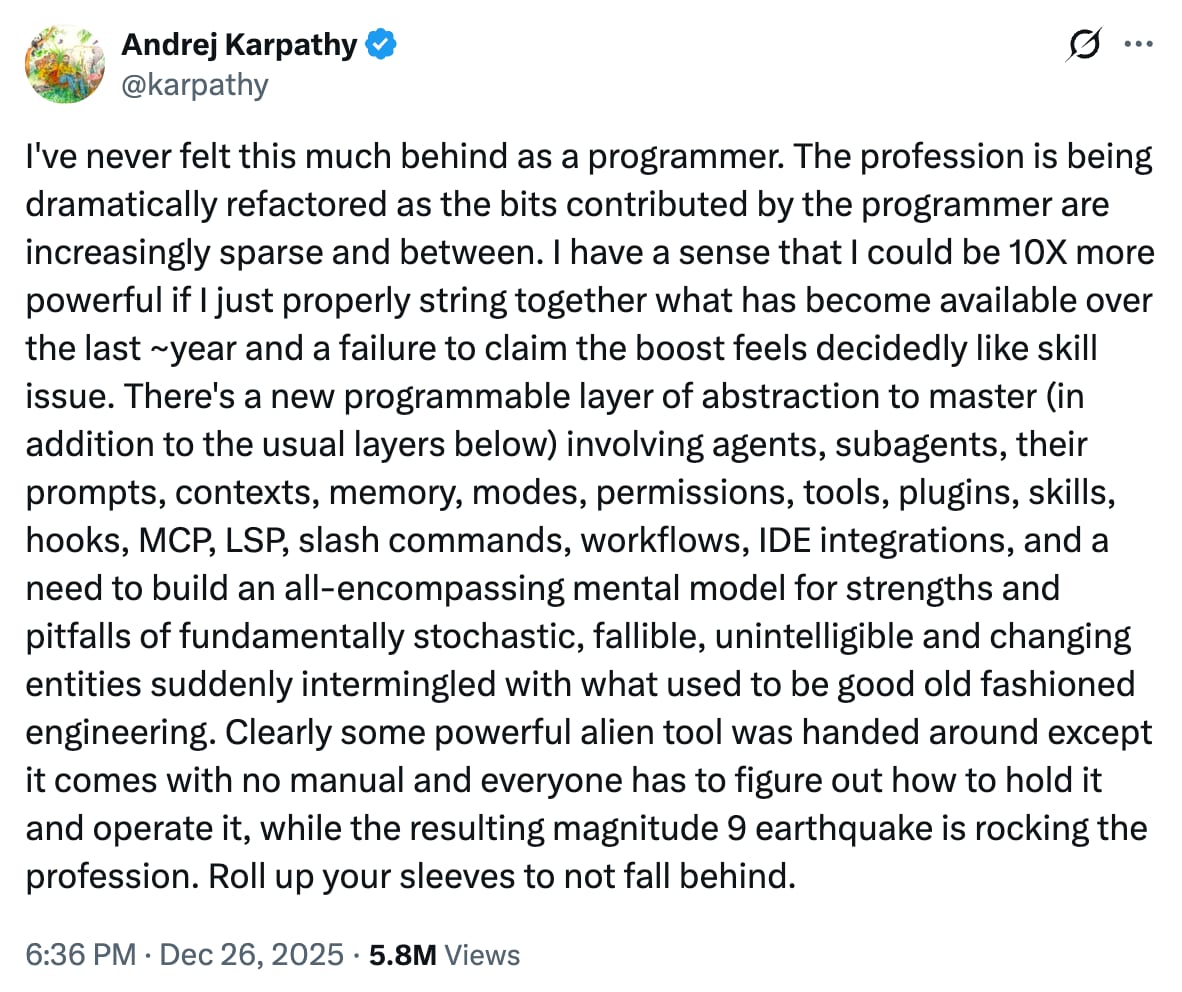
- Andrej Karpathy, former Tesla AI director and OpenAI co-founder, stated he has “never felt this much behind as a programmer” due to rapid AI-driven changes in software development.
- Karpathy described the profession as being “dramatically refactored” with programmers contributing increasingly sparse code while primarily connecting various AI tools and services.
- He noted developers could achieve “10X more powerful” productivity by properly integrating tools that emerged over the past year, calling the failure to adopt them a “skill issue”.
- Karpathy compared the transition to receiving “a powerful alien tool” without a manual, requiring developers to independently figure out operation while the profession experiences a “magnitude 9 earthquake” level transformation.
- The tweet received 581,200 views, 10,000 likes, and 651 replies within 24 hours, indicating widespread resonance with developers.
My take: If you have been reading my newsletters you know this is what I have been saying the past six months now. What makes this post so good is that Andrej Karpathy gives some good thoughts on the new types of skills required by the next generation of programmers:
“There’s a new programmable layer of abstraction to master (in addition to the usual layers below) involving agents, subagents, their prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations, and a need to build an all-encompassing mental model for strengths and pitfalls of fundamentally stochastic, fallible, unintelligible and changing entities suddenly intermingled with what used to be good old fashioned engineering”.
Enabling your employees to become 10x developers is much more than just enabling GitHub Copilot, it requires deep training and time investment from both your side and the employees. This is not a simple transition, and many times it really does feel like working with a “powerful alien tool with no manual”. But when you learn to use it the right way, oh boy, you will never go back to writing a single line of code by hand.
Anthropic developer Boris Cherny also had a great follow-up post to this where he raises one important observation I have also experienced:
“In a way, newer coworkers and even new grads that don’t make all sorts of assumptions about what the model can and can’t do - legacy memories formed when using old models - are able to use the model most effectively. It takes significant mental work to re-adjust to what the model can do every month or two, as models continue to become better and better at coding and engineering.”
This is the main reason why we target young engineers with our 12-month teaching program at TokenTek. Young engineers move fast and do not have decades of old habits they need to change before becoming effective with these new “alien tools”. To them, everything else feels slow and old.
Read more:
NVIDIA Licenses Groq’s Inference Technology, Hires Key Executives

The News:
- NVIDIA entered a non-exclusive licensing agreement with Groq on December 24, 2025, gaining access to Groq’s Language Processing Unit (LPU) inference technology.
- The deal structure involves asset acquisition and technology licensing, reported at approximately $20 billion in value, making it NVIDIA’s largest transaction, surpassing its $6.9 billion Mellanox purchase in 2020.
- Groq founder Jonathan Ross, president Sunny Madra, and other team members will join NVIDIA to develop and scale the licensed technology.
- Groq remains an independent company under new leadership, with CFO Simon Edwards stepping in as CEO.
- The transaction excludes Groq’s cloud business (GroqCloud), which continues operating separately.
- Groq’s LPU architecture delivers 185 to 300 tokens per second for inference tasks, achieving 3 to 18 times faster output throughput than cloud-based GPU providers in public benchmarks.
- The deal grants NVIDIA access to Groq’s deterministic inference design, which maintains consistent response times with 0.22 second time-to-first-token.
My take: So, this is Groq, not Grok. Grok is the AI chatbot developed by X and xAI and Groq (which NVIDIA acquired) is an AI chip company founded in 2016 by Jonathan Ross, former Google engineer who previously worked on Google’s Tensor Processing Unit (TPU). The interesting thing about this purchase is that the company Groq continues as before - the acquisition is non-exclusive. But NVIDIA gets the founder, the president and access to all the technologies the company developed during the past 9 years.
In other words this purchase is less about buying a competitor and more about buying an inference advantage. NVIDIA is importing Groq’s team and deterministic inference approach into its platform, while keeping Groq formally independent via a non-exclusive license structure.
Groq’s LPUs (Language Processing Units) are optimized for low-latency, single-user interactions, where NVIDIA GPUs excel at high-throughput batch processing for thousands of concurrent users. The Groq LPU technology stack complements NVIDIA GPUs well, and I believe we should expect new NVIDIA chips based on this platform later in 2026.
Read more:
Google Tests 30-Minute Lecture Mode for NotebookLM
https://www.testingcatalog.com/exclusive-google-tests-30-minute-audio-lectures-on-notebooklm/

The News:
- Google is testing a “Lecture” format for NotebookLM Audio Overviews that generates 30-minute single-host monologues from uploaded documents. The feature targets students, researchers, and professionals who need extended audio explanations of dense source material.
- Lecture mode appears alongside existing formats including Deep Dive, Brief, Critique, and Debate in the Audio Overview format picker. When set to “Long” duration, the mode produces approximately 30 minutes of continuous narration delivered in a structured, academic style.
- The feature includes a language selector that allows lectures to be generated in multiple languages based on user settings. TestingCatalog generated a sample lecture from their own sources to demonstrate pacing and structure.
- The feature is not publicly available yet, and Google has not announced launch timing or confirmed final availability. Strings and UI references for the Lecture mode were discovered in a recent NotebookLM build.
My take: This is something I can see using myself when driving to work. Just pick a news topic you want to learn more about, feed it to NotebookLM and you will have a narrator guiding you through the topic in less than 30 minutes. Very much looking forward to this release! If you have time go check the preview on X.
Read more:
Poetiq Achieves 75% Accuracy on ARC-AGI-2 Benchmark Using GPT-5.2
https://x.com/poetiq_ai/status/2003546910427361402

The News:
- Poetiq, a six-person startup, achieved 75% accuracy on the ARC-AGI-2 public evaluation dataset using GPT-5.2 X-High as the base model, surpassing the human baseline of 60%.
- The system costs under $8 per problem, maintaining cost efficiency while improving performance by 15 percentage points over the previous state of the art.
- Poetiq uses a meta-system architecture that orchestrates existing large language models through iterative reasoning, self-audit, and refinement rather than training new models from scratch.
- The approach involves generating candidate solutions, critiquing them, and refining outputs through multiple LLM calls in a generate-criticize-refine loop.
- Based on Poetiq’s previous results with Gemini 3, where public scores of 65% translated to 54% on semi-private datasets, the new 75% public score could validate around 64% on semi-private data.
My take: This clearly shows what you can achieve with a well-orchestrated agentic system. OpenAI GPT-5.2 (High) already performs on par with the average human on the ARC-AGI-2 benchmark, but when performed with an orchestrated agentic solution such as Poetiq you get super-human performance. This is why I am saying we don’t really need much better models right now, we just need to start using the ones we have. The possibilities are enormous.
Read more:
- They did it again!!! Poetiq layered their meta-system onto GPT 5.2 X-High, and hit 75% on the ARC-AGI-2 public evals! : r/agi
- Poetiq on X: “We finally had a moment to run our system with GPT-5.2 X-High on ARC-AGI-2! Using the same Poetiq harness as before, we saw results as high as 75% at under $8 / problem using GPT-5.2 X-High on the full PUBLIC-EVAL dataset. This beats the previous SOTA by ~15 percentage points.” / X
OpenAI Hardens ChatGPT Atlas Against Prompt Injection
https://openai.com/index/hardening-atlas-against-prompt-injection/

The News:
- OpenAI released security updates for ChatGPT Atlas targeting prompt injection attacks, where malicious instructions embedded in web content can redirect the AI agent from user-intended actions.
- The company deployed an adversarially trained model and strengthened safeguards following internal automated red teaming that identified attack patterns not found in human testing or external analysis.
- OpenAI built an LLM-based automated attacker using reinforcement learning that tests the agent in a counterfactual simulator, proposing injections and refining approaches based on how the targeted agent responds.
- One attack discovered by the system involved a malicious email containing hidden instructions that caused Atlas to draft a resignation letter to the user’s CEO instead of an out-of-office message when the user requested the latter.
- OpenAI stated “prompt injection, much like scams and social engineering on the web, is unlikely to ever be fully ‘solved’” and that “agent mode expands the security threat surface”.
My take: Let that sentence sink in a while: “Prompt injection, much like scams and social engineering on the web, is unlikely to ever be fully ‘solved’. But we’re optimistic that a proactive, highly responsive rapid response loop can continue to materially reduce real-world risk over time” (from Continuously hardening ChatGPT Atlas against prompt injection attacks). I see a solid value from these AI powered browsers, but they will clearly stay as a usage-specific complementary browser rather than your main browser for a long time.
Read more:
Z.AI Releases GLM-4.7 Open-Source Coding Model

The News:
- Z.AI released GLM-4.7 on December 21, 2025, an open-source language model targeting agentic coding workflows. The model addresses multi-step coding tasks where developers need requirement comprehension, solution decomposition, and multi-technology stack integration.
- GLM-4.7 scores 73.8% on SWE-bench Verified, 84.9% on LiveCodeBench v6, and 66.7% on SWE-bench Multilingual. Terminal Bench 2.0 performance reached 41%, a 16.5% improvement over the previous GLM-4.6 version.
- The model introduces three thinking modes: Interleaved Thinking, Preserved Thinking, and Turn-level Thinking. These modes operate between coding actions and across conversation turns to maintain task consistency.
- Model weights are available on HuggingFace and ModelScope with support for vLLM and SGLang inference frameworks. The API offers 200K context length and 128K maximum output tokens.
- GLM-4.7 integrates with Claude Code, Kilo Code, Cline, Roo Code, and OpenCode. The GLM Coding Plan subscription costs $3/month, marketed as one-seventh the price of competing services with 3x usage quota.
My take: Benchmarks mean nothing when it comes to AI programming agents. The only reason models like Claude Sonnet manages so well on benchmarks is that it just pushes out enormous amounts of code until it manages to end up with something that runs. User feedback for GLM-4.7 has not been great either, so unless you have a specific reason to use it, I would not recommend using it for anything serious.
Read more: